
FPT Stock Prediction: LTSF-Linear + Hidden Markov Model for Regime-Switching

I. Giới thiệu
Bài viết này trình bày giải pháp kỹ thuật cho cuộc thi AIO-2025: LTSF-Linear Forecasting Challenge. Mục tiêu của cuộc thi là dự báo giá đóng cửa (Close Price) của cổ phiếu FPT trong 100 ngày tiếp theo.
Thay vì sử dụng các mô hình Deep Learning phức tạp (như LSTM, Transformer), giải pháp tập trung khai thác hiệu quả của các mô hình tuyến tính (Linear, NLinear, DLinear) kết hợp với kỹ thuật phân tích trạng thái thị trường (Market Regime).
Thách thức chính
-
Long-term Forecasting: Dự báo 100 ngày, không phải 1-7 ngày như thông thường
-
Distribution Shift: Giá cổ phiếu thay đổi range theo thời gian
-
Market Regimes: Thị trường có các trạng thái ẩn: ổn định, biến động, chuyển đổi
-
Data Constraint: Chỉ được dùng mỗi Data train, không có xài data ngoài
Giải pháp của nhóm
Nhóm kết hợp 3 kỹ thuật chính:
-
RevIN (Reversible Instance Normalization): Xử lý distribution shift bằng cách normalize đầu vào và denormalize đầu ra
-
HMM Regime Detection: Sử dụng Hidden Markov Model để phát hiện trạng thái thị trường (Stable / Transition / Volatile)
-
Regime-Specific Models: Train model riêng cho mỗi regime, dự báo dựa trên điều kiện thị trường hiện tại
Kết quả đạt được hiện tại
| Method | Config | Private Score |
|---|---|---|
| Univariate DLinear | NoHMM + Seq480 | 28.98 |
| Univariate Linear | NoHMM + Seq480 | 39.81 |
| Multivariate DLinear | HMM + Seq60 | 47.60 |
| Multivariate Linear | HMM + Seq60 | 66.89 |
II. Các thách thức
1. Long-term Forecasting
Dự báo 100 ngày là một thách thức lớn so với các bài toán dự báo ngắn hạn (1-7 ngày). Có hai phương pháp chính:
Direct Forecasting (Multi-output)
- Train nhiều model riêng biệt, mỗi model dự báo một bước thời gian cụ thể
- Model 1 dự báo T+1, Model 2 dự báo T+2, ..., Model 100 dự báo T+100
- Ưu điểm: Không tích lũy error
- Nhược điểm: Cần train nhiều model, không capture được dependency giữa các bước
Recursive Forecasting (Autoregressive)
- Train một model duy nhất dự báo bước tiếp theo
- Dùng prediction làm input để dự báo tiếp theo
- Ưu điểm: Một model, capture được dependency
- Nhược điểm: Error tích lũy theo thời gian
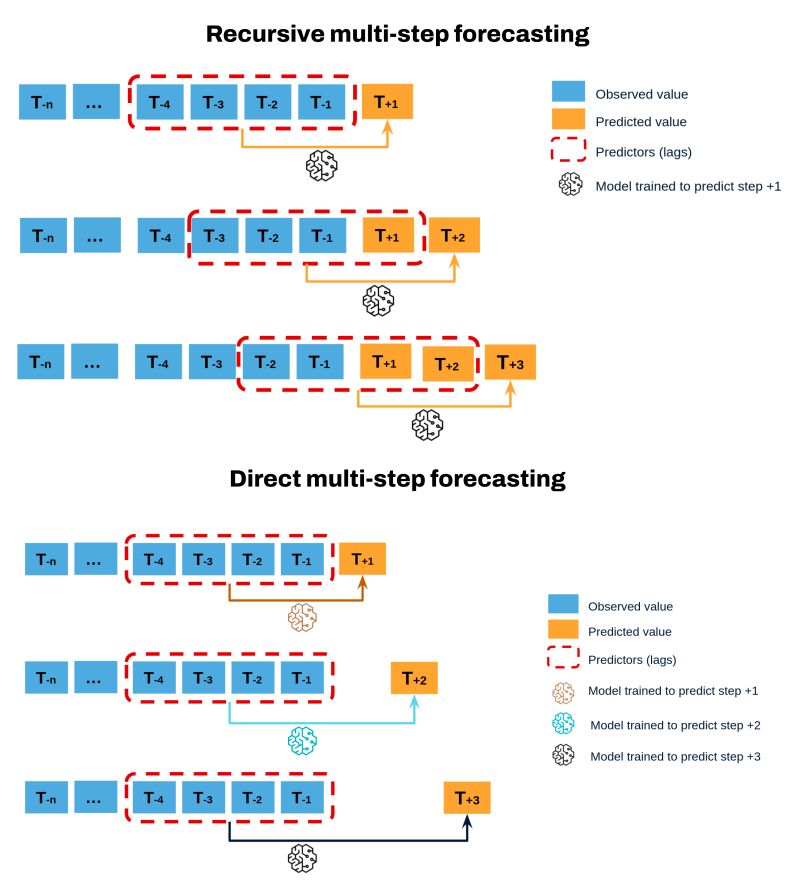
Hình 1. So sánh Direct (trái) và Recursive (phải) Forecasting.
Trong project này: Nhóm mình sử dụng Direct Forecasting - model dự báo trực tiếp 100 ngày một lần mà không cần recursive.
2. Distribution Shift
Distribution shift là hiện tượng phân phối dữ liệu thay đổi theo thời gian. Trong dữ liệu FPT, điều này thể hiện rõ ràng:
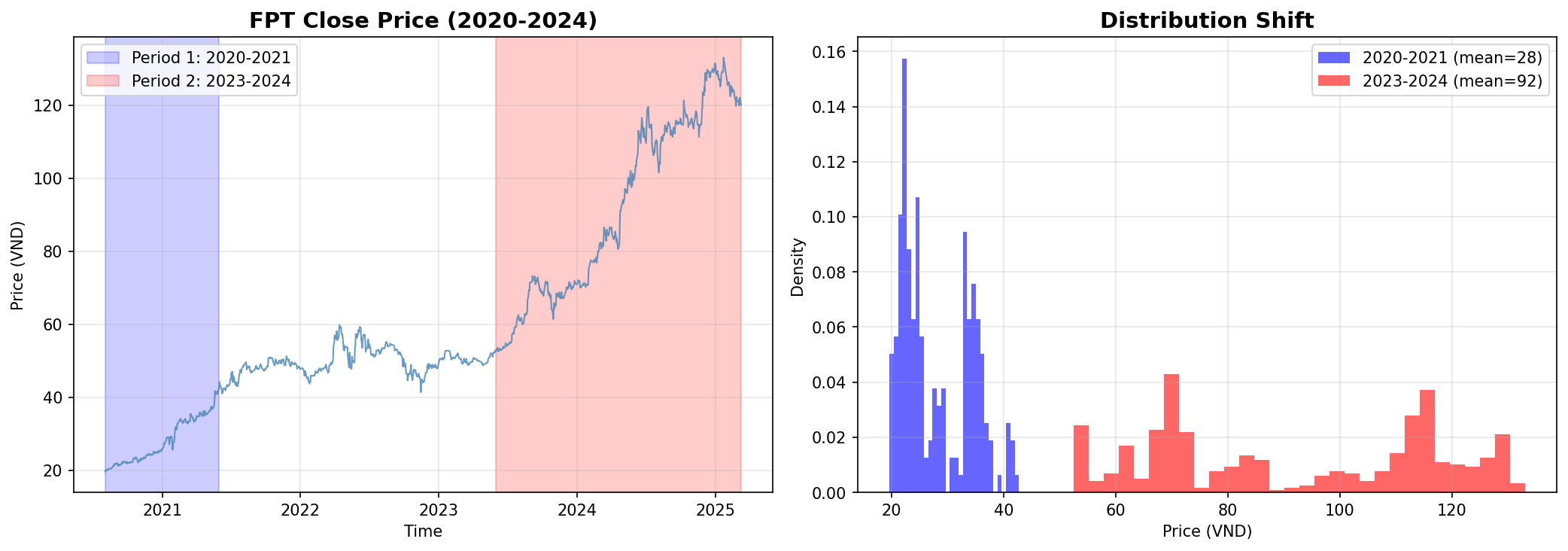
Hình 2. Distribution Shift trong dữ liệu FPT: Phân phối giá 2020-2021 hoàn toàn khác với 2023-2024.
Như hình trên cho thấy:
- Period 1 (2020-2021): Giá dao động trong khoảng thấp
- Period 2 (2023-2024): Giá đã tăng lên mức cao hơn nhiều
Mặc dù pattern biến động vẫn tương tự, nhưng scale đã thay đổi hoàn toàn. Model học trên dữ liệu cũ sẽ dự báo sai scale nếu không xử lý.
Giải pháp: RevIN (Reversible Instance Normalization).
3. Market Regimes
Thị trường tài chính không hoạt động theo một quy luật duy nhất. Thay vào đó, nó chuyển đổi giữa các trạng thái (regimes) khác nhau:
- Bull Market: Xu hướng tăng mạnh, volatility thấp
- Bear Market: Xu hướng giảm, volatility cao
- Sideways/Consolidation: Đi ngang, không có xu hướng rõ ràng
- Transition: Giai đoạn chuyển đổi giữa các regime
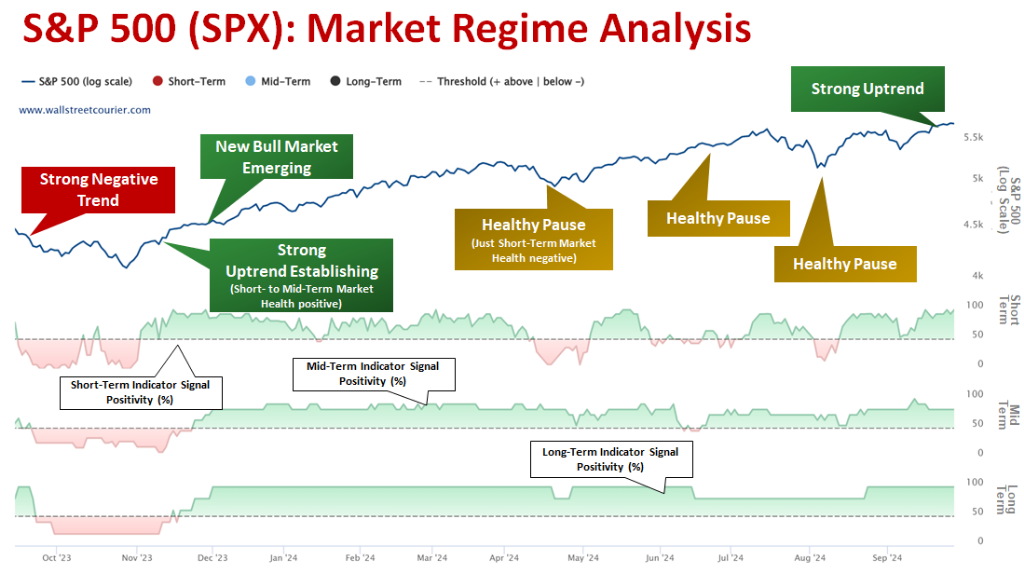
Hình 3. Phân tích Market Regime trên S&P 500 (Nguồn: Wall Street Courier)
Vấn đề: Một model duy nhất khó có thể học được tất cả patterns từ các regime khác nhau. Dữ liệu từ Bull Market có thể "nhiễu" việc học pattern của Bear Market và ngược lại.
Giải pháp: HMM Regime-Switching - phát hiện regime và train model chuyên biệt cho từng regime.
III. Giải pháp kỹ thuật
1. RevIN - Reversible Instance Normalization
1.1 Ý tưởng
RevIN là kỹ thuật normalize dữ liệu có thể đảo ngược, được thiết kế đặc biệt cho time series với distribution shift. Ý tưởng chính:
- Normalize input: Chuẩn hóa chuỗi đầu vào về mean=0, std=1
- Model học: Model học patterns trên dữ liệu đã chuẩn hóa
- Denormalize output: Khôi phục lại scale gốc cho dự báo
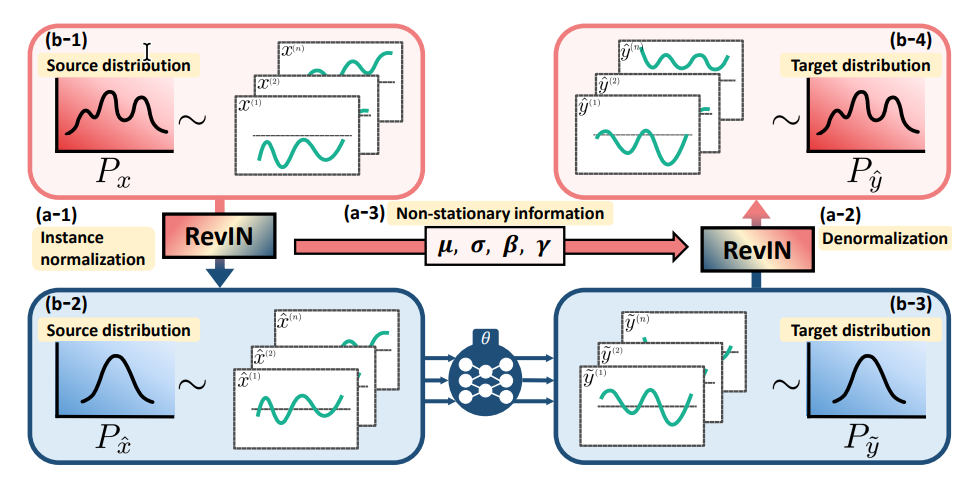
Hình 4. Cách dùng RevIN. (Nguồn: RevIN's Paper)
1.2 Thuật toán

Hình 5. Thuật toán RevIN chi tiết. (Nguồn: RevIN GitHub)
1.3 Code Implementation
class RevIN(nn.Module):
def __init__(self, num_features, eps=1e-5, affine=True):
super().__init__()
self.eps = eps
self.affine = affine
if affine:
# Bước 4: Learnable parameters $\gamma$ và $\beta$
self.gamma = nn.Parameter(torch.ones(num_features))
self.beta = nn.Parameter(torch.zeros(num_features))
def forward(self, x, mode):
if mode == 'norm':
# Bước 1: Compute instance mean
self.mean = x.mean(dim=1, keepdim=True).detach()
# Bước 2: Compute instance variance
self.std = torch.sqrt(x.var(dim=1, keepdim=True) + self.eps).detach()
# Bước 3: Normalize
x = (x - self.mean) / self.std
# Bước 4: Scale and shift với γ, β
if self.affine:
x = x * self.gamma + self.beta
return x
elif mode == 'denorm':
# Bước 6: Reverse scale and shift
if self.affine:
x = (x - self.beta) / (self.gamma + self.eps)
# Bước 7: Denormalize về scale gốc
x = x * self.std + self.mean
return x
1.4 Apply vào dữ liệu FPT
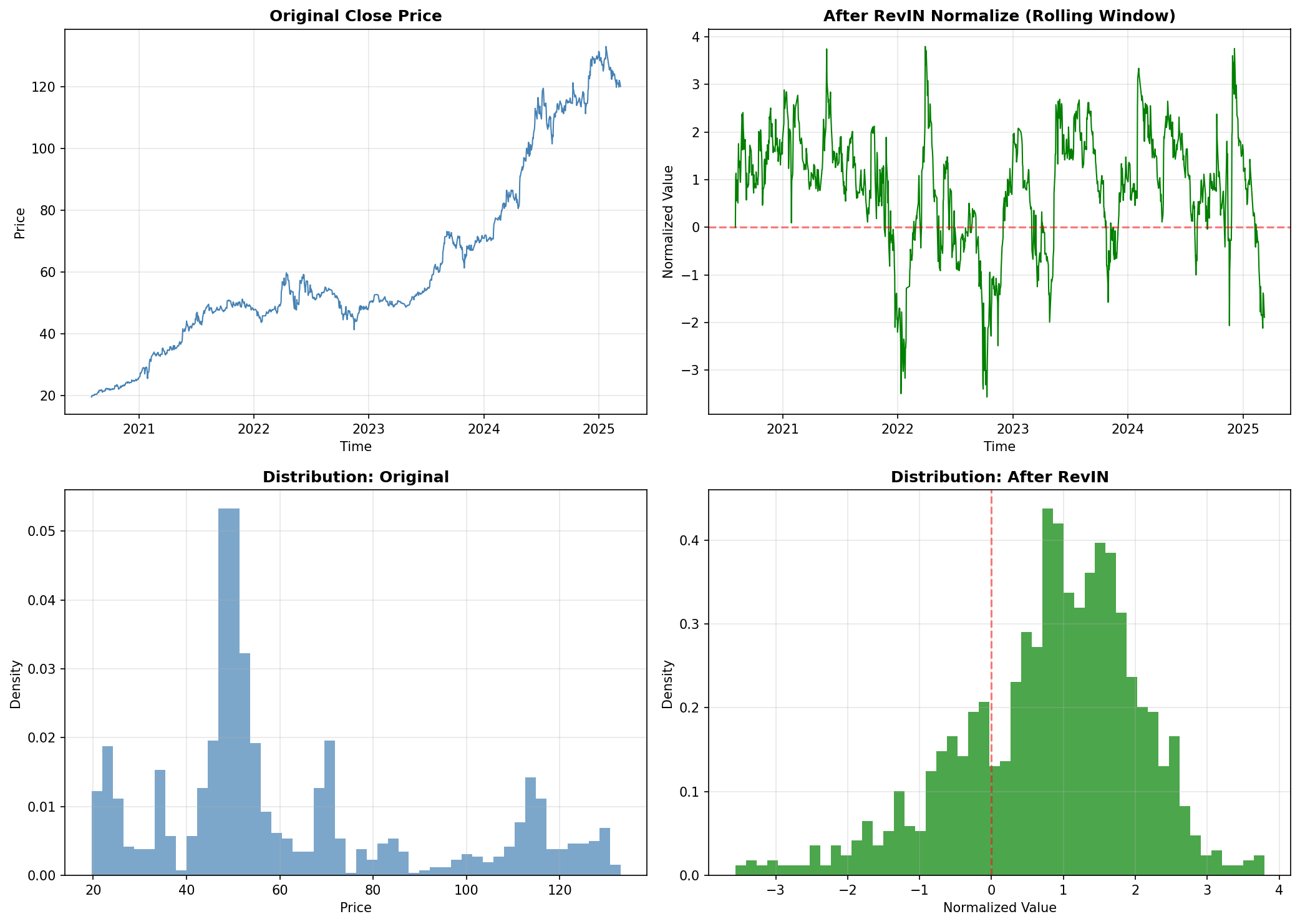
Hình 6. Áp dụng RevIN vào dữ liệu FPT.
Phân tích:
- Góc trên trái (Original): Giá FPT có range thay đổi từ ~50 (2020) lên ~130 (2024)
- Góc trên phải (After RevIN): Sau normalize, giá dao động quanh 0 với std ≈ 1
- Góc dưới trái (Distribution Original): Phân phối lệch phải, nhiều peaks khác nhau
- Góc dưới phải (Distribution After): Phân phối gần chuẩn hơn, tập trung quanh 0
Lợi ích: Model không còn bị ảnh hưởng bởi sự thay đổi scale theo thời gian.
2. HMM Regime Detection
2.1 Hidden Markov Model
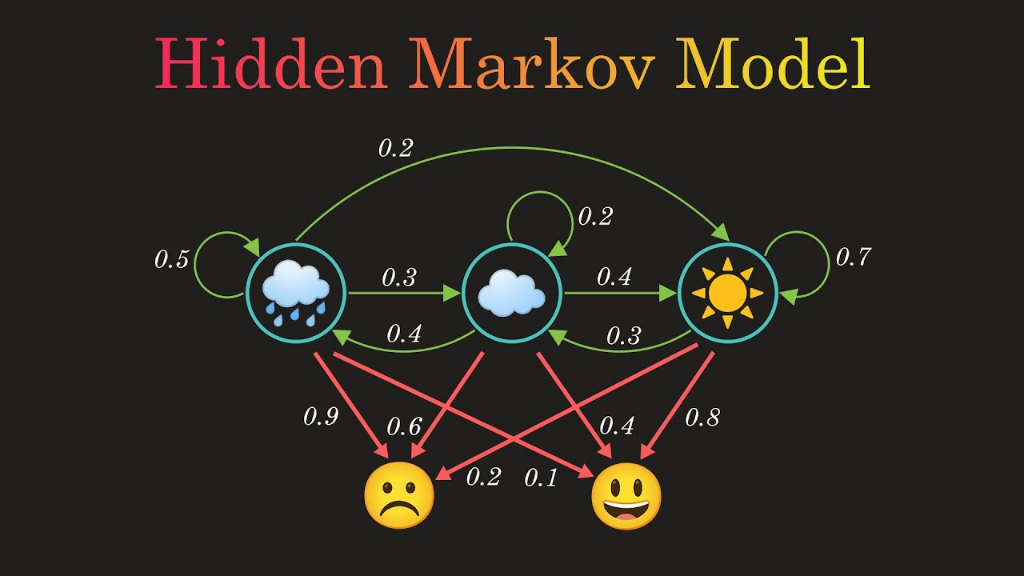
Hình 7. Minh họa Hidden Markov Model với 3 hidden states và 2 observations. (Nguồn: YouTube)
HMM là mô hình xác suất trong đó:
- Hidden states (Regimes): Trạng thái ẩn mà ta không quan sát trực tiếp (ví dụ: mưa, mây, nắng)
- Observations: Các features ta đo được (ví dụ: buồn, vui)
- Transition Matrix: Xác suất chuyển giữa các trạng thái (các số 0.2, 0.3, 0.4, ...)
Trong bối cảnh thị trường chứng khoán:
- Hidden states: Bull Market, Bear Market, Sideways
- Observations: Returns, Volatility, Trend
2.2 Features cho HMM
Để HMM có thể phát hiện regime, ta cần cung cấp các features phản ánh "hành vi" thị trường, trong bài nhóm sử dụng 3 feature cơ bản cho HMM:
- Returns: $R_t = \frac{Close_t - Close_{t-1}}{Close_{t-1}}$
- Ý nghĩa: Tỷ suất sinh lời ngày, cho biết thị trường tăng hay giảm. $Close_t$: giá đóng cửa ngày $t$.
- Volatility: $Vol_t = std(R_{t-9}, ..., R_t)$
- Ý nghĩa: Độ biến động 10 ngày, cao = thị trường bất ổn.
- Trend: $Trend_t = \frac{MA_{10}(t) - MA_{10}(t-1)}{MA_{10}(t-1)}$
- Ý nghĩa: Xu hướng trung bình động, cho biết trend tăng/giảm.
# Tính toán features
df['returns'] = df['close'].pct_change().fillna(0)
df['volatility'] = df['returns'].rolling(window=10).std().fillna(0)
df['trend'] = df['close'].rolling(window=10).mean().pct_change().fillna(0)
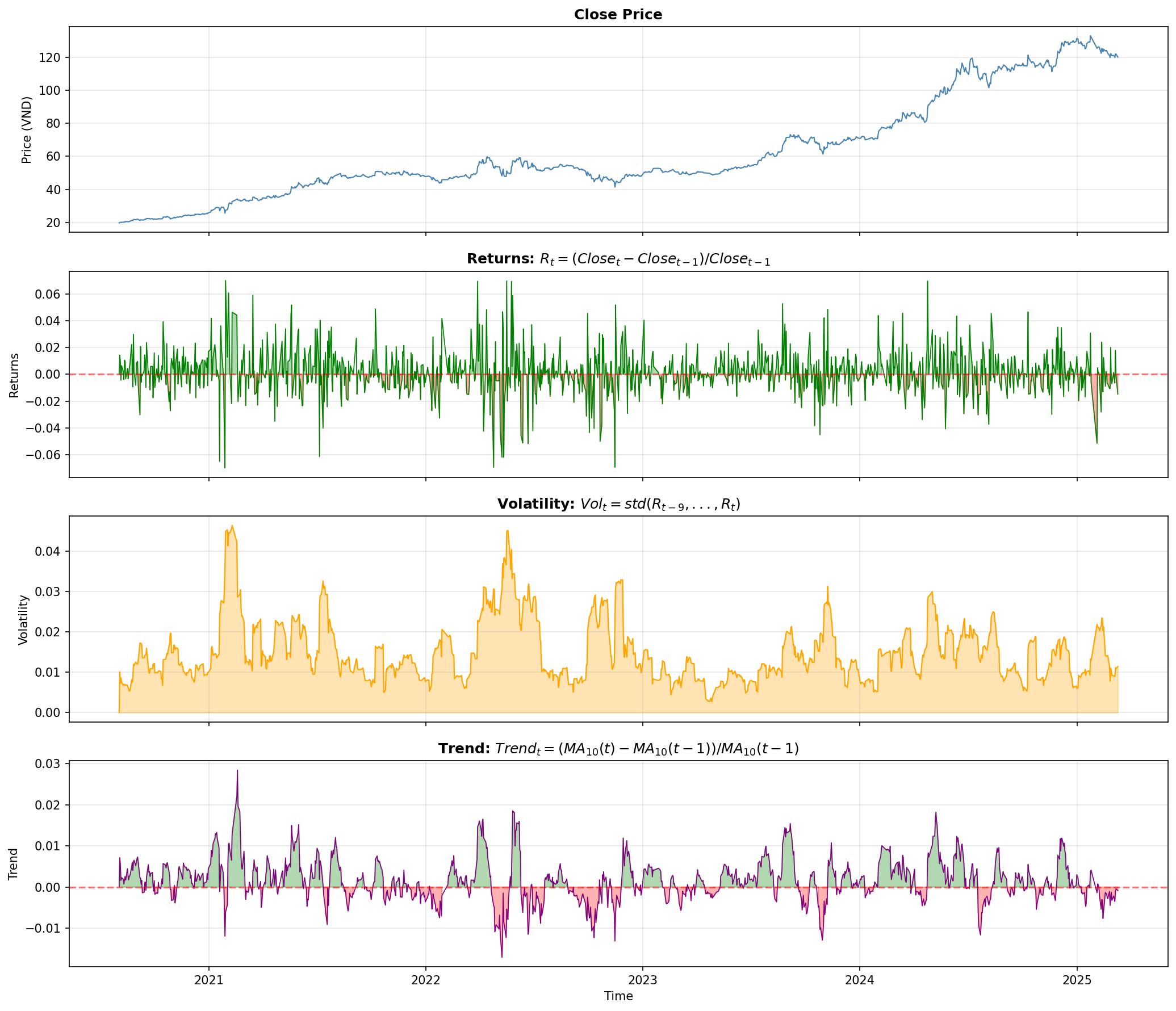
Hình 8. Visualization các features cho HMM trên dữ liệu FPT.
Nhận xét từ hình:
- Returns: Dao động quanh 0, có các spike lớn vào thời điểm biến động mạnh
- Volatility: Tăng cao vào các giai đoạn bất ổn (2020, 2022), thấp khi thị trường ổn định
- Trend: Cho thấy xu hướng tăng/giảm rõ ràng hơn so với returns
2.3 Regime Window
Regime Window là số ngày đầu tiên bị bỏ qua khi detect regimes:
class RegimeDetector:
def __init__(self, n_components=3, window=30):
self.window = window
def fit(self, df):
# Bỏ qua `window` ngày đầu
features = df[['returns', 'volatility', 'trend']].iloc[self.window:].values
self.model.fit(features)
Tại sao cần Regime Window?
- Các features như volatility và trend cần rolling window để tính toán
- Những ngày đầu tiên có giá trị NaN hoặc không ổn định
- window=30 → bỏ 30 ngày đầu, đảm bảo features đã ổn định
Giá trị thường dùng: 30, 60
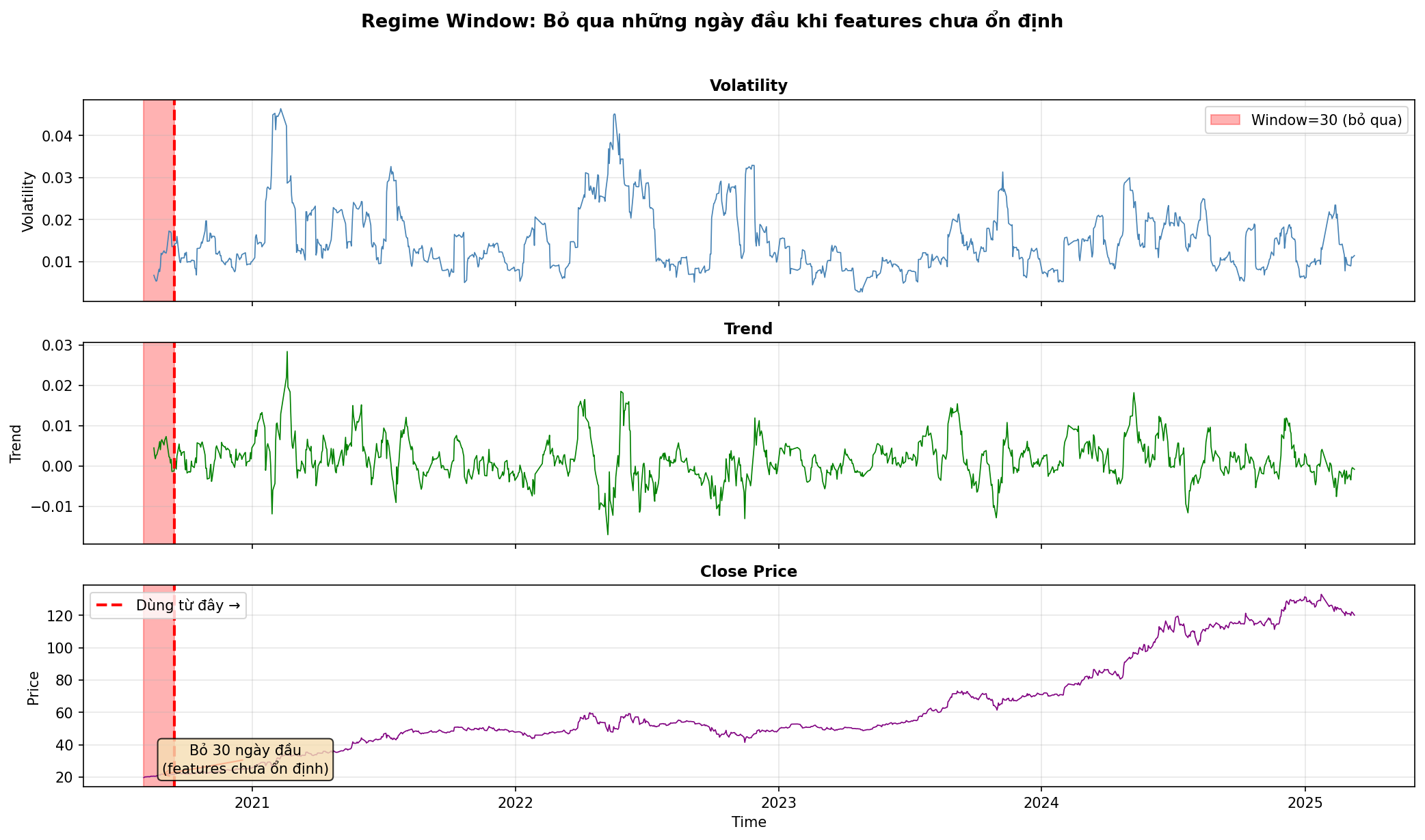
Hình 9. Regime Window: Bỏ qua 30 ngày đầu khi features chưa ổn định.
2.4 Chọn số lượng Regimes
Câu hỏi: Nên dùng bao nhiêu regimes? 3? 4? 5?
N = 3 Regimes
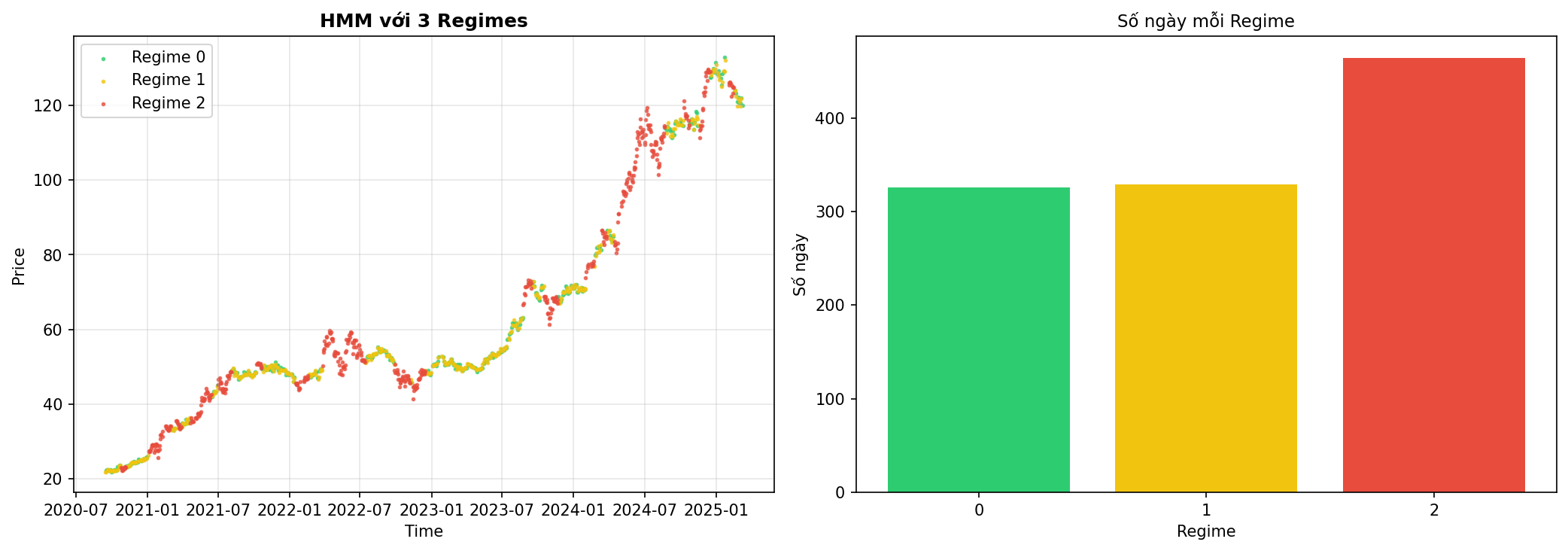
Hình 10. HMM với 3 Regimes trên dữ liệu FPT.
Phân tích:
- Regime 0 (Xanh lá): Thường xuất hiện khi thị trường ổn định, volatility thấp
- Regime 1 (Vàng): Giai đoạn chuyển đổi, thường thấy trước khi thị trường đổi hướng
- Regime 2 (Đỏ): Thị trường biến động mạnh, có thể là crash hoặc rally mạnh
Nhận xét: Phân chia 3 regime khá rõ ràng, mỗi regime có đủ samples để train model.
N = 4 Regimes
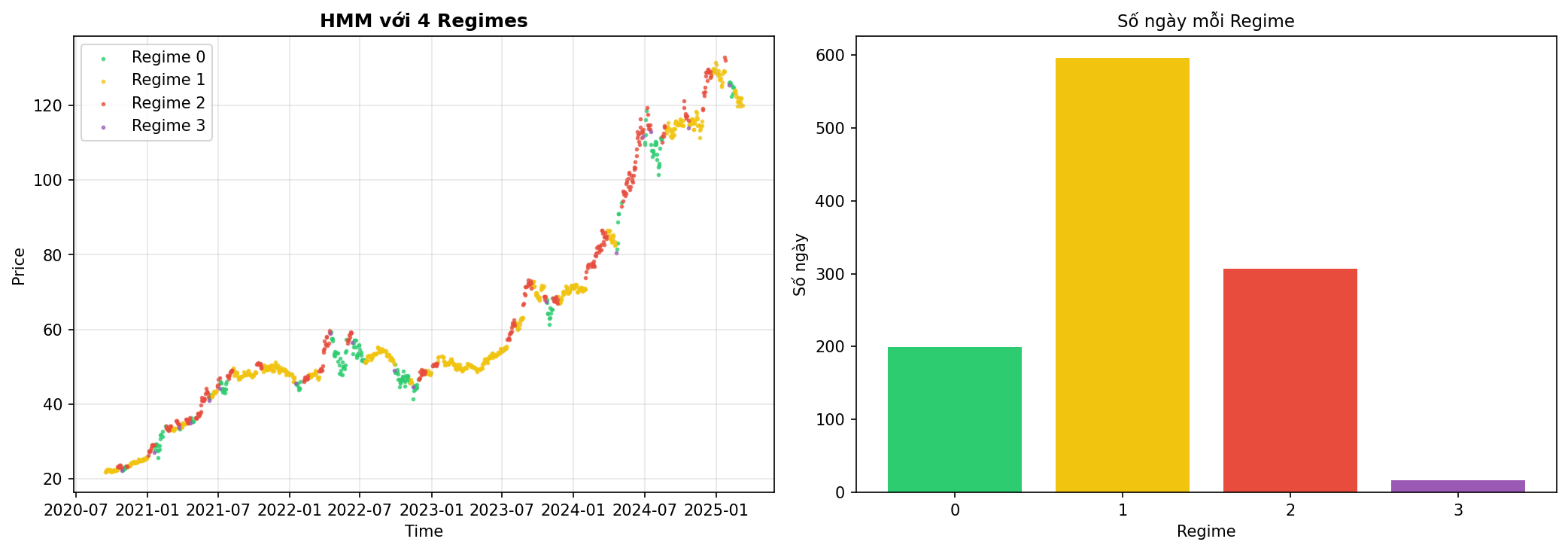
Hình 11. HMM với 4 Regimes trên dữ liệu FPT.
Phân tích:
- Phân chia chi tiết hơn với 4 trạng thái
- Một số regime có thể có ít samples, gây khó khăn cho training
- Có thể bắt được nhiều chi tiết hơn, nhưng cũng dễ overfit
Trade-off:
| N Regimes | Ưu điểm | Nhược điểm |
|---|---|---|
| N = 2 | Đơn giản, nhiều samples/regime | Quá thô, bỏ sót chi tiết |
| N = 3 | Cân bằng, phổ biến | Có thể không đủ chi tiết |
| N = 4+ | Chi tiết hơn | Ít samples/regime, dễ overfit |
Trong project này: Nhóm chọn N = 3 vì:
1. Đủ chi tiết để phân biệt bull/bear/transition
2. Mỗi regime có đủ samples để train
2.5 Lưu ý quan trọng
Giải pháp: Giả định regime hiện tại (
regimes[-1]) tiếp tục trong 100 ngày forecast.
3. LTSF-Linear Models
3.1 RLinear (Linear + RevIN)
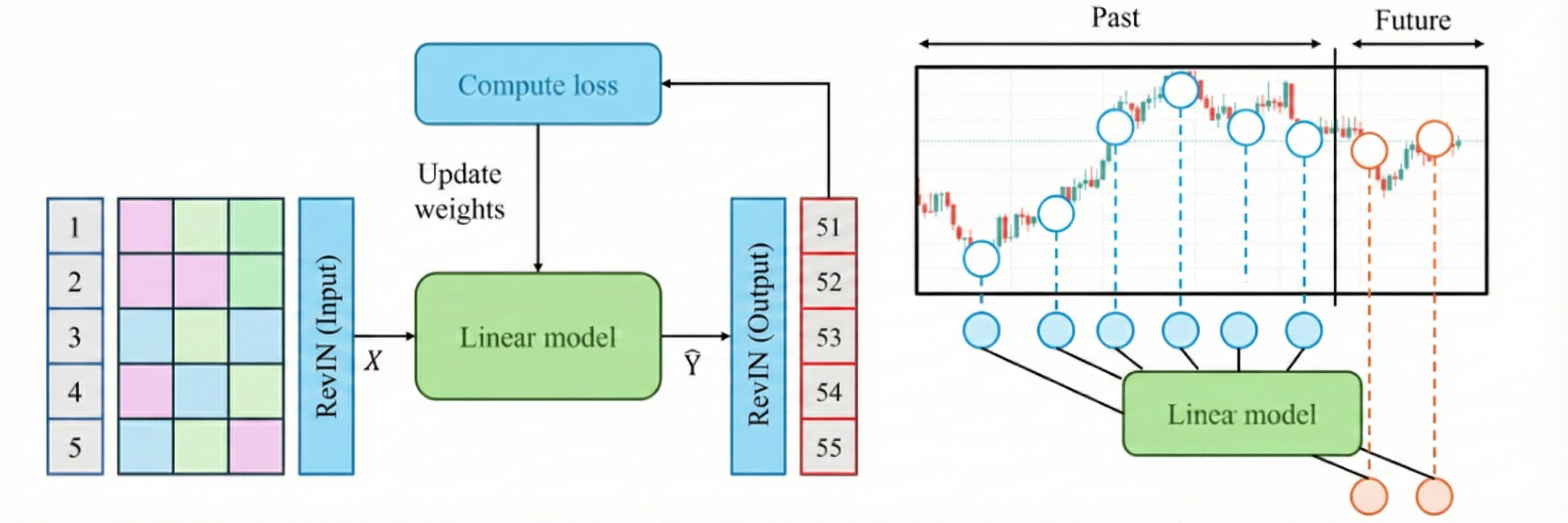
Hình 12. Kiến trúc Linear + RevIN: RevIN → Linear → Denormalize.
Kiến trúc:
1. RevIN Normalize: Chuẩn hóa input về mean=0, std=1
2. Linear Layer: Một lớp fully-connected ánh xạ từ seq_len → pred_len
3. Denormalize: Khôi phục scale gốc cho output
Công thức:
$$\hat{y} = W \cdot x_{norm} + b$$
$$y = \hat{y} \cdot \sigma + \mu$$
Trong đó $W \in \mathbb{R}^{pred\_len \times seq\_len}$ là ma trận trọng số.
class Linear(nn.Module):
def __init__(self, seq_len, pred_len, num_features):
super().__init__()
self.revin = RevIN(num_features)
self.linear = nn.Linear(seq_len, pred_len)
def forward(self, x):
# RevIN normalize
x = self.revin(x, 'norm')
# Linear projection
out = self.linear(x[:, :, 0]) # Univariate: chỉ dùng close
# RevIN denormalize
out = self.revin(out.unsqueeze(-1), 'denorm').squeeze(-1)
return out
3.2 RDLinear (DLinear + RevIN)
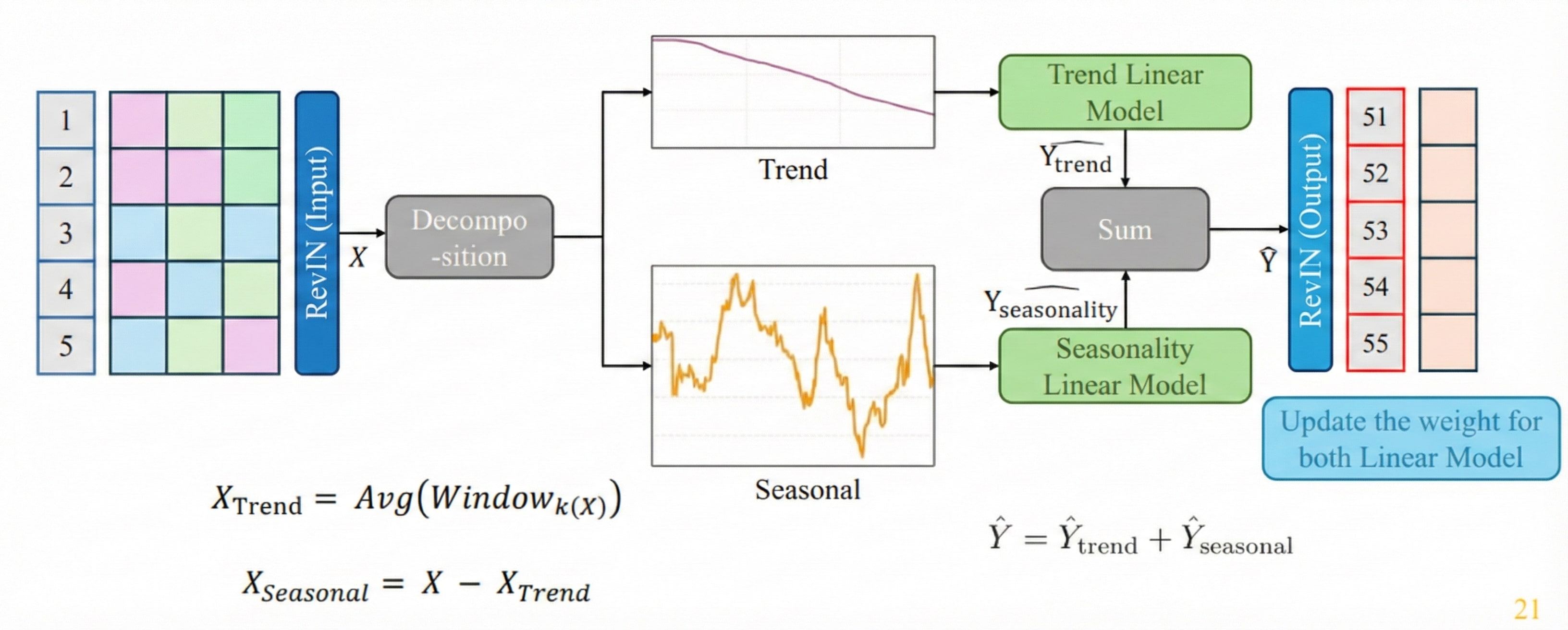
Hình 13. Kiến trúc DLinear + RevIN: Decomposition thành Trend + Seasonal.
Ý tưởng: Tách chuỗi thời gian thành 2 thành phần:
- Trend: Xu hướng dài hạn (tính bằng Moving Average)
- Seasonal: Biến động ngắn hạn (phần còn lại)
Công thức:
$$x_{trend} = \text{MovingAvg}(x, kernel)$$
$$x_{seasonal} = x - x_{trend}$$
$$\hat{y} = W_t \cdot x_{trend} + W_s \cdot x_{seasonal}$$
class DLinear(nn.Module):
def __init__(self, seq_len, pred_len, num_features, kernel_size=25):
super().__init__()
self.revin = RevIN(num_features)
self.moving_avg = nn.AvgPool1d(kernel_size, stride=1, padding=kernel_size//2)
self.linear_trend = nn.Linear(seq_len, pred_len)
self.linear_seasonal = nn.Linear(seq_len, pred_len)
def forward(self, x):
# RevIN normalize
x = self.revin(x, 'norm')
x_in = x[:, :, 0] # Univariate
# Decomposition
trend = self.moving_avg(x_in.unsqueeze(1)).squeeze(1)
seasonal = x_in - trend
# Separate linear projections
out = self.linear_trend(trend) + self.linear_seasonal(seasonal)
# RevIN denormalize
out = self.revin(out.unsqueeze(-1), 'denorm').squeeze(-1)
return out
Tại sao DLinear tốt hơn?
- Trend và Seasonal có patterns khác nhau → cần weights khác nhau
- Linear đơn phải học cả 2 patterns cùng lúc → khó hơn
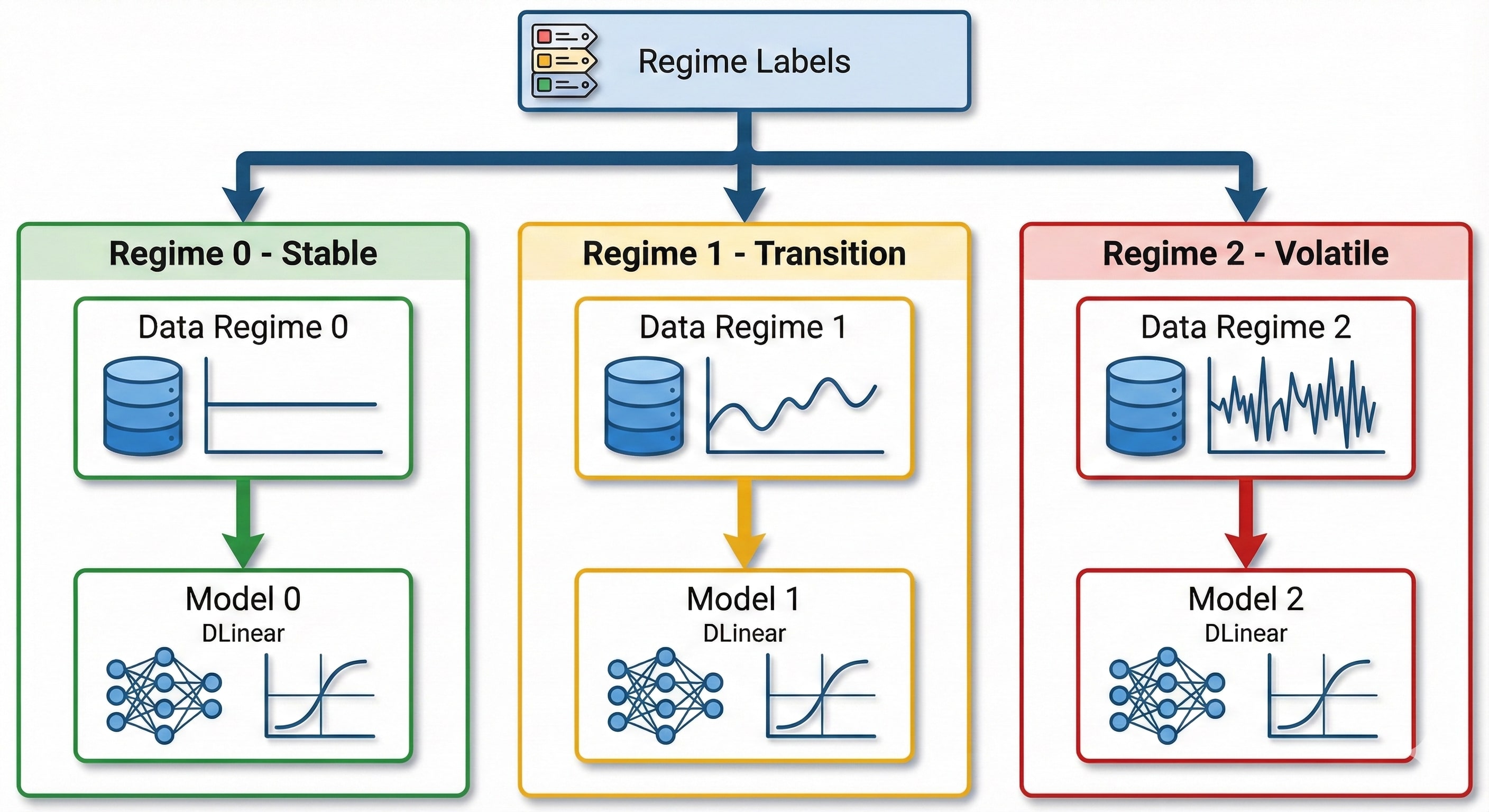
4. Regime-Specific Training
Hình 14. Quá trình gán nhãn Regime bằng HMM. (Gen by Gemini)
4.1 Ý tưởng
Thay vì train một model duy nhất trên toàn bộ dữ liệu, ta:
1. Dùng HMM để phân cụm dữ liệu thành các regimes (trạng thái thị trường ẩn)
2. Train một model riêng trên dữ liệu của từng regime
3. Khi forecast: xác định regime hiện tại → chọn model đó → predict
4.2 Code
# === TRAINING ===
# 1. Fit HMM trên TRAIN data
hmm = GaussianHMM(n_components=3)
hmm.fit(train_features) # features = [returns, volatility, trend]
# 2. Predict regimes cho TRAIN + VAL
regimes = hmm.predict(trainval_features)
# 3. Train model riêng cho mỗi regime
models = {}
for r in [0, 1, 2]:
mask = (regimes == r)
X_r, y_r = X_trainval[mask], y_trainval[mask]
models[r] = DLinear(seq_len, pred_len, num_features)
train(models[r], X_r, y_r)
# === PREDICTION ===
# 4. Lấy regime cuối cùng
current_regime = regimes[-1]
# 5. Dùng model tương ứng để predict
prediction = models[current_regime](last_sequence)
4.3 Tại sao hiệu quả?
Một model cho tất cả: Phải học cùng lúc pattern của bull, bear, sideways → confused
Model riêng theo regime: Mỗi model chỉ tập trung học pattern của 1 regime → specialized
Ví dụ:
- Regime 0 (Stable): Model học pattern ổn định, volatility thấp
- Regime 1 (Transition): Model học các dấu hiệu đổi hướng
- Regime 2 (Volatile): Model học cách xử lý biến động mạnh
IV. Luồng xử lý
Tổng quan Pipeline
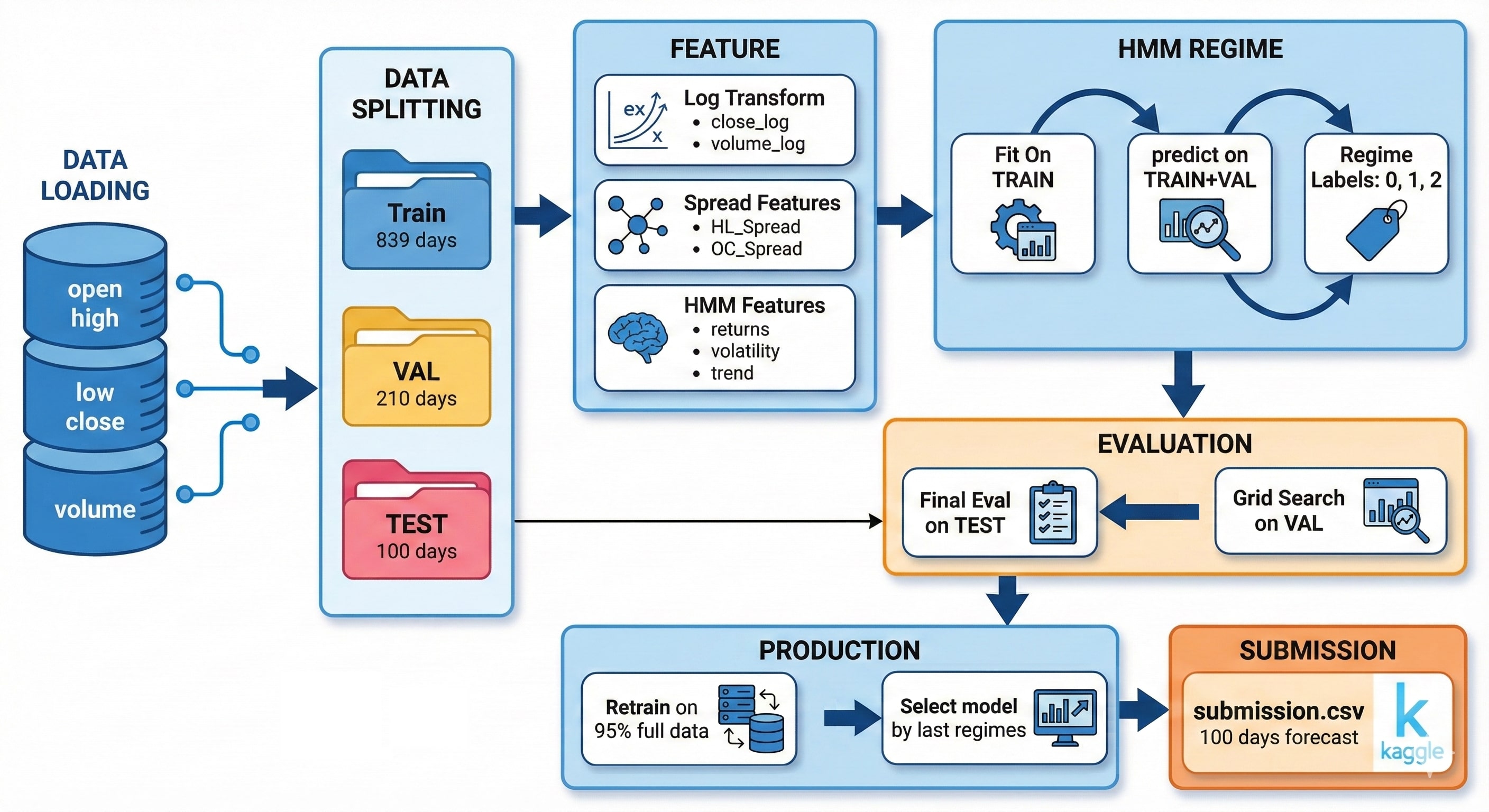
Hình 15. Tổng quan quy trình xử lý dữ liệu và huấn luyện mô hình. (Gen by Gemini)
1. Data Loading
Load dữ liệu OHLCV (Open, High, Low, Close, Volume) từ file CSV:
df = pd.read_csv('data/FPT_train.csv')
# Columns: time, open, high, low, close, volume
# 1149 rows (days)
2. Feature Engineering
2.1 Log Transform
Áp dụng log transform cho close và volume để ổn định phương sai:
df['close_log'] = np.log(df['close'])
df['volume_log'] = np.log(df['volume'] + 1)
Tại sao? Dữ liệu tài chính thường có phân phối lệch phải. Log transform giúp:
- Ổn định phương sai
- Dễ học pattern hơn
2.2 Spread Features
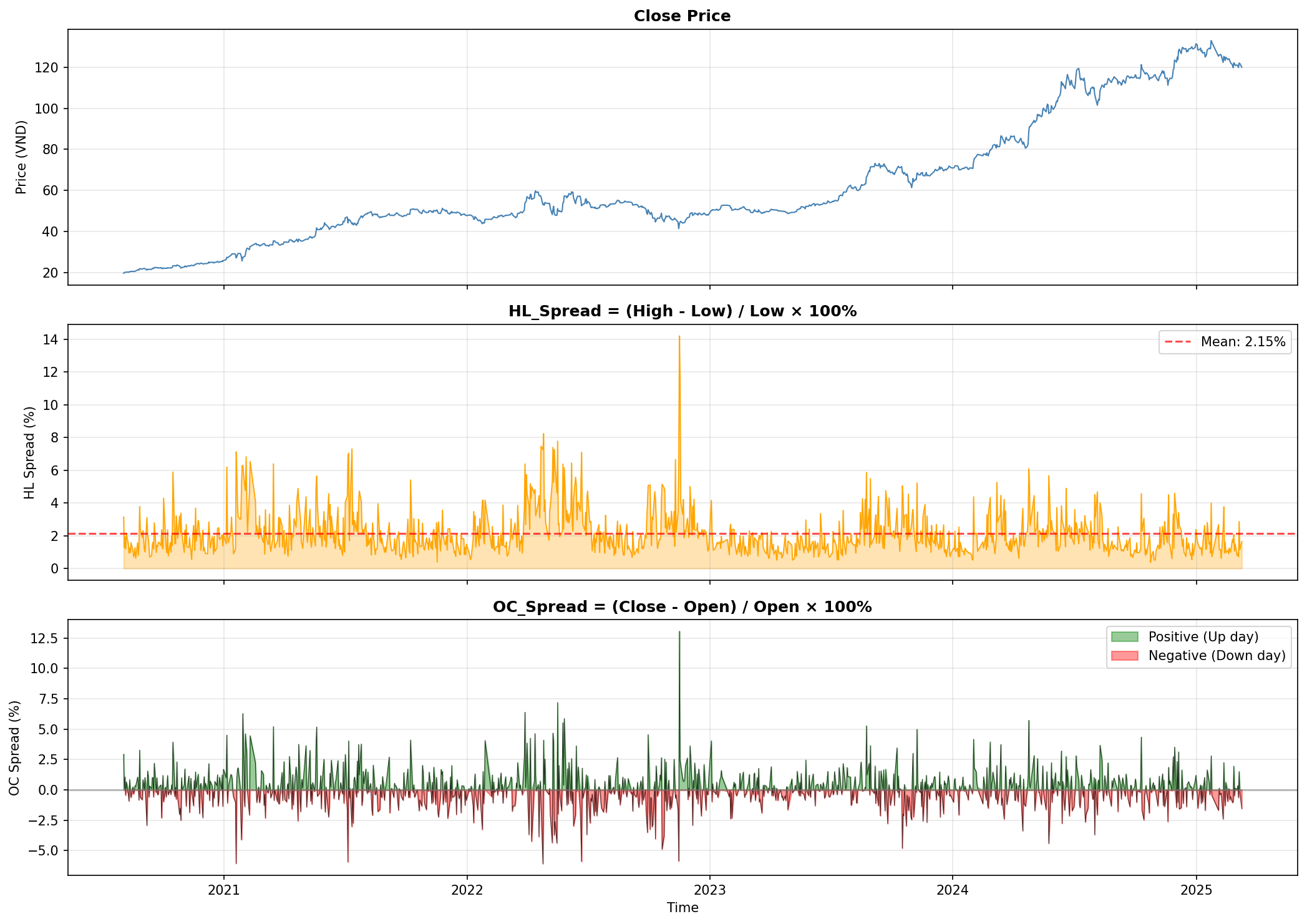
Hình 16. Visualization các Spread Features trên dữ liệu FPT.
HL_Spread (High-Low Spread):
$$HL\_Spread = \frac{High - Low}{Low} \times 100\%$$
- Đo độ biến động trong ngày
- Cao → thị trường biến động mạnh
- Thấp → thị trường ổn định
OC_Spread (Open-Close Spread):
$$OC\_Spread = \frac{Close - Open}{Open} \times 100\%$$
- Đo xu hướng trong ngày
- Dương (xanh) → ngày tăng
- Âm (đỏ) → ngày giảm
trong đó: $High, Low, Open, Close$ là giá cao nhất, thấp nhất, mở cửa và đóng cửa trong ngày.
df['HL_Spread'] = (df['high'] - df['low']) / df['low']
df['OC_Spread'] = (df['close'] - df['open']) / df['open']
2.3 HMM Features
Từ $Close$ có thể tính ra được các feature cho HMM:
df['returns'] = df['close'].pct_change()
df['volatility'] = df['returns'].rolling(window=10).std()
df['trend'] = df['close'].rolling(window=10).mean().pct_change()
Tại sao lại chọn window = 10?
Nguồn: 10 Day Moving Average Explanation For Trader
- Trend ngắn hạn: 10 ngày (~2 tuần giao dịch) là chuẩn mực để xác định xu hướng ngắn hạn, giúp bám sát price action.
- Momentum: Giúp đo lường sức mạnh của xu hướng hiện tại; giá nằm trên MA10 thường báo hiệu đà tăng mạnh.
- Giảm nhiễu: Đủ dài để loại bỏ nhiễu từng phiên (daily noise) nhưng đủ ngắn để phản ứng nhanh với thay đổi xu hướng.
3. Data Splitting
| Split | Days | Mục đích |
|---|---|---|
| TRAIN | 839 (73%) | Train model |
| VAL | 210 (18%) | Early stopping, tuning |
| TEST | 100 (9%) | Đánh giá cuối cùng |
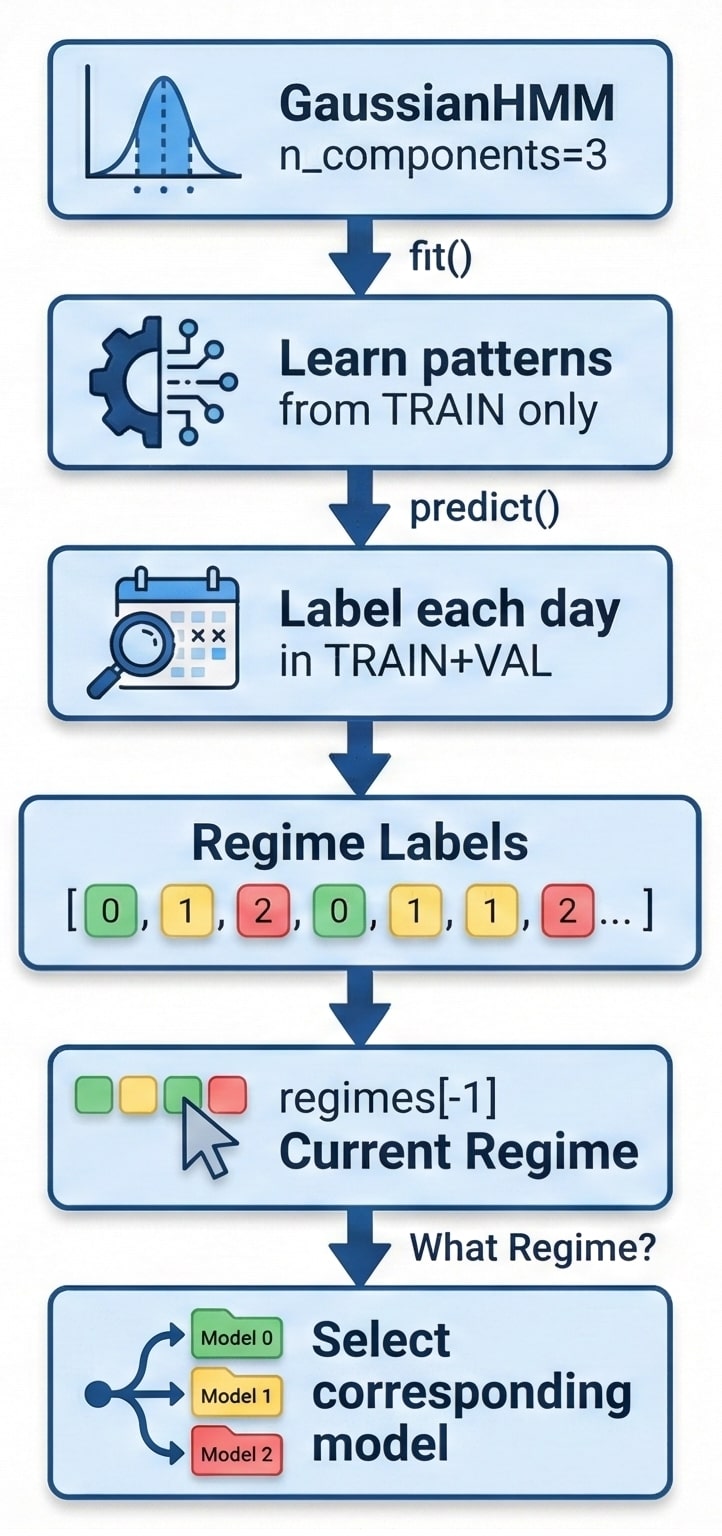
4. HMM Regime Detection
![Minh họa regimes[-1]](/static/uploads/20251207_231446_d63b6406.png)
Hình 17. Regime cuối cùng (regimes[-1]).
LƯU Ý QUAN TRỌNG: Tránh Data Leakage
- fit() CHỈ trên TRAIN → để học patterns
- predict() trên TRAIN+VAL → để có regime labels cho cả 2
- KHÔNG predict được trên TEST vì chưa có data!
# Fit HMM CHỈ trên TRAIN
hmm = RegimeDetector(n_components=3)
hmm.fit(train_df)
# Predict trên TRAIN + VAL
regimes = hmm.predict(trainval_df)
5. Model Training (Per Regime)
Hình 18. Huấn luyện mô hình riêng biệt cho từng Regime. (Gen by Gemini)
Với mỗi regime, train một model riêng:
for r in [0, 1, 2]:
mask = (regimes == r)
X_r, y_r = X_trainval[mask], y_trainval[mask]
models[r] = DLinear(seq_len, pred_len, num_features)
train(models[r], X_r, y_r)
6. Evaluation on TEST
Đánh giá model trên TEST set để kiểm tra:
# Lấy regime cuối của TRAINVAL
test_regime = regimes[-1]
# Dùng model tương ứng để predict
predictions = models[test_regime](X_test)
# Tính MSE
test_mse = ((predictions - y_test) ** 2).mean()
Mục đích: Đảm bảo pipeline hoạt động tốt trước khi submit.
7. Production & Submission
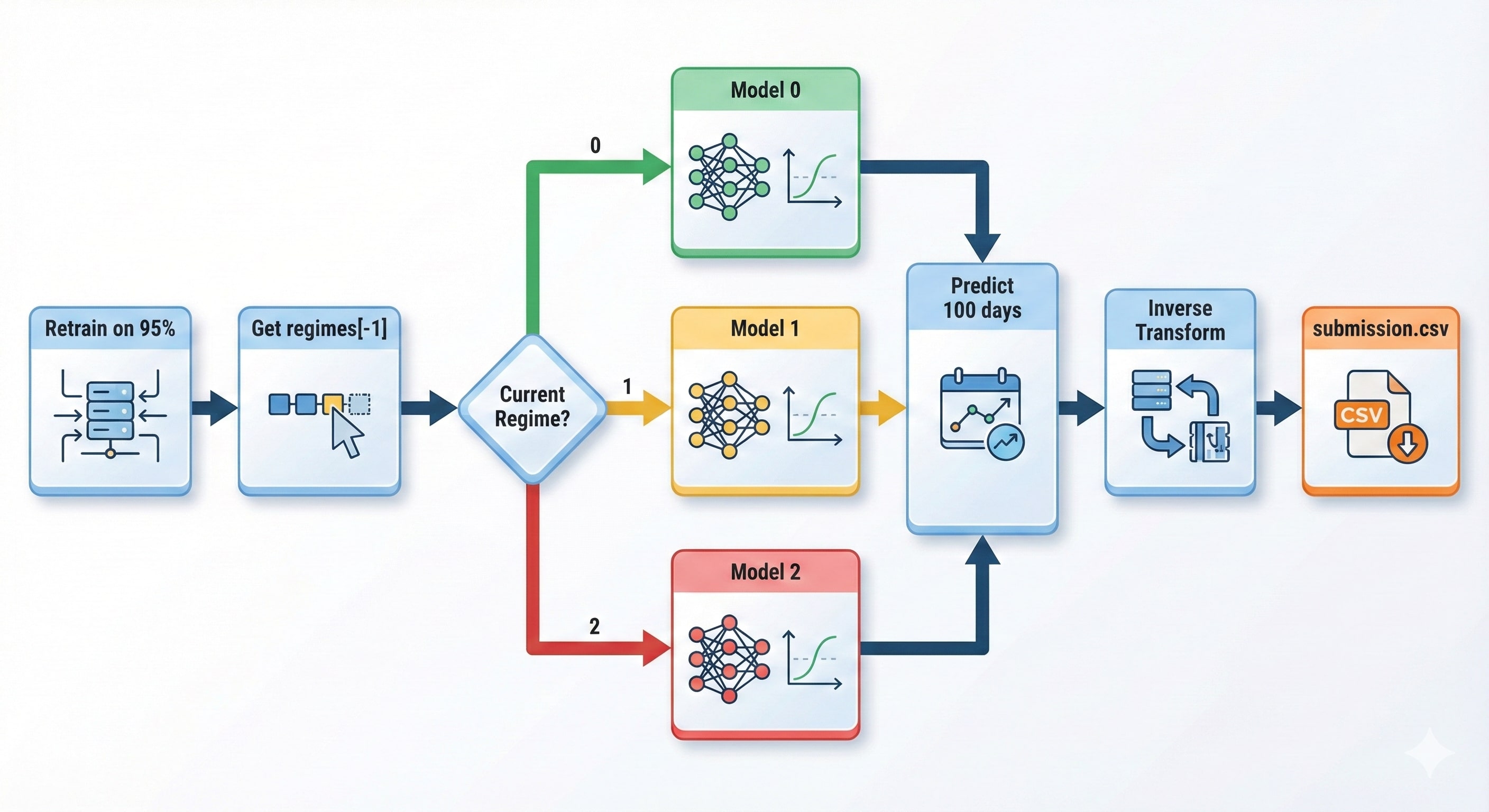
Hình 19. Quy trình Retrain và Predict cho Production. (Gen by Gemini)
7.1 Retrain for Production
Sau khi đã validate xong, retrain trên 95% toàn bộ data:
# Chia lại data: 95% train, 5% kept for regime detection
production_df = full_df.iloc[:int(len(full_df) * 0.95)]
# Fit HMM lại trên production data
hmm.fit(production_df)
regimes = hmm.predict(production_df)
7.2 Select Model by Current Regime
# Regime cuối cùng = "tâm lý thị trường" hiện tại
current_regime = regimes[-1]
print(f"Current market regime: {current_regime}")
7.3 Final Prediction & Submission
# Chọn model tương ứng với current regime
final_model = models[current_regime]
# Predict 100 ngày
last_sequence = get_last_sequence(production_df)
predictions = final_model(last_sequence)
# Inverse transform (nếu dùng log)
predictions = np.exp(predictions)
# Tạo submission
submission = pd.DataFrame({
'row_id': range(len(predictions)),
'close': predictions
})
submission.to_csv('submission.csv', index=False)
V. Kết quả đánh giá
Nhóm sử dụng kết quả từ hệ thống Kaggle để có đánh giá khách quan nhất dựa trên Private Leaderboard.
Bảng kết quả (Kaggle Leaderboard)
LƯU Ý:
- Trong quá trình thi, nhóm từng đạt được mức Private Score 14.35 (top 9). Tuy nhiên, sau khi kiểm tra kỹ lưỡng, nhóm phát hiện đó là kết quả của việc Data Leakage (do sơ suất trong khâu xử lý data pipeline).
- Sau khi fix lỗi và retrain lại pipeline chuẩn, số điểm ổn định (stable score) mà nhóm đạt được là 28.98. Đây mới là kết quả thực sự phản ánh hiệu năng của giải pháp. Nhóm quyết định trung thực với kết quả này thay vì "ăn may".
Top 4 Models tốt nhất
| # | Model | Config | Private Score |
|---|---|---|---|
| 1 | Univariate DLinear | Seq480 (NoHMM) | 28.9824 |
| 2 | Univariate Linear | Seq480 (NoHMM) | 39.8063 |
| 3 | Multivariate DLinear | Seq60 (HMM) | 47.6060 |
| 4 | Multivariate Linear | Seq60 (HMM) | 66.8885 |
So sánh trực quan
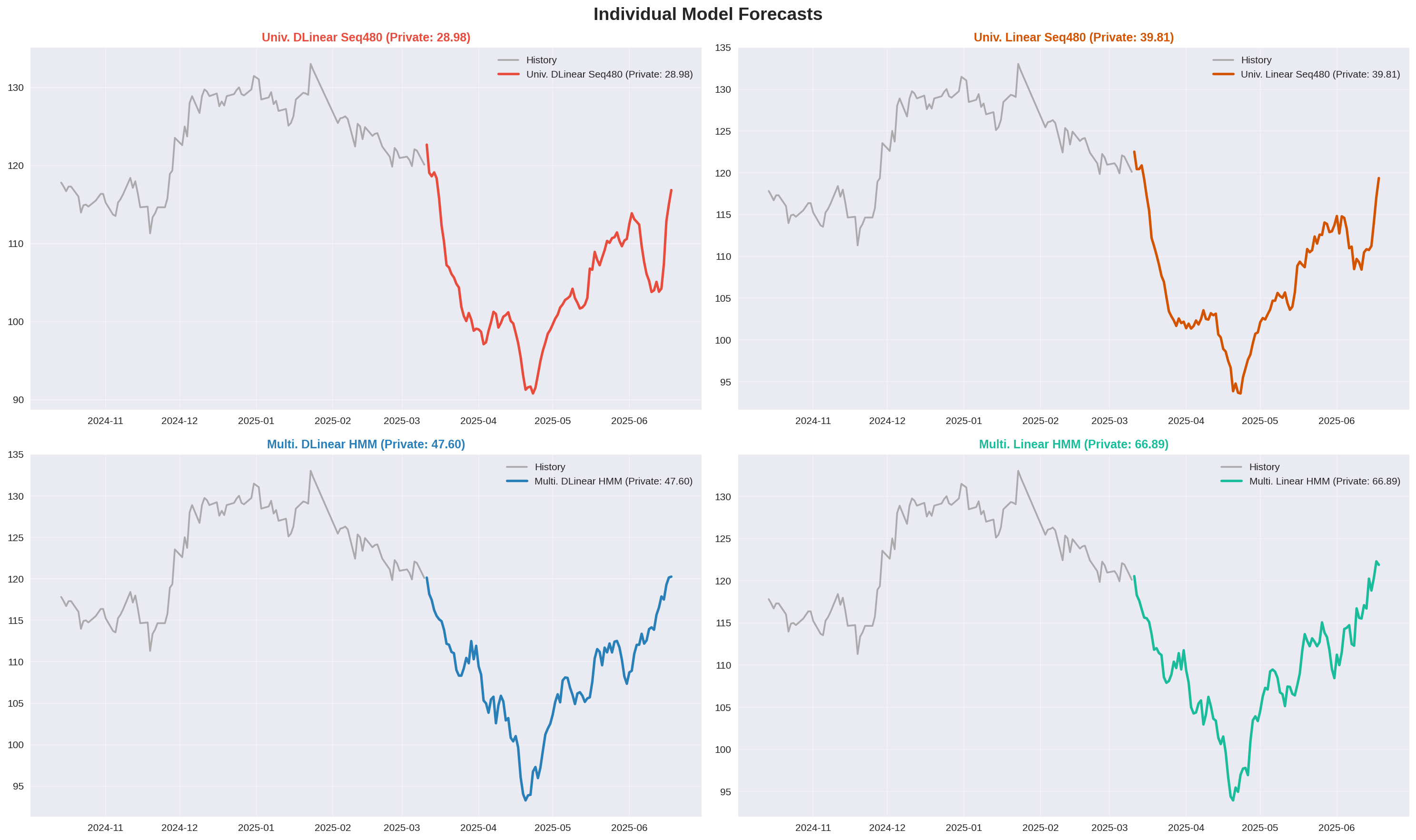
Hình 20. Dự báo chi tiết của từng model.
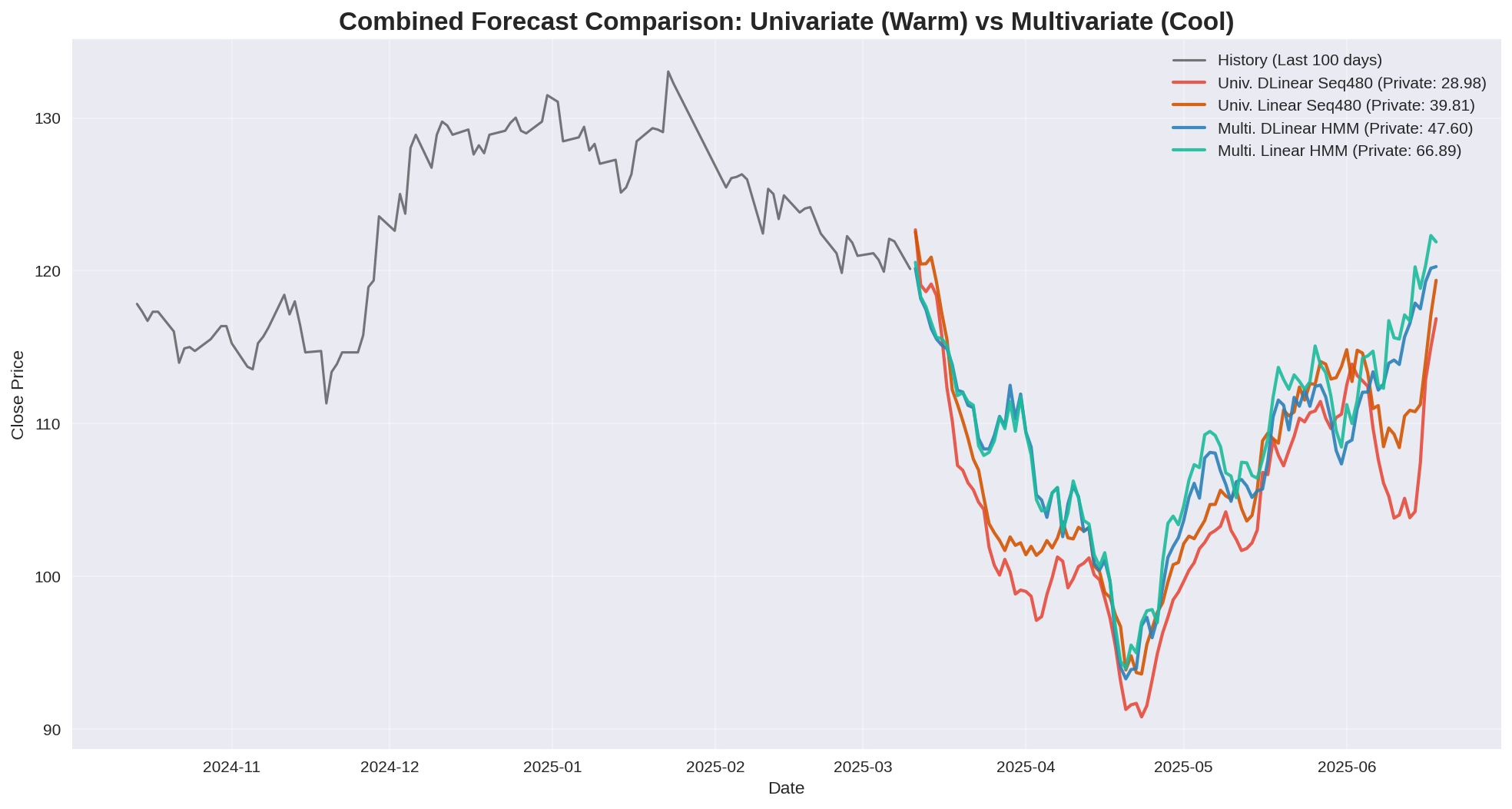
Hình 21. So sánh tổng hợp: Univariate vs Multivariate.
Phân tích kết quả chi tiết
1. Cuộc chiến Sequence Length: Seq480 (Long) vs Seq60 (Short)
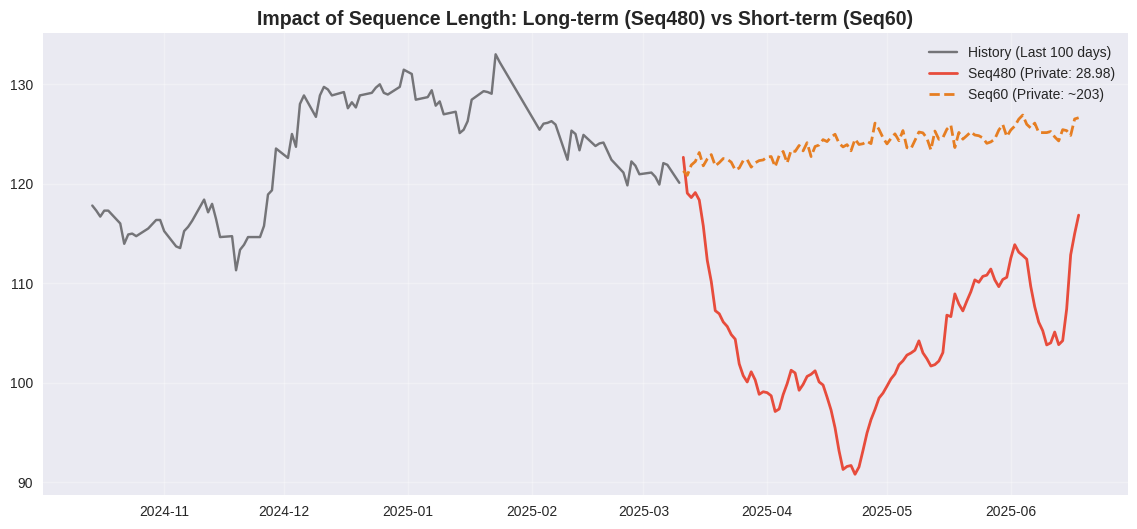
Hình 22. Impact của Sequence Length.
- Univariate Seq480 (Đỏ - Best): Nhờ nhìn được lịch sử dài (480 ngày ~2 năm), model nắm bắt được xu hướng dài hạn (long-term trend) của FPT. Đường dự báo đầm, chắc chắn và bám sát xu hướng tăng trưởng.
- Univariate Seq60 (Cam - Overfit): Chỉ nhìn 60 ngày (khoảng 3 tháng), model bị "cuốn" theo các biến động ngắn hạn (noise). Kết quả là Private Score cực tệ (~203 MSE) do overfitting vào dữ liệu train gần nhất.
Kết luận: Với bài toán dự báo dài hạn (100 ngày), việc sử dụng input sequence đủ dài (Look-back window lớn) quan trọng hơn nhiều so với việc dùng model phức tạp.
2. Cuộc chiến HMM: Có HMM vs Không HMM
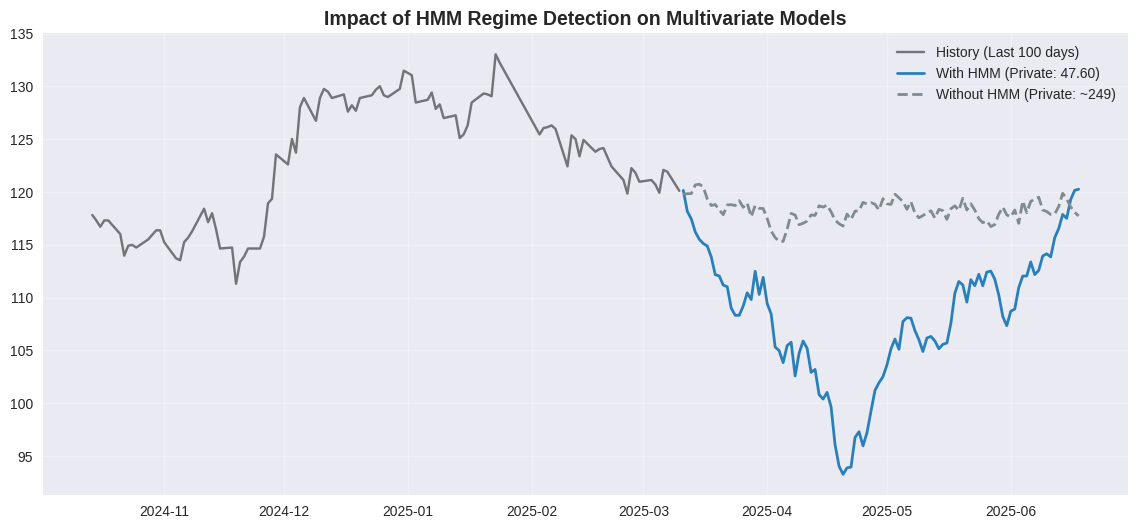
Hình 23. Impact của HMM trên Multivariate Models.
- Multivariate HMM (Xanh - Stable): Khi dùng nhiều biến (đa biến), dữ liệu trở nên rất nhiễu. HMM giúp phân cụm nhiễu bằng cách chia thị trường thành các regimes (Stable vs Volatile). Nhờ đó forecast (đường xanh) ổn định hơn, Private Score 47.60.
- Multivariate NoHMM (Xám - Volatile): Nếu không có HMM, model đa biến bị nhiễu loạn bởi các tín hiệu conflicting từ nhiều features. Kết quả dự báo (đường xám) đi lệch hẳn, Private Score tệ (~249).
Kết luận: Nếu dùng Multivariate, HMM là bắt buộc để kiểm soát nhiễu. Tuy nhiên, ngay cả khi có HMM, performance vẫn thua Univariate đơn giản.
Phân tích Insight
- Input Sequence Length (Seq Len): Độ dài đầu vào lớn (480 ngày $\approx$ 2 năm) cho kết quả tốt hơn hẳn so với ngắn hạn (60 ngày). Lý do là mô hình học được xu hướng dài hạn và ít bị nhiễu bởi các biến động ngắn hạn.
- Univariate vs Multivariate: Mô hình đơn biến (chỉ dùng
close) hoạt động ổn định hơn. Việc thêm nhiều biến (multivariate) trong bài toán này gây ra nhiễu nhiều hơn là thêm thông tin hữu ích. - Vai trò của HMM: Đối với mô hình Multivariate, việc áp dụng HMM giúp giảm sai số (MSE giảm từ \~249 xuống \~56). Điều này chứng minh việc phân chia dữ liệu theo trạng thái giúp mô hình tránh bị xung đột khi học các quy luật khác nhau.
VI. Kết luận
Dự án đã chứng minh tính hiệu quả của các mô hình tuyến tính đơn giản kết hợp với xử lý dữ liệu thông minh trong bài toán dự báo tài chính.
Các điểm chính:
- Univariate DLinear với cửa sổ lịch sử dài (480 ngày) là cấu hình hiệu quả nhất.
- HMM Regime-Switching là kỹ thuật hữu ích để cải thiện hiệu suất cho các mô hình đa biến.
- Chỉ số Train MSE thấp không đảm bảo kết quả dự báo tốt; cần cẩn trọng với overfitting.
Trong tương lai, giải pháp có thể được cải thiện bằng cách tích hợp thêm các dữ liệu vĩ mô (Macroeconomics), tin tức (Sentiment Analysis) để xử lý tốt hơn các điểm đảo chiều xu hướng hoặc tăng cường khả năng nhận diện Market Regime bằng cách cải thiện thêm các feature cho HMM thay vì chỉ 3 feature cơ bản.
Chưa có bình luận nào. Hãy là người đầu tiên!