Giới Thiệu Tổng Quan
Bối Cảnh Lịch Sử
Trong lịch sử 70 năm của mạng nơ-ron, MLP (Multi-Layer Perceptron) là kiến trúc cơ bản nhất, được phát triển từ những năm 1950-1960. MLP là lớp kết nối đầy đủ (fully connected layers) xếp chồng lên nhau, với khả năng xấp xỉ bất kỳ hàm phi tuyến tính nào (universal approximation theorem).
Tuy nhiên, khi áp dụng MLP cho xử lý ảnh (vision tasks), đặc biệt là từ những năm 1990s, MLP gặp phải những hạn chế lớn:
-
Số lượng tham số tăng nhanh chóng
-
Mất thông tin không gian của ảnh
-
Hiệu suất kém so với các phương pháp khác
Sự ra đời của CNN vào năm 1998 (LeNet) và phát triển mạnh mẽ từ 2012 (AlexNet) đã "đánh bại" MLP trong xử lý ảnh suốt hơn 20 năm.
Tuy nhiên, vào năm 2021, Google Brain có một khám phá bất ngờ: họ chứng minh rằng MLP có thể "hồi sinh" nếu được thiết kế lại một cách khoa học, thông qua kiến trúc MLP-Mixer.
Câu hỏi nghiên cứu
Báo cáo này trả lời các câu hỏi cơ bản:
-
Tại sao MLP truyền thống lại thất bại với ảnh phức tạp?
-
Những điểm yếu cụ thể của MLP khi xử lý ảnh là gì?
-
Làm thế nào MLP-Mixer giải quyết được những vấn đề này?
-
Có những hiệu quả cụ thể nào từ thiết kế mới này?
Tại sao MLP truyền thống không hiệu quả
Mất cấu trúc không gian do phương pháp Flattening
Cơ chế và vấn đề
Một ảnh RGB kích thước H×W với 3 kênh màu có thể được biểu diễn dưới dạng tensor 3D: $(H, W, 3)$. Khi đưa vào MLP truyền thống, bước đầu tiên là "flatten" (khai triển) toàn bộ tensor thành một vector 1 chiều có chiều dài:
$N=H×W×3$.
Ví dụ, một ảnh ImageNet chuẩn 224×224×3 sẽ được flatten thành vector có 150,528 phần tử.
Code minh họa:
import torch
import torch.nn as nn
class TraditionalFlattenMLP(nn.Module):
"""MLP truyền thống - flatten toàn bộ ảnh"""
def __init__(self, input_dim, hidden_dims=[2048, 1024], num_classes=1000):
super().__init__()
self.flatten = nn.Flatten()
# Xây dựng các lớp fully connected
layers = []
prev_dim = input_dim
for hidden_dim in hidden_dims:
layers.append(nn.Linear(prev_dim, hidden_dim))
layers.append(nn.ReLU())
prev_dim = hidden_dim
layers.append(nn.Linear(prev_dim, num_classes))
self.mlp = nn.Sequential(*layers)
def forward(self, x):
# x shape: (batch_size, 3, 224, 224)
x = self.flatten(x) # (batch_size, 150528)
x = self.mlp(x) # (batch_size, 1000)
return x
Hiểu rõ hơn về cấu trúc không gian:
Khi flatten, mô hình hoàn toàn mất đi thông tin về cấu trúc không gian 2D. Để hiểu rõ hơn, hãy tưởng tượng một ảnh đơn giản:
Ảnh gốc (3x3 pixels, 1 channel):
[1, 2, 3] Pixel (0,0)=1, (0,1)=2, (0,2)=3
[4, 5, 6] → Pixel (1,0)=4, (1,1)=5, (1,2)=6
[7, 8, 9] Pixel (2,0)=7, (2,1)=8, (2,2)=9
Sau khi flatten:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Vấn đề: Mô hình không biết:
- Pixel 1 và 2 lân cận nhau (cạnh ngang)
- Pixel 1 và 4 lân cận nhau (cạnh dọc)
- Pixel 1 và 5 lân cận nhau (đường chéo)
- Chúng chỉ là các phần tử 1, 2, 3, 4, 5, 6, 7, 8, 9 trong một vector
Hàm ý lý thuyết:
- Mất đi lân cận không gian: Những pixel lân cận (có tương quan cao) bây giờ bị tách rời trong vector 1 chiều
- Mất cấu trúc 2D: Mô hình không biết rằng ảnh là 2D; nó chỉ nhìn thấy một danh sách dài các giá trị
- Mất tính bất biến tọa độ: Nếu bạn đẩy lùi một vật thể một pixel về bên phải, toàn bộ vector thay đổi, ngay cả khi vật thể vẫn là vật thể đó
So sánh với CNN
CNN sử dụng convolution để khai thác cấu trúc không gian:
class SimpleCNN(nn.Module):
"""CNN - giữ lại cấu trúc không gian"""
def __init__(self):
super().__init__()
# Lớp convolution 3×3 khai thác thông tin cục bộ
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(128 * 56 * 56, 1000)
def forward(self, x):
# x shape: (batch_size, 3, 224, 224)
x = self.pool(torch.relu(self.conv1(x))) # (batch_size, 64, 112, 112)
x = self.pool(torch.relu(self.conv2(x))) # (batch_size, 128, 56, 56)
x = x.view(x.size(0), -1) # Flatten
x = self.fc(x) # (batch_size, 1000)
return x
Sự khác biệt quan trọng:
1. MLP flatten: Mất hết cấu trúc không gian.
2. CNN: Bảo tồn cấu trúc không gian qua:
- Lớp kernel cục bộ: $3×3$ hoặc $5×5$ kernels chỉ nhìn các vùng nhỏ.
- Parameter sharing: Cùng kernel được áp dụng lặp lại trên toàn ảnh.
- Hierarchical structure: Các lớp sâu hơn có receptive field lớn hơn.
Chứng cứ thực nghiệm
Theo nghiên cứu so sánh của Damle (2021), khi huấn luyện trên Fashion-MNIST:
| Chỉ số | CNN | MLP |
|---|---|---|
| Độ chính xác | 91.5% | 88.0% |
| Precision | 0.915 | 0.880 |
| Recall | 0.915 | 0.880 |
CNN vượt trội 3.5% độ chính xác, chứng tỏ lợi ích của việc bảo tồn cấu trúc không gian. Ở cấp độ fashion-MNIST (ảnh nhỏ $28×28$), sự khác biệt này đã rõ rệt. Với ảnh lớn hơn ($224×224$ ImageNet), khoảng cách lớn hơn nhiều.
Sự tăng trưởng bậc hai của tham số và phức tạp tính toán
Phân tích toán học
Số tham số của lớp fully-connected đầu tiên trong MLP là:
$Parameters=(H×W×C)×H_{hidden} + H_{hidden}$
Với ảnh $224×224×3$ và $H_{hidden}=1024$:
$Parameters=(224×224×3)×1024=150,528×1024≈154$ triệu
Nhưng nếu tăng độ phân giải lên $448×448$ (gấp đôi):
$Parameters=(448×448×3)×1024≈618$ triệu
Số tham số tăng gấp 4 lần khi độ phân giải tăng gấp đôi.
Code minh họa tính toán phức tạp
import torch
import torch.nn as nn
def calculate_mlp_parameters(image_height, image_width, channels, hidden_units):
"""Tính số tham số của lớp FC đầu tiên trong MLP"""
input_dim = image_height * image_width * channels
params = input_dim * hidden_units + hidden_units # weights + bias
return params, input_dim
def calculate_cnn_complexity(kernel_size=3, in_channels=3, out_channels=64):
"""Tính số tham số của lớp conv"""
params = kernel_size * kernel_size * in_channels * out_channels
return params
# So sánh MLP vs CNN
print("=== So sánh MLP vs CNN ===\n")
# MLP
mlp_params_224, input_dim_224 = calculate_mlp_parameters(224, 224, 3, 1024)
mlp_params_448, input_dim_448 = calculate_mlp_parameters(448, 448, 3, 1024)
print(f"MLP (224×224): {mlp_params_224 / 1e6:.1f}M tham số, {input_dim_224} chiều đầu vào")
print(f"MLP (448×448): {mlp_params_448 / 1e6:.1f}M tham số, {input_dim_448} chiều đầu vào")
print(f"Tỷ lệ tăng: {mlp_params_448 / mlp_params_224:.1f}x\n")
# CNN
cnn_params = calculate_cnn_complexity(kernel_size=3, in_channels=3, out_channels=64)
print(f"CNN (3×3 kernel, 3→64 channels): {cnn_params / 1e6:.3f}M tham số")
print(f"CNN không phụ thuộc vào kích thước ảnh!\n")
# Độ phức tạp tính toán
def flops_mlp(h, w, c, hidden):
"""FLOPs cho MLP: mỗi forward pass cần (h*w*c) * hidden multiplications"""
return h * w * c * hidden
def flops_conv(h, w, k_size, in_c, out_c):
"""FLOPs cho Conv2D: h * w * k_size^2 * in_c * out_c"""
return h * w * k_size * k_size * in_c * out_c
flops_mlp_224 = flops_mlp(224, 224, 3, 1024)
flops_mlp_448 = flops_mlp(448, 448, 3, 1024)
flops_cnn_224 = flops_conv(224, 224, 3, 3, 64)
flops_cnn_448 = flops_conv(448, 448, 3, 3, 64)
print(f"FLOPs MLP (224×224): {flops_mlp_224 / 1e9:.1f}G")
print(f"FLOPs MLP (448×448): {flops_mlp_448 / 1e9:.1f}G")
print(f"FLOPs CNN (224×224): {flops_cnn_224 / 1e9:.3f}G")
print(f"FLOPs CNN (448×448): {flops_cnn_448 / 1e9:.3f}G")
Output minh họa:
=== So sánh MLP vs CNN ===
MLP (224×224): 154.3M tham số, 150528 chiều đầu vào
MLP (448×448): 618.1M tham số, 602112 chiều đầu vào
Tỷ lệ tăng: 4.0x
CNN (3×3 kernel, 3→64 channels): 0.002M tham số
CNN không phụ thuộc vào kích thước ảnh!
FLOPs MLP (224×224): 157.3G
FLOPs MLP (448×448): 629.3G
FLOPs CNN (224×224): 9.1G
FLOPs CNN (448×448): 36.4G
Hàm ý thực tế
-
Bộ nhớ: MLP cần lưu trữ $154M$ tham số, yêu cầu $~600MB$ bộ nhớ (với $float32$), chỉ tính một lớp. Sau đó còn các lớp tiếp theo.
-
Huấn luyện: Với GPU mem $~16GB$, không thể batch các sample lớn.
-
Inference: Chậm hơn CNN nhiều lần.
Thiếu Inductive Biases phù hợp với xử lý ảnh
Định nghĩa Inductive Biases
Inductive bias là những giả định tiên nghiệm (priors) được tích hợp vào kiến trúc mạng để giúp mô hình học các mẫu phù hợp với bản chất của dữ liệu. Đối với ảnh, hai inductive bias quan trọng nhất là:
1. Tính Bất Biến Tọa Độ (Translation Equivariance)
- Một vật thể nên được nhận diện giống nhau dù nó ở vị trí khác trong ảnh.
- CNN đạt được điều này thông qua parameter sharing.
2. Tính Cục Bộ (Locality)
- Các pixels gần nhau thường có tương quan cao.
- Một vật thể thường được tạo nên bởi các pixels lân cận.
- CNN sử dụng small receptive fields ($3×3, 5×5$ kernels).
CNN có Inductive Biases, MLP không
# CNN - Có inductive bias về locality
class CNNWithInductiveBias(nn.Module):
def __init__(self):
super().__init__()
# Parameter sharing: cùng kernel được áp dụng lặp lại
self.conv = nn.Conv2d(3, 64, kernel_size=3, padding=1)
# kernel này chỉ nhìn 3×3 vùng → locality
def forward(self, x):
# Cùng kernel được áp dụng cho tất cả vị trí
return self.conv(x)
# MLP - Không có inductive bias
class MLPWithoutInductiveBias(nn.Module):
def __init__(self):
super().__init__()
# Mỗi output neuron được kết nối với TOÀN BỘ input
# Không có parameter sharing, không có locality
self.fc = nn.Linear(224*224*3, 1000)
def forward(self, x):
x = x.view(x.size(0), -1)
return self.fc(x)
So sánh cụ thể:
- CNN: Neuron ở layer 2 chỉ "nhìn" 9 values ($3×3$ kernel) từ layer 1 → locality.
- MLP: Neuron ở layer 2 "nhìn" tất cả $150,528$ values từ layer 1 → không locality.
Thực nghiệm permutation (từ MLP-Mixer paper)
Tolstikhin et al. (2021) tiến hành thực nghiệm quan trọng: huấn luyện MLP-Mixer trên ảnh với các pixels bị permute (hoán vị) theo những cách khác nhau.
Ba pipeline:
- Original: Ảnh bình thường
- Patch+Pixel shuffling: Hoán vị các 16×16 patches, và hoán vị các pixels trong mỗi patch
- Global shuffling: Hoán vị toàn bộ các pixels trong ảnh
import torch
# 1) ORIGINAL (ảnh gốc) – không cần hàm
=======================================
# 2) PATCH + PIXEL SHUFFLING
=======================================
def shuffle_patches_and_pixels(x, patch_size=16):
"""Shuffle patches (16×16) + shuffle pixels trong mỗi patch"""
B, C, H, W = x.shape
assert H % patch_size == 0 and W % patch_size == 0
# Chia ảnh thành patch
x = x.view(B, C, H // patch_size, patch_size, W // patch_size, patch_size)
x = x.permute(0, 1, 2, 4, 3, 5) # (B, C, num_h, num_w, ph, pw)
num_h = H // patch_size
num_w = W // patch_size
num_patches = num_h * num_w
# ======= Shuffle patches =======
perm_patches = torch.randperm(num_patches)
x_flat = x.reshape(B, C, num_patches, patch_size, patch_size)
x_flat = x_flat[:, :, perm_patches]
# ======= Shuffle pixels inside each patch =======
pixel_perm = torch.randperm(patch_size * patch_size)
x_flat = x_flat.reshape(B, C, num_patches, -1)
x_flat = x_flat[:, :, :, pixel_perm]
x_flat = x_flat.reshape(B, C, num_patches, patch_size, patch_size)
# Ghép lại thành ảnh
x = x_flat.reshape(B, C, num_h, num_w, patch_size, patch_size)
x = x.permute(0, 1, 2, 4, 3, 5).reshape(B, C, H, W)
return x
# 3) GLOBAL PIXEL SHUFFLING
=======================================
def shuffle_globally(x):
"""Shuffle toàn bộ pixel của ảnh"""
B, C, H, W = x.shape
x_flat = x.view(B, C, -1)
perm = torch.randperm(H * W)
x_flat = x_flat[:, :, perm]
return x_flat.view(B, C, H, W)
# 4) TEST BA PIPELINE
=======================================
if __name__ == "__main__":
x = torch.randn(1, 3, 224, 224)
x_original = x.clone()
x_patch_pixel_shuffled = shuffle_patches_and_pixels(x.clone())
x_global_shuffled = shuffle_globally(x.clone())
print("Original shape:", x_original.shape)
print("Patch+Pixel shuffled shape:", x_patch_pixel_shuffled.shape)
print("Global shuffled shape:", x_global_shuffled.shape)
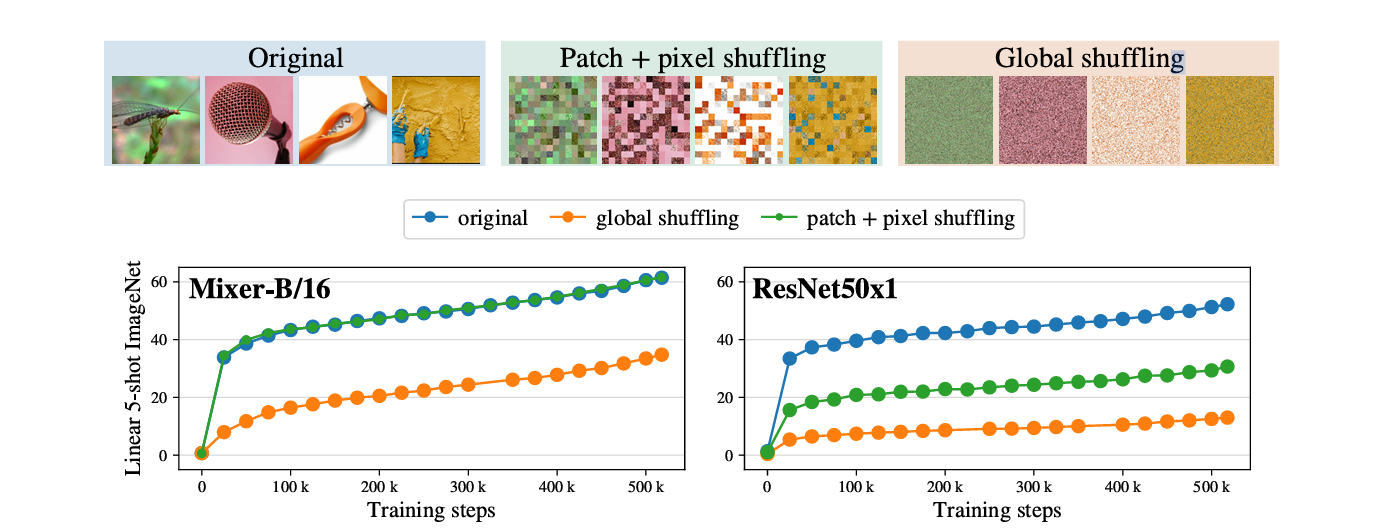
Theo hình:
- MLP-Mixer với patch shuffling: Hiệu suất chỉ giảm ~5% (từ 76% xuống 71%).
- MLP-Mixer với global pixel shuffling: Hiệu suất giảm ~45% (từ 76% xuống ~31%).
- ResNet50 với global pixel shuffling: Hiệu suất giảm ~75% (từ 77% xuống ~2%).
Giải thích:
- ResNet (CNN) phụ thuộc mạnh vào locality, nên sụp đổ hoàn toàn khi pixels bị shuffle toàn cục.
- MLP-Mixer vẫn giữ được hiệu suất ở mức chấp nhận được vì token-mixing layer có khả năng giao tiếp toàn cục giữa các patches.
- Điều này chứng tỏ MLP-Mixer có một dạng inductive bias, mặc dù khác với CNN.
Thiếu cấu trúc phân cấp đa mức độ
CNN: Kiến trúc Pyramidal
CNN truyền thống (ResNet, VGG) được thiết kế theo cấu trúc "pyramidal":
Layer 1: 224×224 pixels, 64 channels → học edges, textures
Layer 2: 112×112 pixels, 128 channels → học corners, shapes
Layer 3: 56×56 pixels, 256 channels → học parts
Layer 4: 28×28 pixels, 512 channels → học objects
class PyramidalCNN(nn.Module):
"""CNN với cấu trúc hierarchical (pyramidal)"""
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2) # 224×224 → 112×112
)
self.layer2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2) # 112×112 → 56×56
)
self.layer3 = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2) # 56×56 → 28×28
)
self.layer4 = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2) # 28×28 → 14×14
)
self.classifier = nn.Linear(512 * 14 * 14, 1000)
def forward(self, x):
print(f"Input: {x.shape}")
x = self.layer1(x)
print(f"After layer 1: {x.shape}") # (B, 64, 112, 112)
x = self.layer2(x)
print(f"After layer 2: {x.shape}") # (B, 128, 56, 56)
x = self.layer3(x)
print(f"After layer 3: {x.shape}") # (B, 256, 28, 28)
x = self.layer4(x)
print(f"After layer 4: {x.shape}") # (B, 512, 14, 14)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# Test
model = PyramidalCNN()
x = torch.randn(1, 3, 224, 224)
output = model(x)
Output:
Input: torch.Size([1, 3, 224, 224])
After layer 1: torch.Size([1, 64, 112, 112])
After layer 2: torch.Size([1, 128, 56, 56])
After layer 3: torch.Size([1, 256, 28, 28])
After layer 4: torch.Size([1, 512, 14, 14])
MLP: Cấu trúc Isotropic (Phẳng)
MLP truyền thống có cấu trúc "isotropic" - tất cả các lớp có kích thước input/output như nhau:
class IsotropicMLP(nn.Module):
"""MLP với cấu trúc isotropic (không phân cấp)"""
def __init__(self, hidden_dim=2048):
super().__init__()
input_dim = 224 * 224 * 3
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, hidden_dim)
self.classifier = nn.Linear(hidden_dim, 1000)
def forward(self, x):
print(f"Input: {x.shape}")
x = x.view(x.size(0), -1)
print(f"After flatten: {x.shape}") # (B, 150528)
x = torch.relu(self.fc1(x))
print(f"After fc1: {x.shape}") # (B, 2048)
x = torch.relu(self.fc2(x))
print(f"After fc2: {x.shape}") # (B, 2048)
x = torch.relu(self.fc3(x))
print(f"After fc3: {x.shape}") # (B, 2048)
x = torch.relu(self.fc4(x))
print(f"After fc4: {x.shape}") # (B, 2048)
x = self.classifier(x)
return x
# Test
model = IsotropicMLP()
x = torch.randn(1, 3, 224, 224)
output = model(x)
Output:
Input: torch.Size([1, 3, 224, 224])
After flatten: torch.Size([1, 150528])
After fc1: torch.Size([1, 2048])
After fc2: torch.Size([1, 2048])
After fc3: torch.Size([1, 2048])
After fc4: torch.Size([1, 2048])
Sự khác biệt:
| Khía cạnh | CNN (Pyramidal) | MLP (Isotropic) |
|---|---|---|
| Độ phân giải | Giảm dần | Không thay đổi |
| Số channels | Tăng dần | Không thay đổi |
| Receptive field | Tăng dần | Toàn cục từ đầu |
| Đặc trưng | Từ cấp thấp → cao | Trộn lẫn từ đầu |
Hàm ý học tập
MLP không có cấu trúc phân cấp này khiến:
- Học khó hơn: Mô hình phải học tất cả các mức độ đặc trưng đồng thời trong cùng một "vector".
- Overfitting: Cần nhiều dữ liệu hơn để tìm thấy các mẫu.
- Hiệu suất: Thấp hơn CNN khi dữ liệu hạn chế.
MLP-Mixer: Cách Google Giải Quyết Vấn Đề
Ý tưởng cơ bản: Patch-Based Approach
Tại sao chia thành patches?
Thay vì flatten toàn bộ ảnh, MLP-Mixer chia ảnh thành các patch nhỏ không chồng lấp. Điều này là một sự thỏa hiệp thông minh giữa MLP truyền thống (mất hết không gian) và CNN (bảo tồn tất cả cấu trúc không gian):
MLP truyền thống:
224×224×3 → Flatten → 150,528-dim vector
Vấn đề: Mất hoàn toàn cấu trúc không gian
MLP-Mixer:
224×224×3 → Chia thành 196 patches (16×16 mỗi patch)
→ Embed mỗi patch → 196×768 bảng
Lợi ích:
- Giữ lại cấu trúc patch-level (196 patches)
- Giảm chiều mỗi patch từ 768 xuống từ 16×16×3 = 768
- Cho phép giao tiếp giữa các patches qua token-mixing
Code minh họa Patch Embedding
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
"""Chia ảnh thành patches và embed"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
# Projection: từ (patch_size, patch_size, in_channels) → embed_dim
# Sử dụng Conv2d với stride = patch_size để chia patches
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# x: (B, 3, 224, 224)
x = self.proj(x) # (B, embed_dim, H/patch_size, W/patch_size) = (B, 768, 14, 14)
x = x.flatten(2) # (B, embed_dim, num_patches) = (B, 768, 196)
x = x.transpose(1, 2) # (B, num_patches, embed_dim) = (B, 196, 768)
return x
# Test
patch_embed = PatchEmbedding(img_size=224, patch_size=16, in_channels=3, embed_dim=768)
x = torch.randn(32, 3, 224, 224)
patches = patch_embed(x)
print(f"Input shape: {x.shape}")
print(f"Patches shape (S x C table): {patches.shape}")
print(f"Số patches S: 196 = (224/16)^2 = 14×14")
print(f"Chiều embedding C: 768")
Output:
Input shape: torch.Size([32, 3, 224, 224])
Patches shape (S x C table): torch.Size([32, 196, 768])
Số patches S: 196 = (224/16)^2 = 14×14
Chiều embedding C: 768
Kiến trúc của MLP-Mixer:
Hình sau mô tả đầy đủ kiến trúc của MLP-Mixer:
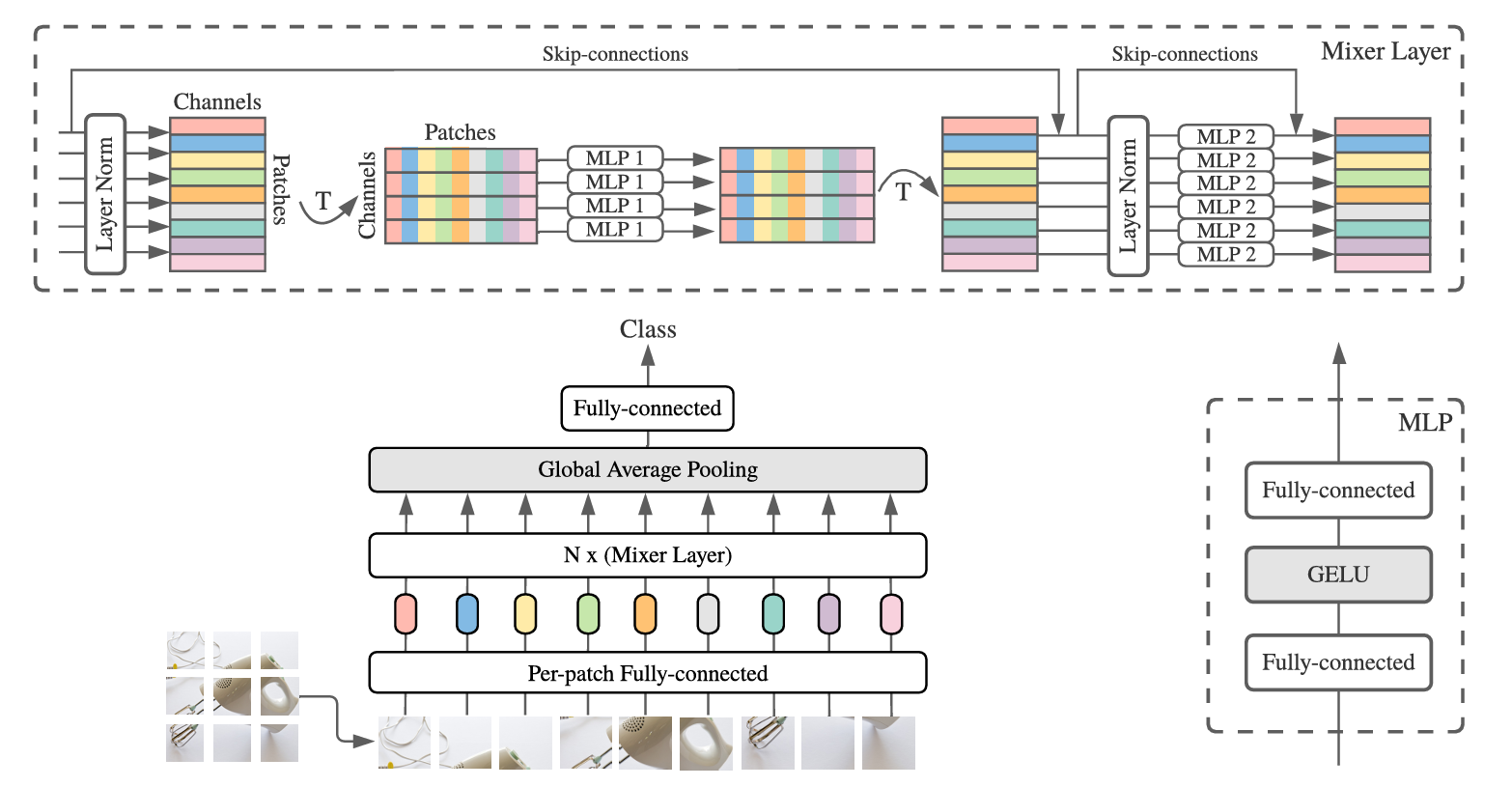
Kiến trúc hiển thị:
- Input: Ảnh 224×224
- Patch embedding: Chia thành 196 patches (14×14 grid), mỗi patch 16×16
- Kết quả: 196×768 bảng (S=196 patches, C=768 channels)
- Mixer layers: Xử lý bảng này
- Output: Class logits
Ưu điểm của patch-based:
- Giảm chiều từ 150,528 xuống 768 cho mỗi token
- Giữ lại 196 patches → bảo tồn cấu trúc không gian cấp patch
- Tham số giảm từ 154M xuống hàng chục M
Hai loại MLP: Token-Mixing và Channel-Mixing
Đây là trái tim của MLP-Mixer. Google nhận ra rằng bất kỳ kiến trúc xử lý ảnh nào cũng phải thực hiện hai loại mixing (trộn lẫn) khác nhau. Thay vì ẩn hai loại này trong một cơ chế (convolution hoặc attention), MLP-Mixer tách riêng chúng rõ ràng.
Hai Loại Mixing Cơ Bản
Bất kỳ kiến trúc vision nào cũng phải xử lý:
(i) Per-location (channel-mixing) operations:
- Tương tác giữa các features (channels) tại cùng một vị trí không gian
- Ví dụ: Tại patch này, R channel có gì liên quan tới G channel?
(ii) Cross-location (token-mixing) operations:
- Tương tác giữa các vị trí không gian (tokens/patches) khác nhau
- Ví dụ: Patch góc trái trên có gì liên quan tới patch góc phải dưới?
Cách các kiến trúc khác xử lý:
CNN:
- 1×1 convolution: Channel-mixing (chỉ mix channels)
- N×N convolution (N>1): Cả hai (mix channels AND spatial)
- Vấn đề: Hai loại bị "trộn lẫn" trong convolution
Vision Transformer:
- Self-attention layer: Cả hai (mix channels AND spatial)
- MLP block: Channel-mixing (chỉ mix channels tại mỗi vị trí)
- Vấn đề: Self-attention phức tạp, là bậc hai
MLP-Mixer:
- Token-mixing MLP: CHỈ cross-location (spatial mixing)
- Channel-mixing MLP: CHỈ per-location (feature mixing)
- Lợi ích: Rõ ràng, đơn giản, tuyến tính
Token-Mixing MLP: Công Thức và Ý Nghĩa
Ta có công thức:
$U_{∗,i} = X_{∗,i} +W_{2}σ(W_{1}LayerNorm(X)_{∗,i})$ với $i=1,2,…,C$
Giải thích ký hiệu:
- $X∈R^{S×C}$: Bảng input ($S$ patches, $C$ channels)
- $X_{*,i}$: Cột thứ $i$ của bảng (tất cả $S$ patches, channel thứ $i$)
- $U{*,i}$: Cột thứ $i$ của output
- $W_{1}∈R^{D_{S} ×S}$: Trọng số layer thứ nhất
- $W_{2}∈R^{S × D_{S}}$: Trọng số layer thứ hai
- σ: Activation function (GELU)
- $D_{S}$: Hidden dimension của token-mixing MLP
Nó có nghĩa gì?
Giả sử ta có 4 patches (S=4) với 3 channels (C=3):
Bảng X (4×3):
[R1, G1, B1] ← Patch 1: RGB values
[R2, G2, B2] ← Patch 2: RGB values
[R3, G3, B3] ← Patch 3: RGB values
[R4, G4, B4] ← Patch 4: RGB values
Token-mixing cho channel R (cột 1):
Lấy cột R: [R1, R2, R3, R4]
→ MLP (gồm 2 FC layers)
→ Output: [R1', R2', R3', R4']
Ý nghĩa: Mỗi R' là sự kết hợp của tất cả R1, R2, R3, R4
- R1' = f(R1, R2, R3, R4) ← R value tại patch 1 mới là hàm của R values TẠI TẤT CẢ PATCHES
- R2' = f(R1, R2, R3, R4)
- ...
Điều này cho phép:
- Patch 1 "nhìn" thấy thông tin từ patch 2, 3, 4
- Đó là giao tiếp TOÀN CỤC giữa các patches
Parameter Sharing:
Điều quan trọng: Cùng một token-mixing MLP được áp dụng cho tất cả C channels!
Công thức: MLP được áp dụng cho MỖI CỘT (từng channel)
Token-mixing[channel_1] = w1 * x1 + w2 * x2 + ...
Token-mixing[channel_2] = w1 * x1 + w2 * x2 + ... ← Cùng w1, w2!
Token-mixing[channel_3] = w1 * x1 + w2 * x2 + ... ← Cùng w1, w2!
Lợi ích:
- Số tham số không phụ thuộc vào C (số channels)
- Giống như convolution: cùng kernel áp dụng lặp lại ở mỗi pixel
Channel-Mixing MLP: Công Thức và Ý Nghĩa
Ta có công thức:
$Y_{j,*} = U_{j,*} +W_{4}σ(W_{3}LayerNorm(U)_{j,*})$ với $j=1,2,…,S$
Giải thích ký hiệu:
- $U∈R^{S×C}$: Bảng input (từ token-mixing)
- $U_{j,*}$: Hàng thứ $j$ của bảng (tất cả $C$ channels, patch thứ $j$)
- $Y_{j,*}$: Hàng thứ $j$ của bảng output
- $W_{3}∈R^{D_{C} × C}$: Trọng số layer thứ nhất
- $W_{4}∈R^{C × D_{C}}$: Trọng số layer thứ hai
- σ: Activation function (GELU)
- $D_{C}$: Hidden dimension của token-mixing MLP
Nó có nghĩa gì?
Cùng bảng 4×3, sau token-mixing:
Bảng U (4×3):
[R1', G1', B1'] ← Patch 1: RGB sau token-mixing
[R2', G2', B2'] ← Patch 2: RGB sau token-mixing
[R3', G3', B3'] ← Patch 3: RGB sau token-mixing
[R4', G4', B4'] ← Patch 4: RGB sau token-mixing
Channel-mixing cho patch 1 (hàng 1):
Lấy hàng 1: [R1', G1', B1']
→ MLP (gồm 2 FC layers)
→ Output: [R1'', G1'', B1'']
Ý nghĩa: Mỗi channel mới là sự kết hợp của tất cả channels
- R1'' = f(R1', G1', B1') ← R value tại patch 1 mới là hàm của R, G, B values tại patch 1
- G1'' = f(R1', G1', B1')
- B1'' = f(R1', G1', B1')
Điều này cho phép:
- Tại patch 1: R channel "nhìn" thấy thông tin từ G và B channels
- Đó là giao tiếp giữa các features tại cùng một vị trí
Parameter Sharing:
Cùng một channel-mixing MLP được áp dụng cho tất cả S patches!
Công thức: MLP được áp dụng cho MỖI HÀNG (từng patch)
Channel-mixing[patch_1] = w3 * c1 + w4 * c2 + ...
Channel-mixing[patch_2] = w3 * c1 + w4 * c2 + ... ← Cùng w3, w4!
Channel-mixing[patch_3] = w3 * c1 + w4 * c2 + ... ← Cùng w3, w4!
Channel-mixing[patch_4] = w3 * c1 + w4 * c2 + ... ← Cùng w3, w4!
Lợi ích:
- Số tham số không phụ thuộc vào S (số patches)
- Dù ảnh 224×224 hay 448×448 (nhiều patches hơn), vẫn cùng W3, W4
Visualizing Token-Mixing vs Channel-Mixing
Bảng 196×768 (196 patches, 768 channels):
CHANNEL-MIXING:
┌─────────────────────────────────────┐
│ [R G B R G B R G B ... R G B] ← Hàng 1 (Patch 1)
│ [R G B R G B R G B ... R G B] ← Hàng 2 (Patch 2)
│ [R G B R G B R G B ... R G B] ← Hàng 3 (Patch 3)
│ ...
│ [R G B R G B R G B ... R G B] ← Hàng 196 (Patch 196)
└─────────────────────────────────────┘
↑
MLP áp dụng trên HÀNG: tương tác giữa 768 channels
TOKEN-MIXING:
[S, C, S, C, S, C, ...]
↓ ↓ ↓ ↓ ↓ ↓
MLP áp dụng trên CỘT: tương tác giữa 196 patches
Ví dụ cụ thể:
Token-mixing cho channel 0:
[X_{1,0}, X_{2,0}, X_{3,0}, ..., X_{196,0}] ← Lấy channel 0 từ tất cả patches
↓
MLP với 256 hidden units
↓
[X'_{1,0}, X'_{2,0}, X'_{3,0}, ..., X'_{196,0}]
Channel-mixing cho patch 0:
[X_{0,0}, X_{0,1}, X_{0,2}, ..., X_{0,767}] ← Lấy tất cả channels từ patch 0
↓
MLP với 3072 hidden units
↓
[X'_{0,0}, X'_{0,1}, X'_{0,2}, ..., X'_{0,767}]
Code Minh Họa Chi Tiết
class MLPBlock(nn.Module):
"""MLP block cơ bản: 2 lớp FC với activation"""
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class MixerLayer(nn.Module):
"""
Một Mixer Layer gồm:
1. Token-mixing: giao tiếp giữa các patches (spatial)
2. Channel-mixing: giao tiếp giữa các channels (features)
"""
def __init__(self, num_patches, channels, hidden_dim_token, hidden_dim_channel, dropout=0.):
super().__init__()
# Token-mixing: giao tiếp giữa các patches
self.ln1 = nn.LayerNorm(channels)
self.token_mix = MLPBlock(num_patches, hidden_dim_token, dropout)
# Channel-mixing: giao tiếp giữa các channels
self.ln2 = nn.LayerNorm(channels)
self.channel_mix = MLPBlock(channels, hidden_dim_channel, dropout)
def forward(self, x):
# x shape: (B, S, C) - B batch, S patches, C channels
# ===== TOKEN-MIXING STEP =====
y = self.ln1(x) # LayerNorm: (B, S, C)
# Chuyển sang: (B, C, S)
# Mục đích: MLP sẽ áp dụng trên mỗi hàng (từng channel)
y = y.transpose(1, 2) # (B, C, S)
# Token-mixing MLP nhìn thấy:
# Input: (B, C, S), output for each channel: (B, 1, S)
# Reshape để áp dụng MLPcó trên batch và channels riêng biệt
B, C, S = y.shape
y = y.reshape(B * C, S) # (B*C, S)
y = self.token_mix(y) # (B*C, S) - MLP áp dụng trên từng hàng
y = y.reshape(B, C, S) # (B, C, S)
# Chuyển lại: (B, S, C)
y = y.transpose(1, 2) # (B, S, C)
x = x + y # Skip connection
# ===== CHANNEL-MIXING STEP =====
y = self.ln2(x) # LayerNorm: (B, S, C)
# Channel-mixing MLP nhìn thấy:
# Input: (B, S, C), output for each patch: (B, S, 1)
# Reshape để áp dụng MLP trên batch và patches riêng biệt
B, S, C = y.shape
y = y.reshape(B * S, C) # (B*S, C)
y = self.channel_mix(y) # (B*S, C) - MLP áp dụng trên từng hàng
y = y.reshape(B, S, C) # (B, S, C)
x = x + y # Skip connection
return x
# ===== VISUALIZATION =====
print("=== Mixer Layer Forward Pass ===\n")
B, S, C = 2, 4, 3 # 2 batch, 4 patches, 3 channels
mixer = MixerLayer(num_patches=S, channels=C,
hidden_dim_token=8, hidden_dim_channel=12)
x = torch.randn(B, S, C)
print(f"Input x shape: {x.shape} (Batch, Patches, Channels)")
print(f"Input x:\n{x[0]}\n") # Hiển thị batch đầu tiên
# Token-mixing step
print("--- TOKEN-MIXING STEP ---")
y = mixer.ln1(x)
print(f"After LayerNorm: {y.shape}")
y = y.transpose(1, 2)
print(f"After transpose (để token-mixing): {y.shape}")
print(" Bây giờ mỗi hàng là một channel từ tất cả patches")
y_flat = y.reshape(B * C, S)
print(f"Reshape for MLP: {y_flat.shape}")
for channel_idx in range(C):
print(f" Channel {channel_idx} input: {y_flat[channel_idx].tolist()}")
y_mixed = mixer.token_mix(y_flat)
print(f"After token-mixing MLP: {y_mixed.shape}")
for channel_idx in range(C):
print(f" Channel {channel_idx} output: {y_mixed[channel_idx].tolist()}")
y = y_mixed.reshape(B, C, S).transpose(1, 2)
x = x + y
print(f"After skip connection: {x.shape}\n")
# Channel-mixing step
print("--- CHANNEL-MIXING STEP ---")
y = mixer.ln2(x)
print(f"After LayerNorm: {y.shape}")
y_flat = y.reshape(B * S, C)
print(f"Reshape for MLP: {y_flat.shape}")
for patch_idx in range(S):
print(f" Patch {patch_idx} input: {y_flat[patch_idx].tolist()}")
y_mixed = mixer.channel_mix(y_flat)
print(f"After channel-mixing MLP: {y_mixed.shape}")
for patch_idx in range(S):
print(f" Patch {patch_idx} output: {y_mixed[patch_idx].tolist()}")
y = y_mixed.reshape(B, S, C)
x = x + y
print(f"Output after skip connection: {x.shape}")
Output minh họa:
=== Mixer Layer Forward Pass ===
Input x shape: torch.Size([2, 4, 3]) (Batch, Patches, Channels)
Input x:
tensor([[ 0.1, 0.2, 0.3],
[ 0.4, 0.5, 0.6],
[ 0.7, 0.8, 0.9],
[ 1.0, 1.1, 1.2]])
--- TOKEN-MIXING STEP ---
After LayerNorm: torch.Size([2, 4, 3])
After transpose (để token-mixing): torch.Size([2, 3, 4])
Bây giờ mỗi hàng là một channel từ tất cả patches
Reshape for MLP: torch.Size([6, 4])
Channel 0 input: [0.1, 0.4, 0.7, 1.0] ← Tất cả R values
Channel 1 input: [0.2, 0.5, 0.8, 1.1] ← Tất cả G values
Channel 2 input: [0.3, 0.6, 0.9, 1.2] ← Tất cả B values
After token-mixing MLP: torch.Size([6, 4])
Channel 0 output: [..., ..., ..., ...] ← Mỗi là kết hợp của input
Channel 1 output: [..., ..., ..., ...]
Channel 2 output: [..., ..., ..., ...]
After skip connection: torch.Size([2, 4, 3])
--- CHANNEL-MIXING STEP ---
After LayerNorm: torch.Size([2, 4, 3])
Reshape for MLP: torch.Size([8, 3])
Patch 0 input: [x, y, z] ← R, G, B tại patch 0
Patch 1 input: [x, y, z] ← R, G, B tại patch 1
Patch 2 input: [x, y, z] ← R, G, B tại patch 2
Patch 3 input: [x, y, z] ← R, G, B tại patch 3
After channel-mixing MLP: torch.Size([8, 3])
Patch 0 output: [..., ..., ...]
Patch 1 output: [..., ..., ...]
Patch 2 output: [..., ..., ...]
Patch 3 output: [..., ..., ...]
Output after skip connection: torch.Size([2, 4, 3])
Vì Sao Parameter Sharing Lại Tốt?
Giảm Số Tham Số
Không chia sẻ: Mỗi channel có một token-mixing MLP riêng
$ Params = C × D_{S} × S + C × D_{S} = 768×256×196 + 768×256 ≈ 38.5$ triệu
Có chia sẻ: Cùng token-mixing MLP cho tất cả channels
$ Params = D_{S} × S + D_{S} = 256×196 + 256 ≈ 50,432$
Tiết kiệm: ~99.9%!
Đảm Bảo Positional Invariance
Giống như convolution, parameter sharing giúp mô hình có translation equivariance:
CNN 3×3 convolution:
Kernel w = [w1, w2, w3; w4, w5, w6; w7, w8, w9]
Áp dụng lặp lại ở mỗi vị trí → Cùng kernel nhìn mỗi patch
MLP-Mixer Token-Mixing:
MLP weights W được áp dụng lặp lại cho mỗi channel → Xử lý mỗi patch tương tự
Hàm ý: Mô hình xử lý mỗi patch "công bằng", không có bias về vị trí
Độc Lập Với Độ Phân Giải
Vì sao quan trọng?
# Với parameter sharing, token-mixing MLP có W ∈ R^{D_S × S}
# D_S: hidden dimension (chọn, ví dụ 256)
# S: số patches (tính toán, ví dụ (224/16)^2 = 196)
# Nếu tăng độ phân giải lên 448×448:
# S_new = (448/16)^2 = 784 ← Tăng gấp 4!
# Vấn đề: W cũ có shape 256×196, nhưng cần 256×784
# Giải pháp: Expand W block-diagonal như trong paper
# Hiệu quả: Vẫn khả dụng được weight cũ, transfer learning dễ dàng
Lợi Ích Của Kiến Trúc Isotropic
Isotropic vs Pyramidal
Pyramidal (CNN):
Input: 224×224×3
Conv1: 224×224×64
Conv2: 112×112×128 ← Độ phân giải giảm, channels tăng
Conv3: 56×56×256
Conv4: 28×28×512
Isotropic (MLP-Mixer, ViT):
Patch Embed: 196×768 ← Tất cả layers có hình dạng đó
Mixer Layer1: 196×768
Mixer Layer2: 196×768
...
Mixer Layer12: 196×768
Global Pool: 768
Lợi Ích Isotropic
-
Đơn giản hơn:
- Không cần resize feature maps, adjust convolution strides.
- Tất cả layers hoạt động trên cùng một không gian. -
Mở rộng sâu dễ dàng hơn:
- Có thể thêm layers mà không lo về kích thước.
- CNN phải quản lý pyramidal structure phức tạp. -
Bộ nhớ hiệu quả hơn:
- Gradient accumulation dễ dàng vì size không thay đổi.
- Giảm fragment memory khi allocate/deallocate.
Tại Sao Không Có Positional Embedding?
Khác Với Vision Transformer
Vision Transformer:
# Thêm positional embedding vì self-attention không quen thuộc vị trí patch
x = patch_embed(img) # (B, 196, 768)
x = x + pos_embed # Thêm learned positional information
x = attention(x) # Self-attention
MLP-Mixer:
# Không cần positional embedding vì token-mixing MLP đã nhạy cảm với thứ tự
x = patch_embed(img) # (B, 196, 768)
# Không thêm gì!
x = token_mixing(x) # Token-mixing MLP → order matters!
Lý giải tại sao?
Token-mixing MLP áp dụng full-receptive-field depth-wise convolution về mặt khái niệm:
Self-attention: Ngôn ngữ bất biến thứ tự, cần positional info
MLP (Token-mixing): Hoạt động trên vector → nhạy cảm với thứ tự
Ví dụ:
MLP input [a, b, c] → output khác với [c, b, a]
Self-attention trên [a, b, c] tương tự với [c, b, a] (với adjustments)
Hiệu Quả Thực Nghiệm từ MLP-Mixer Paper
Bảng Kết Quả ImageNet
Theo Tolstikhin et al. (2021), khi pre-train trên ImageNet-21k:
| Model | Params | ImageNet Top-1 | Throughput |
|---|---|---|---|
| Mixer-B/16 | 59M | 76.44% | 1384 img/s |
| Mixer-L/16 | 207M | 84.15% | 419 img/s |
| Mixer-H/14 | 431M | 87.94% | 40 img/s |
| ViT-B/16 | 86M | 79.67% | 861 img/s |
| ViT-L/16 | 304M | 85.30% | 280 img/s |
| ViT-H/14 | 631M | 88.55% | 87 img/s |
Nhận xét:
-
MLP-Mixer vs ViT cùng scale:
- Mixer-L/16 (207M): 84.15% vs ViT-L/16: 85.30% → ViT tốt hơn 1.15%
- Nhưng Mixer nhanh hơn 1.5x (419 vs 280 img/s) -
Trade-off: Accuracy vs Speed
- Mixer-H/14 (431M): 87.94% ở 40 img/s
- ViT-H/14 (631M): 88.55% ở 87 img/s
- Mixer tiêu tốn ít tham số hơn, nhanh hơn, chỉ chính xác hơi kém
Scaling behavior
Khi pre-train trên các bộ dữ liệu lớn hơn, MLP-Mixer cải thiện đáng kể:
import matplotlib.pyplot as plt
# Dữ liệu từ paper
datasets = ['ImageNet\n(1.3M)', 'ImageNet-21k\n(14M)', 'JFT-300M\n(300M)']
mixer = [72.6, 84.15, 87.94]
vit = [76.5, 85.30, 88.55]
plt.figure(figsize=(10, 6))
plt.plot(datasets, mixer, 'o-', label='MLP-Mixer-L/16', linewidth=2, markersize=10)
plt.plot(datasets, vit, 's-', label='ViT-L/16', linewidth=2, markersize=10)
plt.ylabel('ImageNet Top-1 Accuracy (%)', fontsize=12)
plt.xlabel('Pre-training Dataset', fontsize=12)
plt.title('Scaling Behavior: MLP-Mixer vs Vision Transformer', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.ylim([70, 90])
plt.show()
Hình khi được in ra, mô tả: Khi dữ liệu pre-training tăng, cả MLP-Mixer lẫn ViT đều cải thiện, nhưng ViT luôn vượt trội hơn MLP-Mixer.
Kết luận
So sánh MLP truyền thống và MLP-Mixer
| Vấn Đề | MLP truyền thống | Giải Pháp MLP-Mixer |
|---|---|---|
| Mất thông tin không gian | Flatten → mất hết 2D | Patch embedding → giữ cấu trúc patch |
| Số tham số bậc hai | $(H × W × C) × H$ | $ (S)×D_S+(C)×D_{C}$(tuyến tính) |
| Thiếu inductive bias | Không locality, không parameter sharing | Token-mixing có global communication |
| Kiến trúc isotropic | Trộn lẫn tất cả ở cùng vector | Tách riêng spatial + feature mixing |
Kết luận chung
MLP-Mixer là một "sự hồi sinh" thông minh của MLP:
- Không phải MLP truyền thống: Sử dụng patches và hai loại MLPs chuyên biệt
- Không phải CNN: Không có convolution, không hierarchical pyramidal
- Không phải Transformer: Không có self-attention, không quadratic complexity
Thay vào đó:
- Token-mixing: Cho phép giao tiếp toàn cục giữa các patches
- Channel-mixing: Cho phép tương tác giữa các features
- Parameter sharing: Giảm tham số 99%, đảm bảo positional invariance
- Isotropic design: Đơn giản, mở rộng dễ dàng
Kết quả:
- Hiệu suất cạnh tranh (87-88% ImageNet với pre-training lớn)
- Tốc độ nhanh hơn ViT 2-3x
- Đơn giản hơn (chỉ MLPs, reshapes, nonlinearities)
Tài liệu tham khảo
- Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., & Dosovitskiy, A. (2021). MLP-Mixer: An all-MLP architecture for vision. NeurIPS. arXiv:2105.01601
- Damle, A. (2021). Comparing the performance of CNN and MLP in image classification.
- Dosovitskiy, A., et al. (2020). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. ICLR. arXiv:2010.11929
Chưa có bình luận nào. Hãy là người đầu tiên!