
I. Giới thiệu về Làm sạch và Tiền xử lý Dữ liệu

Hình 1. Làm sạch dữ liệu
1. Tầm quan trọng của việc Làm sạch và Tiền xử lý Dữ liệu
-
Làm sạch dữ liệu và tiền xử lý dữ liệu là hai quá trình, công đoạn thiết yếu cũng như tốn nhiều thời gian nhất trong một quy trình khoa học dữ liệu. Bởi dữ liệu thực mà ta thu thập được thường sẽ rất lộn xộn cũng như thiếu nhiều nơi. Theo nguyên tắc garbage in, garbage out thì việc đưa dữ liệu kém chất lượng vào các mô hình dự đoán chắc chắn cũng sẽ làm giảm đi độ chính xác của chúng.
-
Vì vậy, bằng cách tinh chỉnh những dữ liệu thô thành một định dạng có cấu trúc và dễ sử dụng hơn, ta có thể phân tích dữ liệu một cách chính xác. Bởi chất lượng của dữ liệu đầu vào quyết định trực tiếp đến chất lượng của kết quả phân tích. Vì vậy việc đầu tư một lượng thời gian lớn cho khâu chuẩn bị dữ liệu sẽ giúp ta tránh được những kết quả sai, tránh việc xây dựng mô hình không hiệu quả.
2. Quy trình Làm sạch và Tiền xử lý Dữ liệu
- Một quy trình làm sạch và tiền xử lý dữ liệu thường sẽ có những bước sau:
-
Thu thập dữ liệu: Tập hợp dữ liệu thô từ nhiều nguồn khác nhau, chẳng hạn như cơ sở dữ liệu, API, cào dữ liệu web, hoặc nhập thủ công.
-
Làm sạch dữ liệu: Xử lý dữ liệu đã thu thập bằng cách phát hiện và sửa lỗi, loại bỏ các bản ghi trùng lặp hoặc không liên quan, và xử lý các giá trị bị khuyết.
-
Tích hợp dữ liệu: Gộp dữ liệu từ nhiều nguồn thành một cấu trúc thống nhất và giải quyết các điểm thiếu nhất quán.
-
Biến đổi dữ liệu: Chuyển đổi dữ liệu sang định dạng phù hợp để phân tích. Việc này bao gồm mã hóa các biến phân loại, chuẩn hóa các đặc trưng số và tạo ra các đặc trưng mới.
-
Giảm thiểu dữ liệu: Giảm số chiều dữ liệu nếu cần thiết. Việc này bao gồm trích xuất và chọn lọc đặc trưng để chỉ tập trung vào các biến số quan trọng nhất.
- Quá trình này sẽ lặp đi lặp lại và bạn sẽ thường xuyên phải quay lại các bước này trong quá trình học và làm data.
3. Các thư viện python phổ biến cho việc làm sạch và tiền xử lý dữ liệu
-
Python rất được ưa chuộng đối với các nhà khoa học dữ liệu bởi sự tiện dụng cùng với hệ sinh thái các thư viện hỗ trợ phong phú. Hai thư viện cốt lõi cho việc làm sạch dữ liệu là Pandas và Numpy.
-
Bên cạnh đó, các thư viện thiết yếu khác giúp hỗ trợ quá trình này gồm Matplotlib và Seaborn giúp trực quan hóa dữ liệu, Scikit-learn để tiền xử lý và học máy, cùng với Missingno chuyên dùng để xử lý các giá trị bị trống.
- Pandas: cung cấp những cấu trúc dữ liệu và công cụ cần thiết để làm việc với dữ liệu. Giúp người dùng dễ dàng lọc, sắp xếp, tổng hợp, làm sạch dữ liệu.
# cài đặt thư viện pandas
import pandas as pd
# đọc file CSV thành DataFrame trong pandas
df = pd.read_csv('Ten_file_cua_ban.csv')
# hiển thị những dòng đầu
df.head()
- Numpy: cung cấp các công cụ để tính toán số học, cung cấp mảng với tốc độ cao cũng như những công cụ chuyên sâu để thao tác trên mảng này.
# Cài đặt thư viện Numpy
import numpy as np
# Tạo mảng trong numpy
arr = np.array([1, 2, 3, 4, 5])
# Thực hiện phép toán trên từng phần tử
arr2 = arr * 2
- Matplotlib: là thư viện giúp vẽ biểu đồ, có khả năng tạo nhiều loại biểu đồ khác nhau như biểu đồ đường, cột,... Là nền tảng của việc trực quan hóa dữ liệu thường dùng cho quá trình phân tích dữ liệu khám phá EDA (Exploratory Data Analysis).
# Cài đặt thư viện Matplotlib
import matplotlib.pyplot as plt
# Tạo biểu đồ đường đơn giản
plt.plot([1, 2, 3, 4, 5])
plt.title("Simple Line Plot")
plt.xlabel("x-axis")
plt.ylabel("y-axis")
plt.show()
Hình 2. Biểu đồ đường đơn giản bằng thư viện Matplotlib
- Seaborn: Thư viện trực quan hóa dữ liệu được xây dựng trên nền tảng của Matplotlib. Nó cung cấp một giao diện bậc cao giúp người dùng dễ dàng vẽ các đồ thị thống kê đẹp mắt và mang tính thông tin cao.
# cài đặt thư viện Seaborn
import seaborn as sns
# Tải một tập dữ liệu mẫu từ thư viện seaborn
df = sns.load_dataset('tips')
# Tạo một biểu đồ phân phối tần suất
sns.histplot(df['total_bill'])
plt.title("Histogram of Total Bill")
plt.show()
Hình 3. Biểu đồ tần suất (Histogram)
5. Scikit-learn: Nó cung cấp đa dạng các thuật toán học có giám sát và không giám sát. Thêm vào đó, thư viện này còn bao gồm nhiều công cụ thiết yếu để huấn luyện mô hình, tiền xử lý dữ liệu, lựa chọn cũng như đánh giá mô hình, cùng rất nhiều tiện ích hỗ trợ hữu ích khác.
# Cài đặt thư viện Scikit-learn
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Tải lên dataset iris
iris = datasets.load_iris()
# Tạo mảng tính năng và mục tiêu
X = iris.data
y = iris.target
# Tách thành tập train và test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Khởi tạo mô hình phân loại Rừng ngẫu nhiên (RandomForestClassifier) và huấn luyện mô hình
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
# Dự đoán kết quả trên tập dữ liệu kiểm tra
y_pred = clf.predict(X_test)
# Kiểm tra độ chính xác mô hình
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
- Missingno: cung cấp khả năng trực quan hóa sự phân bố của các giá trị bị khuyết. Tính năng này có thể đặc biệt hữu ích trong quá trình làm sạch dữ liệu, giúp bạn dễ dàng nhận diện và xử lý những phần thông tin bị thiếu hụt.
# Cài đặt thư viện missingno
import missingno as msno
import pandas as pd
import numpy as np
# Tạo dataframe mẫu với giá trị bị khuyết
df = pd.DataFrame({
'Column1': [1, np.nan, 3, 4, 5],
'Column2': [np.nan, np.nan, 7, 8, 9],
'Column3': [10, 11, np.nan, np.nan, np.nan]
})
# Trực quan hóa giá trị bị khuyết
msno.matrix(df)
plt.show()

Hình 4. Minh họa ma trận Missingno
- Mỗi thư viện kể trên đều cung cấp một bộ công cụ mạnh mẽ phục vụ cho các khía cạnh khác nhau cho việc làm sạch, tiền xử lý và phân tích dữ liệu.
II. Hiểu về các vấn đề chất lượng dữ liệu
Khi bước vào thế giới khoa học dữ liệu, một thực tế quan trọng mà chúng ta phải chấp nhận là hiếm khi nào ta bắt gặp những tập dữ liệu đã được làm sạch và chuẩn bị hoàn hảo. Thường thì, các tập dữ liệu ban đầu của chúng ta sẽ chứa đầy rẫy những vấn đề về chất lượng. Chương này sẽ đi sâu vào việc nhận diện các vấn đề chất lượng dữ liệu phổ biến, đánh giá chất lượng và tính toàn vẹn của dữ liệu, sử dụng phân tích dữ liệu khám phá (EDA) trong quá trình đánh giá chất lượng, cũng như cách xử lý các dữ liệu trùng lặp và dư thừa.
Nhận diện các vấn đề chất lượng dữ liệu phổ biến
- Dữ liệu bị khuyết: Tình trạng này phát sinh do nhiều nguyên nhân khác nhau, chẳng hạn như lỗi của con người trong quá trình nhập liệu, trục trặc trong quy trình thu thập dữ liệu, hoặc trong những trường hợp mà một số trường thông tin nhất định không thể áp dụng được. Đây có lẽ là vấn đề về chất lượng dữ liệu phổ biến nhất. Tùy vào nguyên nhân xuất hiện, các giá trị bị khuyết có thể dẫn đến các phân tích sai lệch hoặc xảy ra bias. Vì vậy, xử lý đúng cách các giá trị khuyết là một bước cực kỳ quan trọng để duy trì tính chính xác cho mô hình của bạn.
# Cài đặt thư viện cần thiết
import pandas as pd
# Tải lên dataset của bạn
df = pd.read_csv('Ten_file_cua_ban.csv')
# Kiểm tra các giá trị bị khuyết trong mỗi cột
missing_values = df.isnull().sum()
print(missing_values)
- Giá trị ngoại lai: Là những điểm dữ liệu có sự khác biệt đáng kể so với các điểm dữ liệu còn lại trong tập. Có thể xuất hiện do lỗi đo lường, nhập dữ liệu hoặc cũng có thể là những quan sát hoàn toàn hợp lệ nhưng mang giá trị cực đoan. Từ đó gây ảnh hưởng lớn đến kết quả phân tích dữ liệu vì vậy để nhận dạng và xử lý nó là vô cùng quan trọng.
# Cài đặt thư viện cần thiết
import seaborn as sns
import matplotlib.pyplot as plt
# Trực quan hóa giá trị ngoại lai sử dụng biểu đồ hộp
sns.boxplot(x=df['cot_cua_ban'])
plt.show()
Biểu đồ hộp trực quan hóa giá trị nhỏ nhất, các tứ phân vị, giá trị lớn nhất của dữ liệu từ đó thấy sự phân tán của dữ liệu cũng như thấy được các giá trị ngoại lai.
- Định dạng không nhất quán: là một vấn đề chất lượng phổ biến phát sinh do lỗi của con người, sự thay đổi của hệ thống hoặc khi gộp dữ liệu từ nhiều nguồn khác nhau.
# Ví dụ: chuyển một cột với các giá trị số được lưu dạng chuỗi thành dạng số
df['numeric_column'] = pd.to_numeric(df['numeric_column'], errors='coerce')
Câu lệnh này chuyển đổi các giá trị trong cột numeric column sang định dạng số. Nó sẽ chuyển các giá trị không phải là số thành giá trị khuyết NaN qua đó giúp duy trì tính toàn vẹn của dữ liệu.
- Đánh giá Chất lượng và Tính toàn vẹn của Dữ liệu: Dữ liệu chất lượng cao là dữ liệu đầy đủ, chính xác và có định dạng nhất quán. Ngược lại, dữ liệu kém chất lượng lại chứa đầy rẫy các lỗi sai, giá trị bị khuyết và sự thiếu đồng nhất. Chất lượng dữ liệu ảnh hưởng trực tiếp đến sự phân tích của bạn cũng như mô hình dự đoán. Do đó, đánh giá chất lượng dữ liệu là một bước sơ bộ bắt buộc phải thực hiện trước khi tiến hành bất kỳ phân tích hay tiền xử lý nào.
Một công cụ đơn giản nhưng vô cùng mạnh mẽ để đánh giá chất lượng dữ liệu là sử dụng thống kê mô tả (descriptive statistics). Đây là các thước đo cung cấp cái nhìn tổng quan về xu hướng hướng tâm, độ phân tán và sự phân bố của dữ liệu.
# Sử dụng pandas để mô tả tập dữ liệu, giúp ta đánh giá sơ bộ về chất lượng dữ liệu
df.describe()
- Phân tích Dữ liệu Khám phá (EDA) để Đánh giá Chất lượng Dữ liệu: Là phương pháp tiếp cận để phân tích các tập dữ liệu để tóm tắt các điểm chính của chúng, thường sử dụng các biểu đồ thống kê và các phương pháp trực quan hóa dữ liệu khác. Đây là bước then chốt để tiến hành các bước quan trọng tiếp theo như xây mô hình, đưa ra dự đoán.
Một trong những khía cạnh quan trọng của EDA là khám phá trực quan. Việc trực quan hóa dữ liệu có thể mang lại một góc nhìn mới cho dữ liệu. Ví dụ, biểu đồ phân phối tần suất có thể cung cấp một bức tranh tổng thể, nhanh chóng về sự phân bố dữ liệu của bạn.
# Biểu đồ phân phối tần suất cho tất cả các cột số trong dataset
df.hist(bins=50, figsize=(20, 15))
plt.show()
Biểu đồ phân phối tần suất có thể mang lại những thông tin quan trọng về bản chất của dữ liệu. Một biểu đồ dạng chuông và đối xứng có thể là dấu hiệu cho thấy dữ liệu phân phối chuẩn. Ngược lại, một biểu đồ bị lệch chứng tỏ dữ liệu có các dữ liệu ngoại lai.
- Xử lý dữ liệu trùng lặp và dư thừa: Là hai vấn đề khác nhau có thể len lỏi vào tập dữ liệu của bạn. Dữ liệu trùng lặp là những dữ liệu y hệt nhau trong dữ liệu. Chúng có thể làm sai lệch kết quả phân tích và dẫn đến những kết luận không chính xác. Dữ liệu dư thừa là những dữ liệu không mang lại thêm bất kỳ thông tin mới nào. Mặc dù không gây hại trực tiếp như dữ liệu trùng lặp, nhưng chúng có thể làm chậm quá trình tính toán của máy tính và chiếm dụng không gian lưu trữ một cách không cần thiết.
# Kiểm tra những hàng bị trùng lặp
duplicate_rows = df.duplicated()
# Đếm số hàng bị trùng lặp
print(f"Number of duplicate rows: {duplicate_rows.sum()}")
# Xóa các giá trị trùng lặp
df = df.drop_duplicates()
# Kiểm tra hình dạng của dữ liệu sau khi xóa
print("Shape of DataFrame After Removing Duplicates:", df.shape)
- Việc xử lý dữ liệu trùng lặp và dư thừa là một phần không thể thiếu trong quá trình làm sạch dữ liệu và đóng vai trò vô cùng quan trọng để duy trì tính toàn vẹn cho các bài phân tích của bạn.
III. Xử lý dữ liệu bị thiếu
Dữ liệu bị thiếu là một vấn đề thường gặp mà các nhà khoa học dữ liệu phải đối mặt. Việc hiểu rõ cách nhận diện và xử lý những khoảng trống này là vô cùng quan trọng, bởi vì chúng có thể mang lại sự thiên lệch hoặc những sai sót vào trong các bài phân tích của bạn. Chúng ta cũng sẽ đi sâu vào một số kỹ thuật xử lý dữ liệu khuyết dành cho những dữ liệu.
1. Nhận diện và hiểu những dữ liệu bị khuyết
- Việc nhận diện dữ liệu bị khuyết nghe có vẻ đơn giản, bạn chỉ cần tìm những khoảng trống. Nhưng với dữ liệu thực tế, mọi chuyện hiếm khi dễ dàng như vậy. Dữ liệu khuyết có thể tồn tại dưới nhiều hình thức khác nhau, từ những ô trống rõ ràng cho đến các giá trị thay thế như
"N/A"hoặc"-999", hay thậm chí là dữ liệu bị nhập sai. Hãy cùng thảo luận về cách nhận diện chúng bằng Python.
# Nhập thư viện cần thiết
import pandas as pd
# Kiểm tra giá trị bị thiếu
missing_value = df.isnull().sum()
print(missing_value)
Đoạn mã này in ra số lượng các giá trị bị khuyết trong từng cột, mang lại cái nhìn tổng quan ban đầu về mức độ cũng như sự phân bố của tình trạng thiếu hụt dữ liệu trong tập dữ liệu của bạn.
Việc thấu hiểu dữ liệu khuyết cũng đòi hỏi chúng ta phải nắm được các phân loại của nó. Trong thống kê học, dữ liệu khuyết thường được chia thành ba loại:
-
Khuyết hoàn toàn ngẫu nhiên (MCAR - Missing Completely at Random): Việc dữ liệu bị khuyết không hề liên quan đến bất kỳ biến số nào khác trong tập dữ liệu. Nó chỉ đơn thuần là ngẫu nhiên.
-
Khuyết ngẫu nhiên (MAR - Missing at Random): Việc một biến số bị khuyết có liên quan đến một vài biến số khác trong tập dữ liệu, nhưng không liên quan đến chính bản thân biến số bị khuyết đó.
-
Khuyết không ngẫu nhiên (MNAR - Missing Not at Random): Việc một biến bị khuyết có liên quan trực tiếp đến chính giá trị của biến đó.
Loại dữ liệu khuyết sẽ đóng vai trò định hướng giúp bạn lựa chọn kỹ thuật xử lý tối ưu nhất.
2. Kỹ thuật để xử lý dữ liệu khuyết
- Xóa: Đây là phương pháp đơn giản nhất, bao gồm việc xóa bỏ hoàn toàn các dữ liệu có chứa giá trị bị khuyết. Tuy nhiên, cách làm này chỉ được khuyến khích sử dụng khi dữ liệu của bạn thuộc loại MCAR và lượng dữ liệu bị khuyết chỉ chiếm một tỷ lệ rất nhỏ so với tổng thể tập dữ liệu. Dưới đây là cách để thực hiện điều đó với thư viện pandas:
# Xóa các cột với giá trị bị khuyết
df.dropna(inplace=True)
-
Điền khuyết dữ liệu: là quá trình thay thế các dữ liệu còn thiếu bằng các giá trị thay thế, những cách để thực hiện việc này là:
-
Điền khuyết bằng Giá trị Trung bình / Trung vị / Yếu vị: thay thế các giá trị bị khuyết bằng giá trị trung bình (đối với dữ liệu liên tục), trung vị (đối với dữ liệu có thứ bậc), hoặc yếu vị/giá trị xuất hiện nhiều nhất (đối với dữ liệu phân loại). Tuy nhiên, phương pháp này có thể làm giảm phương sai của tập dữ liệu và làm ảnh hưởng đến sự tương quan với các biến số khác.
# Điền khuyết bằng giá trị trung bình
df.fillna(df.mean(), inplace=True)
- Điền khuyết bằng hằng số: thay thế các giá trị bị khuyết bằng một hằng số cố định. Cách này có thể trở nên hữu ích khi bạn có đủ cơ sở kiến thức chuyên môn để đưa ra phỏng đoán cho các giá trị bị thiếu.
# Điền khuyết bằng hằng số cố định
df.fillna(0, inplace=True)
- Điền khuyết bằng mô hình dự đoán: sử dụng mô hình thống kê hoặc các thuật toán học máy để dự đoán giá trị bị khuyết dựa trên các dữ liệu khác có sẵn. Dù cách này mang lại độ chính xác cao nhưng đổi lại là độ phức tạp lớn hơn.
# Điền khuyết bằng mô hình dự đoán sử dụng Hồi quy tuyến tính
from sklearn.linear_model import LinearRegression
# Tách dữ liệu thành 2 tập: tập có chứa giá trị khuyết và tập không chứa giá trị khuyết
missing = df[df['A'].isnull()]
not_missing = df[df['A'].notnull()]
# Khởi tạo mô hình
model = LinearRegression()
# Huấn luyện mô hình (sử dụng các cột khác để học quy luật dự đoán cột 'A')
model.fit(not_missing.drop('A', axis=1), not_missing['A'])
# Dự đoán các giá trị bị khuyết
predicted = model.predict(missing.drop('A', axis=1))
# Điền các giá trị vừa dự đoán được vào các vị trí bị trống trong dữ liệu ban đầu
df.loc[df['A'].isnull(), 'A'] = predicted
3. Giới thiệu về pandas trong xử lý dữ liệu khuyết
- Như các ví dụ ở trên, pandas là một thư viện vô cùng mạnh mẽ để xử lý dữ liệu bị khuyết. Các phương thức
isnull()vànotnull()rất hữu ích trong việc nhận diện dữ liệu khuyết. Phương thứcfillna()giúp lấp đầy các khoảng trống dữ liệu. Bạn đã thấy nó được sử dụng cho việc điền bằng hằng số và giá trị trung bình, nhưng nó còn linh hoạt hơn thế nhiều. Ví dụ: bạn có thể điền các giá trị bị khuyết bằng giá trị hợp lệ liền trước đó trong chuỗi (sử dụng tham số method="ffill" - Forward Fill) hoặc giá trị hợp lệ liền sau nó (sử dụng tham số method="bfill" - Backward Fill).
# Lấp đầy giá trị khuyết bằng giá trị đằng sau
df.fillna(method='ffill', inplace=True)
# Lấp đầy giá trị khuyết bằng giá trị đằng trước
df.fillna(method='bfill', inplace=True)
Các kỹ thuật xử lý giá trị bị khuyết nâng cao: Có thể được áp dụng khi bạn cần xem xét các mối tương quan giữa các đặc trưng hoặc dữ liệu của bạn có thể chứa nhiều giá trị bị khuyết nằm rải rác ở các bảng ghi khác nhau.
- Điền khuyết đa biến: là một kỹ thuật thống kê để xử lý dữ liệu khuyết, trong đó giá trị bị thiếu được ước lượng nhiều lần. Quá trình này tạo ra nhiều tập dữ liệu hoàn chỉnh, mỗi tập dữ liệu sẽ được phân tích riêng biệt, và các kết quả sẽ được gộp lại với nhau để tạo ra một kết quả cuối cùng duy nhất. Phương pháp phổ biến nhất là điền khuyết đa biến bằng Phương trình Chuỗi (MICE - Multivariate Imputation by Chained Equations). Phương pháp này có tính đến sự bất định xung quanh các giá trị bị khuyết.
# Điền khuyết đa biến bằng phương trình chuỗi
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
# Khởi tạo công cụ điền khuyết MICE
mice_imputer = IterativeImputer()
# Áp dụng công cụ
df_imputed = mice_imputer.fit_transform(df)
- Điền khuyết bằng mô hình dự đoán: sử dụng các mô hình học máy để dự đoán các giá trị bị khuyết. Mặc dù một mô hình hồi quy tuyến tính có thể là đủ, trong một vài tình huống những cách khác như dùng cây quyết định, rừng ngẫu nhiên hay mạng nơ-ron mang lại hiệu quả tốt hơn tùy thuộc vào độ phức tạp của dữ liệu của bạn.
# Điền khuyết bằng mô hình dự đoán sử dụng thuật toán Rừng ngẫu nhiên
from sklearn.ensemble import RandomForestRegressor
# Chuẩn bị dữ liệu: Tách tập có chứa giá trị khuyết và tập không chứa giá trị khuyết
missing = df[df['A'].isnull()]
not_missing = df[df['A'].notnull()]
# Khởi tạo mô hình (Thiết lập 100 cây quyết định để dự đoán)
model = RandomForestRegressor(n_estimators=100, random_state=0)
# Huấn luyện mô hình (Học quy luật từ các dữ liệu đã có)
model.fit(not_missing.drop('A', axis=1), not_missing['A'])
# Dự đoán các giá trị bị khuyết
predicted = model.predict(missing.drop('A', axis=1))
# Điền các giá trị vừa dự đoán được vào các ô trống trong DataFrame gốc
df.loc[df['A'].isnull(), 'A'] = predicted
IV. Xử lý các giá trị ngoại lai
1. Giá trị ngoại lai
Là các quan sát bất thường, có giá trị khác biệt rất lớn (quá nhỏ hoặc quá lớn) so với phần còn lại của tập dữ liệu. Chúng thường xuất hiện do biến động tự nhiên hoặc do lỗi đo đạc/nhập liệu. Mặc dù các giá trị ngoại lệ đôi khi có thể chỉ ra những phát hiện quan trọng hoặc lỗi trong quá trình thu thập dữ liệu, chúng cũng có thể làm lệch dữ liệu và dẫn đến kết quả sai lệch.
Hiểu rõ về chúng là điều cực kỳ quan trọng vì sự hiện diện của chúng có thể gây ra những ảnh hưởng đáng kể đến quá trình phân tích dữ liệu. Chúng có thể:
-
Ảnh hưởng đến Giá trị Trung bình (Mean) và Độ lệch chuẩn (Standard Deviation): Các giá trị ngoại lệ có thể làm lệch đáng kể giá trị trung bình và làm tăng vọt độ lệch chuẩn, từ đó làm biến dạng tổng thể phân phối của dữ liệu.
-
Tác động đến Độ chính xác của Mô hình: Nhiều thuật toán học máy (machine learning) rất nhạy cảm với phạm vi và sự phân phối của các giá trị thuộc tính. Các giá trị ngoại lệ có thể làm sai lệch quá trình huấn luyện, dẫn đến thời gian huấn luyện lâu hơn và các mô hình kém chính xác hơn.
2. Các kỹ thuật phát hiện giá trị ngoại lai
Việc phát hiện ngoại lệ có thể được thực hiện bằng một vài phương pháp, mỗi phương pháp đều có những ưu điểm và hạn chế riêng. Dưới đây là một số phương pháp phổ biến:
Các phương pháp thống kê
- Z-score: Chỉ số Z-score là thước đo cho biết một quan sát cách giá trị trung bình bao nhiêu lần độ lệch chuẩn.
Trong một phân phối chuẩn lý tưởng:
- Khoảng [-1, 1]: Chứa khoảng 68% dữ liệu.
- Khoảng [-2, 2]: Chứa khoảng 95% dữ liệu.
- Khoảng [-3, 3]: Chứa khoảng 99.7% dữ liệu.
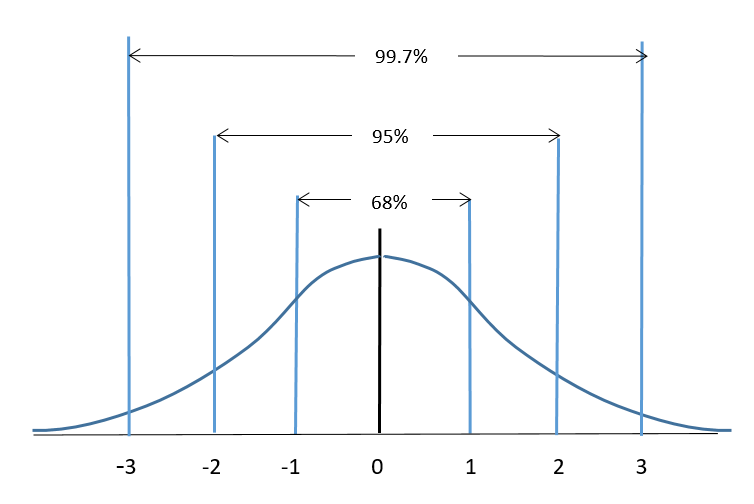
Hình 5. Phân phối chuẩn lý tưởng
Lưu ý: Một quy tắc kinh nghiệm phổ biến là một điểm dữ liệu có giá trị Z-score lớn hơn 3 hoặc nhỏ hơn -3 thì được coi là một giá trị ngoại lệ.
- Phương pháp Khoảng biến thiên tứ phân vị (Interquartile Range - IQR): xác định các giá trị ngoại lệ là những điểm dữ liệu nằm dưới tứ phân vị thứ nhất hoặc nằm trên tứ phân vị thứ ba một khoảng bằng hệ số của IQR.
Biểu đồ hộp mô tả một số đặc trưng quan trọng của tập dữ liệu như tâm, độ phân tán, mức độ đối xứng và cũng là một cách để phát hiện các quan sát bất thường. Biểu đồ hộp cho biết 3 điểm tứ phân vị Q1, Q2, Q3, min, max trên một hộp chữ nhật.
Một cạnh của hình chữ nhật nằm tại vị trí tứ phân vị thứ nhất Q1, cạnh đối diện ở vị trí của điểm tứ phân vị thứ 3, Q3, khoảng tứ phân vị IQR = Q3 - Q1.
Từ điểm Q1 ta vẽ đoạn thẳng theo hướng đi ra hướng giá trị nhỏ nhất của dữ liệu với độ dài là 1,5 x IQR và từ điểm Q3 vẽ đoạn thẳng ra hướng giá trị lớn nhất của dữ liệu với độ dài là 1,5 x IQR (các đoạn thẳng này được gọi là "đuôi dưới" và "đuôi trên"). Các quan sát nằm ngoài hình chữ nhật và hai đuôi này được biểu diễn bằng các ký hiệu "o" đơn lẻ. Các điểm nằm ngoài hai đuôi được xem là các quan sát bất thường.
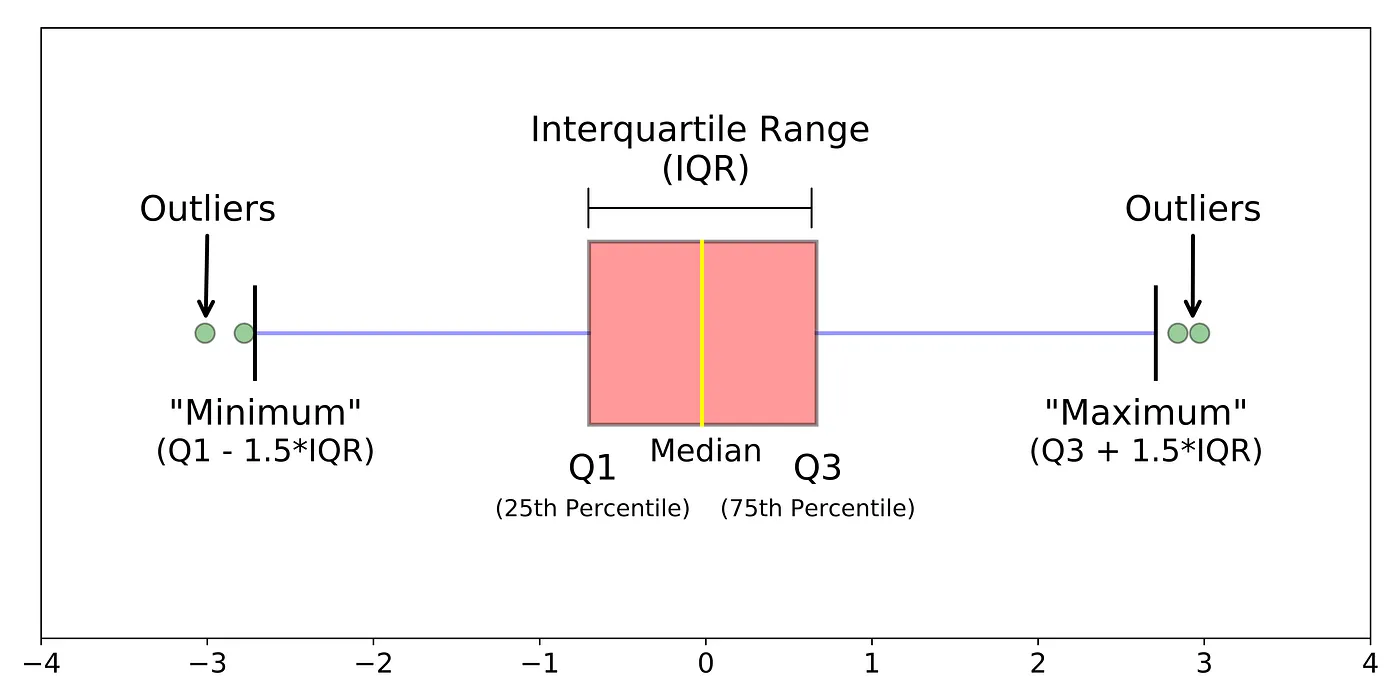
Hình 6. Phương pháp khoảng tứ phân vị (IQR)
- Trực quan hóa
Biểu đồ hộp (Box plots) và biểu đồ phân tán (Scatter plots) là những công cụ tuyệt vời để trực quan hóa và phát hiện các giá trị ngoại lệ.
-
Box plot: Xem lại mục trên
-
Scatter plot:
Khái niệm: Dữ liệu được hiển thị dưới dạng một tập hợp các điểm. Mỗi điểm có giá trị của một biến xác định vị trí trên trục hoành (trục X) và giá trị của biến còn lại xác định vị trí trên trục tung (trục Y).
Note: Trong biểu đồ phân tán, các giá trị ngoại lệ được thể hiện rất rõ ràng. Đó là những điểm nằm "lạc lõng", xa rời khỏi cụm hoặc xu hướng chung của các điểm dữ liệu còn lại.
import matplotlib.pyplot as plt
# Dữ liệu minh họa
x = [5,7,8,7,2,17,2,9,4,11,12,9,6] # tuổi của xe
y = [99,86,87,88,111,150,138,87,94,78,77,85,86] # tốc độ của mỗi xe
# Tạo khung hình với 1 hàng và 2 cột
plt.figure(figsize=(12, 5))
# 1. Vẽ Scatter Plot (Biểu đồ phân tán)
plt.subplot(1, 2, 1)
plt.scatter(x, y)
plt.title("Scatter Plot")
plt.xlabel("tuổi xe")
plt.ylabel("tốc độ")
# 2. Vẽ Box Plot (Biểu đồ hộp) cho biến Tốc độ (y)
plt.subplot(1, 2, 2)
plt.boxplot(y)
plt.title("Box Plot")
plt.ylabel("tốc độ")
# Ghi chú: Box plot giúp thấy rõ điểm 150 là outlier
# Hiển thị
plt.tight_layout()
plt.show()
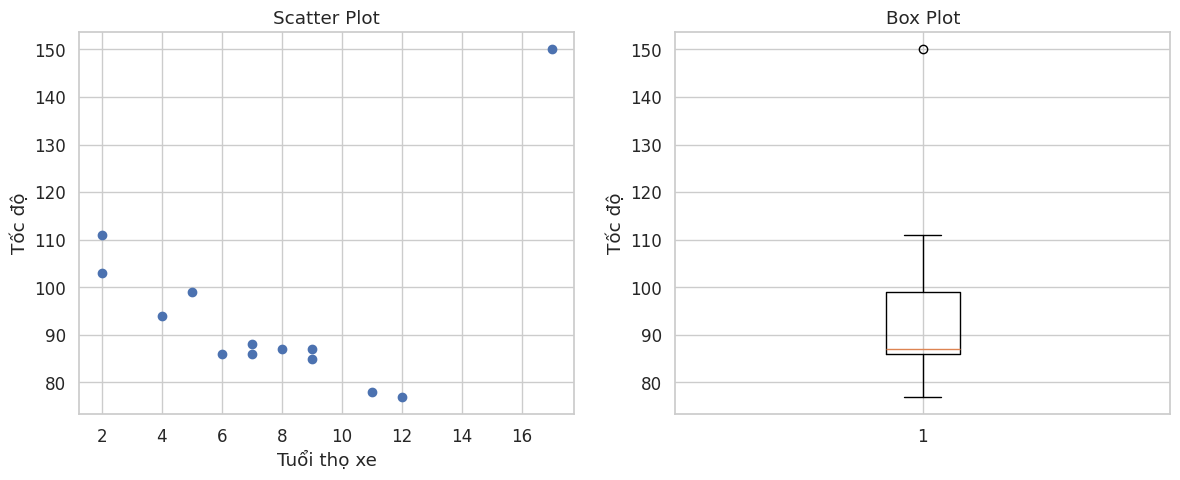
Hình 7. Minh họa phương pháp IQR
3. Các chiến lược xử lý ngoại lệ
Có một vài cách để xử lý các giá trị ngoại lệ, và phương pháp đúng đắn sẽ phụ thuộc vào bản chất của dữ liệu cũng như vấn đề cụ thể mà bạn đang giải quyết. Dưới đây là một số chiến lược phổ biến:
- Xóa bỏ
Xóa bỏ, hay loại bỏ, là cách đơn giản nhất để xử lý ngoại lệ, nhưng nó nên được sử dụng một cách thận trọng. Chỉ nên loại bỏ một giá trị ngoại lệ nếu chắc chắn rằng đó là do dữ liệu bị nhập sai hoặc do lỗi đo lường sai. Trong một số trường hợp, việc xóa các điểm dữ liệu có giá trị có thể dẫn đến mất mát thông tin và kết quả bị thiên lệch.
# Lọc bỏ các giá trị ngoại lệ
filtered_data = outlier_data[(z_scores <= 3)]
- Biến đổi
Biến đổi các biến số cũng có thể giúp giảm thiểu tác động của các giá trị ngoại lệ. Các phép biến đổi phổ biến bao gồm logarit (log), căn bậc hai (square root) và biến đổi nghịch đảo (inverse). Những phép toán này có thể nén các giá trị cao hơn, từ đó làm giảm ảnh hưởng của các giá trị cực đoan.
# Biến đổi nghịch đảo
transformed_data = 1 / data
- Phương pháp Winsorization
Trong một tập dữ liệu đã được Winsorized, các giá trị cực đoan được thay thế bằng các phân vị nhất định (thường là phân vị thứ 5 và thứ 95). Kỹ thuật này duy trì kích thước của tập dữ liệu, không giống như phương pháp xóa bỏ.
from scipy.stats.mstats import winsorize
# Áp dụng winsorization
winsorized_data = winsorize(outlier_data, limits=[0.05, 0.05])
- Các mô hình học máy
Một số mô hình học máy, như Random Forests và SVM, ít nhạy cảm hơn với các giá trị ngoại lệ. Sử dụng các mô hình này có thể là một chiến lược khả thi khi xử lý dữ liệu có chứa ngoại lệ.
V. Chuẩn hóa và thay đổi quy mô dữ liệu
Trong tiền xử lý dữ liệu, một bước thiết yếu là chuẩn hóa và thay đổi quy mô dữ liệu (Data Normalization and Scaling). Các kỹ thuật này giúp chúng ta tiêu chuẩn hóa phạm vi của các biến độc lập hoặc các đặc trưng (features) của dữ liệu.
1. Hiểu về tầm quan trọng của chuẩn hóa và thay đổi quy mô dữ liệu
Các thuật toán học máy hoạt động tốt hơn khi các biến số đầu vào nằm trong một quy mô tương tự nhau. Nếu không có chuẩn hóa hoặc thay đổi quy mô, các đặc trưng có giá trị lớn hơn có thể chiếm ưu thế trong kết quả của mô hình. Điều này có thể dẫn đến các kết quả sai lệch và một mô hình không nắm bắt được ảnh hưởng của các đặc trưng khác.
Chuẩn hóa và thay đổi quy mô đưa các đặc trưng khác nhau về cùng một quy mô, cho phép so sánh công bằng và đảm bảo rằng không có đặc trưng cụ thể nào lấn át các đặc trưng khác. Hơn nữa, các kỹ thuật này cũng có thể tăng tốc quá trình huấn luyện. Ví dụ, thuật toán gradient descent hội tụ nhanh hơn khi các đặc trưng nằm trên các quy mô tương tự nhau.
Hình 8. Ví dụ về phương pháp chuẩn hóa dữ liệu
Ví dụ: một thuộc tính như tuổi tác được vẽ theo tỷ lệ rất khác so với một thuộc tính như tiền lương. Thuộc tính tiền lương thường có độ lớn lớn hơn thuộc tính tuổi tác. Kết quả là, bất kỳ hàm tổng hợp nào được tính toán trên các thuộc tính khác nhau sẽ bị chi phối bởi thuộc tính có độ lớn lớn hơn.
Hình 9. Ví dụ về chuẩn hóa dữ liệu
2. Các kỹ thuật chuẩn hóa dữ liệu
Chuẩn hóa dữ liệu là một phương pháp để thay đổi giá trị của các cột có kiểu dữ liệu dạng số trong một tập dữ liệu về một quy mô chung. Dưới đây là một vài kỹ thuật chuẩn hóa:
- Min-max scaling:
Min-max scaling là một trong những phương pháp đơn giản nhất để chuẩn hóa dữ liệu. Nó thay đổi quy mô và dịch chuyển từng đặc trưng một cách riêng biệt sao cho giá trị nằm trong khoảng từ 0 đến 1.
Công thức:
- Min-max scaling:
$$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$
Trong đó:
- $x$: giá trị ban đầu
- $x_{min}$: giá trị nhỏ nhất của feature
- $x_{max}$: giá trị lớn nhất của feature
Ví dụ minh họa code:
from sklearn.preprocessing import MinMaxScaler
# Minh họa một tập dữ liệu đơn giản
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
3. Chuẩn hóa Z-score
Kỹ thuật này chuẩn hóa đặc trưng sao cho nó có giá trị trung bình (mean) bằng 0 và độ lệch chuẩn (standard deviation) bằng 1. Nó phân phối lại các đặc trưng với giá trị trung bình tại 0 và độ lệch chuẩn là 1.
Công thức:
- Chuẩn hóa Z-score (Standardization):
$$ x' = \frac{x - \mu}{\sigma} $$
Trong đó:
- $\mu$: giá trị trung bình (mean)
- $\sigma$: độ lệch chuẩn (standard deviation)
Ví dụ minh họa code:
from sklearn.preprocessing import StandardScaler
# Minh họa một tập dữ liệu đơn giản
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
4. Các kỹ thuật thay đổi quy mô đặc trưng
Thay đổi quy mô đặc trưng (Feature scaling) là một thuật ngữ chung cho các kỹ thuật làm thay đổi phạm vi của một đặc trưng. Ngoài các kỹ thuật chuẩn hóa đã đề cập trước đó, các phương pháp sau đây cũng được sử dụng để thay đổi quy mô đặc trưng:
- Robust scaling
Robust scaling tương tự như min-max scaling nhưng sử dụng khoảng tứ phân vị thay vì khoảng cực tiểu - cực đại, giúp nó ít nhạy cảm hơn với các giá trị ngoại lai.
Công thức:
- Robust Scaling (dựa trên IQR):
$$ x' = \frac{x - Q_1}{Q_3 - Q_1} $$
hoặc thường dùng:
$$ x' = \frac{x - \text{median}}{IQR} $$
Trong đó:
- $Q_1$: tứ phân vị thứ nhất
- $Q_3$: tứ phân vị thứ ba
- $IQR = Q_3 - Q_1$
- median: giá trị trung vị
Ví dụ minh họa code:
from sklearn.preprocessing import RobustScaler
# Minh họa một tập dữ liệu đơn giản
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
scaler = RobustScaler()
robust_scaled_data = scaler.fit_transform(data)
VI. Lựa chọn và trích xuất đặc trưng
Lựa chọn và trích xuất đặc trưng (Feature Selection and Extraction) là những bước then chốt trong quy trình tiền xử lý dữ liệu cho các dự án machine learning và khoa học dữ liệu. Những kỹ thuật này có thể tạo ra sự khác biệt giữa một mô hình hoạt động cực kỳ hiệu quả và một mô hình thất bại hoàn toàn.
Các kỹ thuật lựa chọn và trích xuất đặc trưng được sử dụng để giảm chiều (dimensionality) của dữ liệu, từ đó nâng cao hiệu quả tính toán và có khả năng cải thiện hiệu suất của mô hình.
1. Lựa chọn đặc trưng
Lựa chọn đặc trưng (Feature Selection) là quá trình chọn ra một tập con những đặc trưng quan trọng nhất và loại bỏ những đặc trưng còn lại để sử dụng trong việc xây dựng mô hình. Điều này quan trọng vì những lý do sau:
- Sự đơn giản: Ít đặc trưng hơn giúp mô hình trở nên đơn giản hơn và dễ giải thích hơn.
- Tốc độ: Ít dữ liệu hơn đồng nghĩa với việc các thuật toán huấn luyện nhanh hơn.
- Ngăn ngừa quá khớp (overfitting): Ít dữ liệu dư thừa hơn đồng nghĩa với việc ít có cơ hội đưa ra các quyết định dựa trên nhiễu hơn.
2. Trích xuất đặc trưng
Mặt khác, trích xuất đặc trưng (Feature Extraction) là quá trình biến đổi hoặc ánh xạ dữ liệu gốc có số chiều cao sang một không gian có số chiều thấp hơn. Khác với lựa chọn đặc trưng, nơi chúng ta giữ lại các đặc trưng gốc, trích xuất đặc trưng tạo ra các đặc trưng mới đại diện cho hầu hết các thông tin "hữu ích" trong dữ liệu gốc. Các lợi ích mang lại là:
- Giảm số chiều: Tương tự như feature selection, ít đặc trưng hơn giúp tăng tốc độ huấn luyện.
- Hiệu suất tốt hơn: Đôi khi, mô hình có thể học tốt hơn trong không gian đã được biến đổi.
3. Các kỹ thuật lựa chọn đặc trưng
Các phương pháp lựa chọn đặc trưng thường được phân thành ba loại: phương pháp filter, phương pháp wrapper và phương pháp embedded.
- Phương pháp filter
Đánh giá từng feature dựa trên mối quan hệ thống kê của nó với biến mục tiêu (output/label), rồi giữ lại những feature có điểm cao nhất. Các phương pháp tính điểm phổ biến: chi-squared test, information gain, correlation coefficient.
Cách hoạt động từng bước:
- Lấy toàn bộ features từ dữ liệu gốc
- Tính điểm số cho từng feature bằng một phép kiểm định thống kê để đo mức độ liên quan với biến mục tiêu (y)
- Xếp hạng features theo điểm, chọn top-k feature cao nhất
- Đưa những features đã lọc vào mô hình học máy
- Phương pháp wrapper
Khác biệt hoàn toàn so với phương pháp filter, thay vì dùng thống kê đơn thuần, chúng dùng chính mô hình học máy để đánh giá chất lượng của từng tập hợp features. Phương pháp wrapper coi việc chọn features như một bài toán tìm kiếm: thử nhiều tổ hợp features khác nhau, huấn luyện mô hình với mỗi tổ hợp, đo độ chính xác, rồi giữ tổ hợp tốt nhất. Hai kỹ thuật phổ biến nhất là Forward Selection và Recursive Feature Elimination.
- Phương pháp embedded
Là phương pháp "nhúng" quá trình chọn features vào bên trong quá trình huấn luyện mô hình, khác với filter (chọn features trước khi train) và wrapper (làm bên ngoài và độc lập với quá trình training, quá trình chọn tổ hợp và training diễn ra xen kẽ nhau).
Cơ chế chính là Regularization: thêm một "hình phạt" vào hàm mục tiêu của mô hình để nó tự động ép các hệ số của feature kém quan trọng về gần 0, hoặc về đúng 0. Hai kỹ thuật regularization bao gồm: Lasso và Ridge.
4. Các kỹ thuật trích xuất đặc trưng
Khác với ba phương pháp trước ở điểm cốt lõi: thay vì chọn đặc trưng (features) có sẵn, nó tạo ra đặc trưng (features) mới bằng cách kết hợp và biến đổi các features gốc. Kết quả là không gian dữ liệu được nén lại (ít chiều hơn) nhưng vẫn giữ được phần lớn thông tin. Các kỹ thuật giảm chiều dữ liệu phổ biến: PCA và t-SNE.
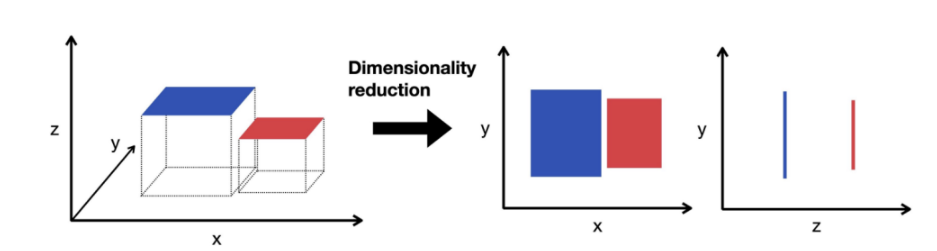
Hình 10. Ví dụ về giảm chiều dữ liệu
- PCA (Principal Component Analysis): tìm các trục mới (gọi là Principal Components) theo hướng dữ liệu phân tán nhiều nhất, rồi chiếu toàn bộ dữ liệu lên các trục đó. Ví dụ: từ 3 features ban đầu, PCA nén xuống còn 2 features mới (PC1, PC2) vẫn giữ được phần lớn thông tin.
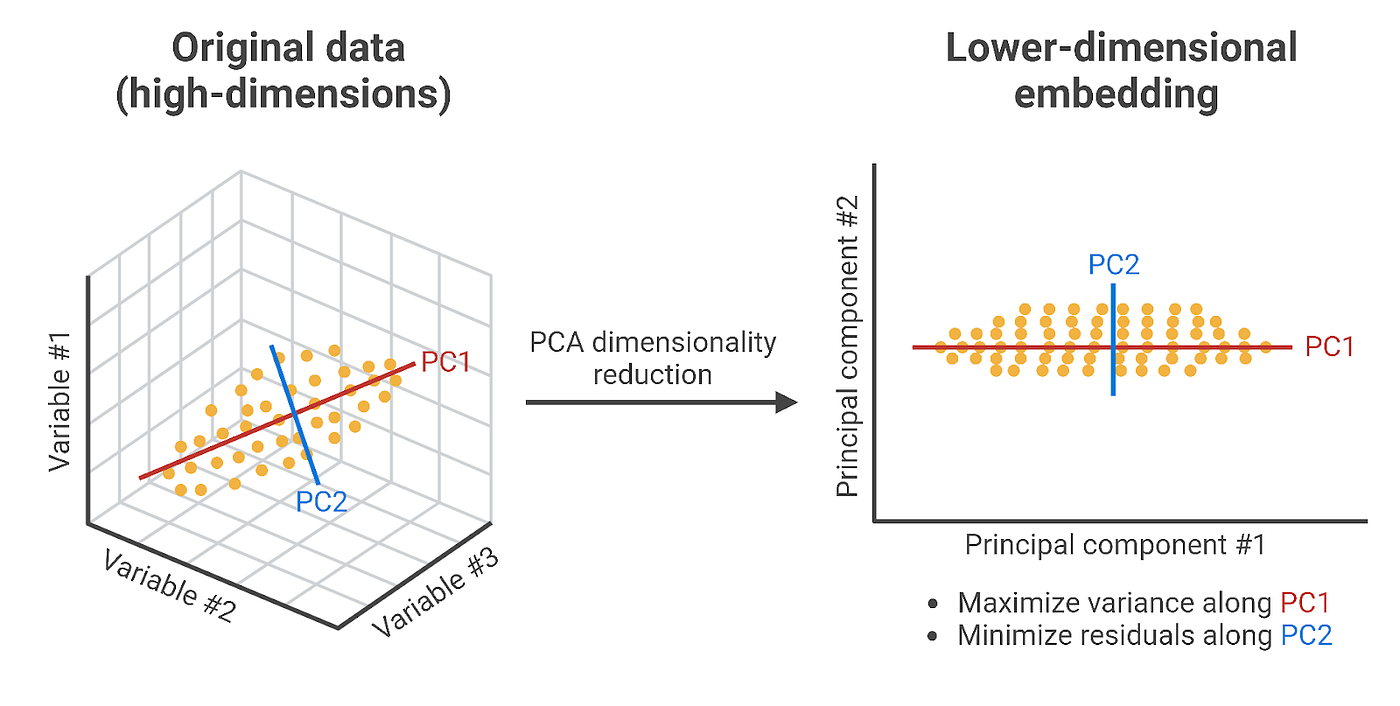
Hình 11. Giảm chiều dữ liệu bằng phương pháp thành phần chính
- t-SNE: hoạt động theo nguyên lý khác: nó cố gắng giữ nguyên mối quan hệ "láng giềng" giữa các điểm dữ liệu khi chiếu xuống không gian thấp hơn. Những điểm gần nhau trong không gian gốc sẽ vẫn ở gần nhau sau khi biến đổi, tạo ra các cụm (clusters) rất rõ ràng khi vẽ ra.

Hình 12. Phương pháp t-SNE
Lưu ý: t-SNE chỉ dùng để trực quan hóa, không dùng để huấn luyện model vì kết quả thay đổi mỗi lần chạy và không thể áp dụng lên dữ liệu mới.
VII. Mã hóa biến phân loại
Các biến phân loại là một dạng dữ liệu không phải số phổ biến, đóng vai trò quan trọng trong nhiều ứng dụng khoa học dữ liệu và học máy. Việc mã hóa dữ liệu phân loại là một bước quan trọng trong giai đoạn tiền xử lý dữ liệu. Trong mục này, chúng ta sẽ tìm hiểu biến phân loại là gì, những thách thức của chúng, các kỹ thuật mã hóa khác nhau, và cách xử lý các trường hợp có nhiều giá trị (high cardinality) và các danh mục hiếm.
1. Hiểu về biến phân loại và những thách thức
Biến phân loại biểu diễn các loại dữ liệu có thể được chia thành các nhóm. Ví dụ về biến phân loại bao gồm: chủng tộc, giới tính, nhóm tuổi và trình độ học vấn. Mặc dù hai biến cuối có thể là biến liên tục, nhưng trong thực tế chúng thường được phân loại.
Các biến phân loại gây khó khăn khi xây dựng các mô hình học máy vì các mô hình này về bản chất là các mô hình toán học. Do đó, chúng yêu cầu đầu vào là số. Điều này đòi hỏi phải chuyển đổi các biến phân loại thành dạng số phù hợp - quá trình này được gọi là mã hóa biến phân loại (categorical encoding).
Tuy nhiên, không phải phương pháp mã hóa nào cũng phù hợp với mọi bài toán. Việc lựa chọn kỹ thuật mã hóa thường phụ thuộc vào đặc điểm dữ liệu và loại mô hình được sử dụng. Ngoài ra, một số kỹ thuật mã hóa có thể làm tăng đáng kể số chiều của dữ liệu, dẫn đến thời gian huấn luyện lâu hơn và nguy cơ overfitting cao hơn.
2. Các kỹ thuật mã hóa biến phân loại
Có nhiều phương pháp để mã hóa biến phân loại, mỗi phương pháp đều có ưu nhược điểm riêng. Ở đây, chúng ta sẽ tìm hiểu hai kỹ thuật phổ biến: one-hot encoding và label encoding.
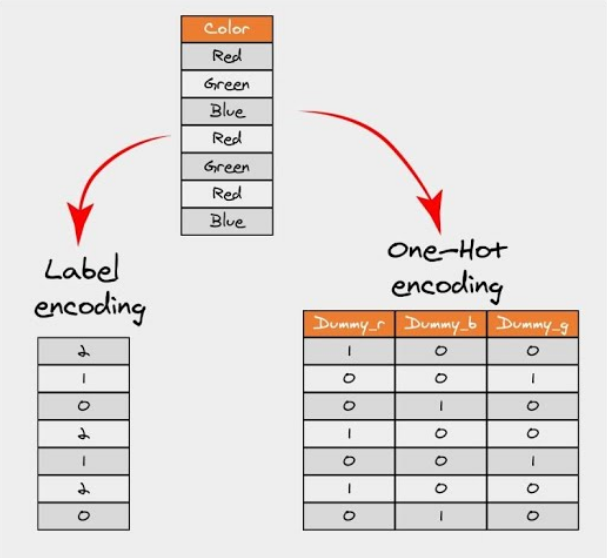
Hình 13. Ví dụ về mã hóa dữ liệu phân loại
- One-hot encoding: One-hot encoding là quá trình chuyển đổi các biến phân loại thành dạng mà các thuật toán học máy có thể sử dụng để cải thiện dự đoán. Với phương pháp này, mỗi giá trị phân loại sẽ được chuyển thành một cột mới và được gán giá trị nhị phân 1 hoặc 0. Mỗi giá trị được biểu diễn dưới dạng một vector nhị phân.
import pandas as pd
data = {
'name': ['John', 'Lisa', 'Peter', 'Carla', 'Eva', 'John'],
'sex': ['male', 'female', 'male', 'female', 'female', 'male'],
'city': ['London', 'London', 'Paris', 'Berlin', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
df_one_hot = pd.get_dummies(df, columns=['sex'], prefix='sex')
print("Original DataFrame:")
print(df)
print("\nDataFrame after one-hot encoding 'sex' and label encoding 'city':")
print(df_one_hot)

- Label encoding: Label Encoding là một kỹ thuật mã hóa phổ biến để xử lý các biến phân loại. Trong phương pháp này, mỗi nhãn (label) được gán một số nguyên duy nhất dựa trên thứ tự bảng chữ cái.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
data = {
'name': ['John', 'Lisa', 'Peter', 'Carla', 'Eva', 'John'],
'sex': ['male', 'female', 'male', 'female', 'female', 'male'],
'city': ['London', 'London', 'Paris', 'Berlin', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
le = LabelEncoder()
df['city_encoded'] = le.fit_transform(df['city'])
print(df)

3. Xử lý biến có nhiều giá trị (High Cardinality) và danh mục hiếm (Rare Categories)
High cardinality nghĩa là một đặc trưng phân loại có rất nhiều giá trị khác nhau, điều này có thể gây khó khăn cho một số phương pháp mã hóa cụ thể. Ví dụ, nếu áp dụng one-hot encoding cho một đặc trưng có nhiều giá trị, số lượng cột trong dữ liệu sẽ tăng mạnh, làm tăng đáng kể bộ nhớ sử dụng.
Một cách để xử lý high cardinality là nhóm các giá trị ít xuất hiện vào một nhóm chung gọi là "Other". Cách này cũng giúp giải quyết vấn đề các danh mục hiếm, tức là những giá trị xuất hiện trong dữ liệu huấn luyện nhưng khó có khả năng xuất hiện trong dữ liệu thực tế sau này.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
data = {
'name': ['John', 'Lisa', 'Peter', 'Carla', 'Eva', 'John'],
'sex': ['male', 'female', 'male', 'female', 'female', 'male'],
'city': ['London', 'London', 'Paris', 'Berlin', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
# Xử lý các giá trị có số lượng lớn (high cardinality) và các giá trị hiếm trong cột 'name'
counts = df['name'].value_counts()
other = counts[counts < 2].index # ở đây, các tên xuất hiện ít hơn 2 lần được xem là "hiếm"
df['name'] = df['name'].replace(other, 'Other')
print("\nDataFrame sau khi xử lý các giá trị hiếm và high cardinality trong cột 'name':")
print(df)

Ví dụ mã Python cho mã hóa biến phân loại
Dưới đây là một ví dụ hoàn chỉnh về cách mã hóa một đặc trưng phân loại trong một tập dữ liệu:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Tạo một DataFrame đơn giản
data = {
'name': ['John', 'Lisa', 'Peter', 'Carla', 'Eva', 'John'],
'sex': ['male', 'female', 'male', 'female', 'female', 'male'],
'city': ['London', 'London', 'Paris', 'Berlin', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
# Áp dụng one-hot encoding cho cột 'sex'
df_one_hot = pd.get_dummies(df, columns=['sex'], prefix='sex')
# Áp dụng label encoding cho cột 'city'
le = LabelEncoder()
df['city_encoded'] = le.fit_transform(df['city'])
# Hiển thị DataFrame ban đầu và DataFrame sau khi xử lý
print("Original DataFrame:")
print(df)
print("\nDataFrame after one-hot encoding 'sex' and label encoding 'city':")
print(df_one_hot)
# Xử lý các giá trị có số lượng lớn (high cardinality) và các giá trị hiếm trong cột 'name'
counts = df['name'].value_counts()
other = counts[counts < 2].index # ở đây, các tên xuất hiện ít hơn 2 lần được xem là "hiếm"
df['name'] = df['name'].replace(other, 'Other')
print("\nDataFrame after handling high cardinality and rare categories in 'name' column:")
print(df)
Trong đoạn code này, chúng ta bắt đầu với một DataFrame đơn giản gồm các cột: name, sex, và city. Sau đó ta thực hiện one-hot encoding cho cột sex bằng hàm get_dummies của pandas, và label encoding cho cột city bằng LabelEncoder từ thư viện scikit-learn. Kết quả là một DataFrame trong đó các cột sex và city đã được chuyển thành dạng số, phù hợp để sử dụng trong mô hình học máy.
Tiếp theo, chúng ta xử lý vấn đề high cardinality và rare categories trong cột name. Ta đếm số lần xuất hiện của mỗi tên sử dụng hàm value_counts, và xác định các tên xuất hiện ít hơn 2 lần là “hiếm”. Sau đó, ta thay thế các tên hiếm này với nhãn “Other”.
Kết quả khi chạy đoạn code trên:
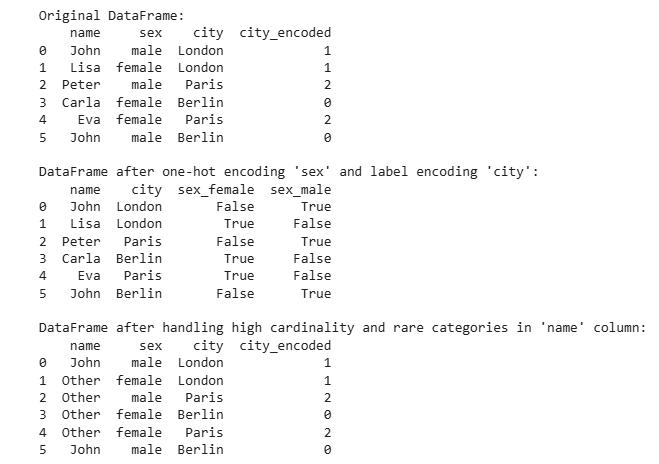
Mã hóa biến phân loại là một bước cực kỳ quan trọng trong quá trình tiền xử lý dữ liệu. Việc lựa chọn đúng phương pháp mã hóa phù hợp với dữ liệu và mô hình có thể ảnh hưởng đáng kể đến hiệu suất của mô hình.
VIII. Xử lý dữ liệu mất cân bằng
Dữ liệu mất cân bằng là một vấn đề phổ biến trong học máy, khi số lượng quan sát của một lớp thấp hơn đáng kể so với các lớp khác. Trong mục này, chúng ta sẽ tìm hiểu dữ liệu mất cân bằng là gì, ảnh hưởng của nó đến mô hình học máy, và các kỹ thuật khác nhau để xử lý.
1. Hiểu về dữ liệu mất cân bằng và ảnh hưởng của nó lên học máy
Dữ liệu mất cân bằng, đúng như tên gọi, là tình huống trong các bài toán phân loại mà các lớp không được phân bố đồng đều. Ví dụ, trong bài toán phân loại nhị phân, ta có 100 mẫu, trong đó 90 mẫu thuộc về lớp ‘A’ (lớp chiếm đa số) và chỉ có 10 mẫu thuộc về lớp ‘B’ (lớp chiếm thiểu số). Đây là một ví dụ điển hình của dữ liệu mất cân bằng.
Vấn đề chính của dữ liệu mất cân bằng là hầu hết các thuật toán học máy hoạt động tốt nhất khi số lượng mẫu giữa các lớp gần bằng nhau. Điều này là do các thuật toán thường được thiết kế để tối đa hóa độ chính xác và giảm lỗi. Vì vậy, chúng có xu hướng tập trung vào lớp đa số và bỏ qua lớp thiểu số. Kết quả là mô hình có thể chỉ dự đoán lớp đa số và vẫn đạt độ chính xác cao, nhưng điều này không hữu ích vì lớp thiểu số - thường là đối tượng quan tâm - bị bỏ qua hoàn toàn.
2. Các kỹ thuật xử lý dữ liệu mất cân bằng
Có nhiều chiến lược để xử lý dữ liệu mất cân bằng, có thể chia thành 3 nhóm chính: các kỹ thuật lấy mẫu lại, học có trọng số chi phí và các phương pháp tổ hợp.
- Các kỹ thuật lấy mẫu lại (Resampling Techniques): Resampling là cách đơn giản nhất để xử lý dữ liệu mất cân bằng, bao gồm việc loại bỏ các mẫu khỏi lớp đa số (undersampling) và/hoặc tăng các mẫu lớp thiểu số (oversampling).
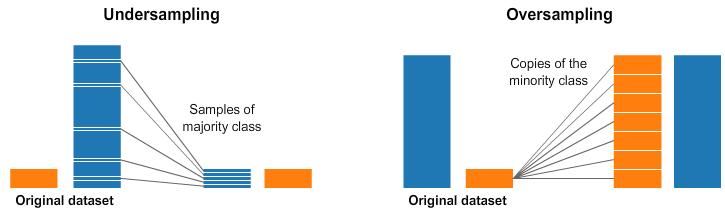
Hình 14. Ví dụ về các kỹ thuật lấy mẫu lại (Resampling)
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
# Giả sử 'X' là tập đặc trưng và 'y' là biến mục tiêu
ros = RandomOverSampler()
X_resampled, y_resampled = ros.fit_resample(X, y)
rus = RandomUnderSampler()
X_resampled, y_resampled = rus.fit_resample(X, y)
- Học có trọng số chi phí (Cost-Sensitive Learning): Đây là phương pháp tích hợp chi phí phân loại sai (false positive và false negative) vào thuật toán học. Nói cách khác, phương pháp này gán chi phí cao hơn cho việc phân loại sai lớp thiểu số, giúp mô hình chú ý nhiều hơn đến lớp này.
from sklearn.svm import SVC
# Tạo mô hình SVC với trọng số lớp được cân bằng ('balanced')
clf = SVC(class_weight='balanced')
clf.fit(X, y)
- Các phương pháp tổ hợp (Ensemble methods): Các phương pháp tổ hợp, ví dụ như là Random Forest hoặc các thuật toán Boosting, cũng có thể được sử dụng để xử lý dữ liệu mất cân bằng. Những phương pháp này hoạt động bằng cách xây dựng nhiều mô hình và kết hợp chúng để đưa ra dự đoán cuối cùng.
from sklearn.ensemble import RandomForestClassifier
# Tạo mô hình phân loại Random Forest
clf = RandomForestClassifier()
clf.fit(X, y)
Ví dụ code Python cho việc xử lý dữ liệu mất cân bằng
Chúng ta có thể sử dụng Python và các thư viện để xử lý dữ liệu mất cân bằng.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from imblearn.over_sampling import SMOTE
data = pd.read_csv("train.csv")
X = data.drop("Churn", axis=1)
y = data["Churn"]
# Áp dụng one-hot encoding cho các cột dạng phân loại
X = pd.get_dummies(X, drop_first=True)
x_train, x_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print("Before SMOTE:")
print(y_train.value_counts())
sm = SMOTE(random_state=42)
X_train_res, y_train_res = sm.fit_resample(x_train, y_train)
print("\nAfter SMOTE:")
print(y_train_res.value_counts())
clf = RandomForestClassifier(random_state=42, n_estimators=200)
clf.fit(X_train_res, y_train_res)
y_pred = clf.predict(x_test)
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
Trong ví dụ này, ta sử dụng kỹ thuật oversampling phổ biến là SMOTE (Synthetic Minority Over-sampling Technique). SMOTE hoạt động bằng cách lựa chọn các mẫu gần nhau trong không gian đặc trưng, vẽ một đường giữa các mẫu trong không gian đặc trưng, và vẽ 1 mẫu mới tại điểm dọc theo đường đó.
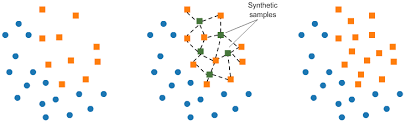
Hình 15. Phương pháp SMOTE
Cụ thể, đầu tiên chọn một mẫu ngẫu nhiên từ lớp thiểu số. Sau đó, k láng giềng gần nhất với mẫu này được chọn (thông thường k = 5). Chọn ngẫu nhiên một láng giềng, tạo một mẫu mới tại vị trí ngẫu nhiên trên đoạn thẳng nối giữa hai điểm trong không gian đặc trưng.
Phương pháp này hiệu quả vì các mẫu mới từ lớp thiểu số được tạo ra là hợp lý, nghĩa là, nằm gần các mẫu đã có của lớp thiểu số trong không gian đặc trưng.
Trong phần cuối của đoạn code, chúng ta tạo một bộ phân loại Random Forest, huấn luyện nó trên dữ liệu đã được lấy mẫu lại, thực hiện dự đoán trên tập kiểm tra, và in ra báo cáo phân loại để quan sát kết quả.
Mục này cung cấp cái nhìn tổng quan về các thách thức và chiến lược liên quan đến việc xử lý dữ liệu mất cân bằng. Mặc dù phần này đề cập đến các phương pháp được sử dụng phổ biến nhất, cần lưu ý rằng kỹ thuật tối ưu sẽ phụ thuộc vào đặc điểm cụ thể của tập dữ liệu và bài toán. Do đó, việc hiểu rõ các phương pháp này là rất quan trọng để xử lý hiệu quả các tập dữ liệu mất cân bằng và xây dựng các mô hình học máy mạnh mẽ và đáng tin cậy.
IX. Các kỹ thuật tích hợp và biến đổi dữ liệu
Thông thường, dữ liệu nằm rải rác ở nhiều nguồn khác nhau, mỗi nguồn có cấu trúc và định dạng riêng. Ngay cả khi dữ liệu được tập trung ở một nơi, nó có thể không ở định dạng tối ưu cho việc phân tích hoặc mô hình mà ta dự định thực hiện. Mục này thảo luận về các kỹ thuật tích hợp và biến đổi dữ liệu giúp dữ liệu trở nên phù hợp hơn cho việc phân tích.
1. Các phương pháp tích hợp dữ liệu
Tích hợp dữ liệu là quá trình kết hợp dữ liệu từ nhiều nguồn khác nhau và cung cấp cho người dùng một cái nhìn thống nhất về các dữ liệu đó. Quá trình này trở nên quan trọng trong nhiều tình huống khác nhau, bao gồm cả trong lĩnh vực thương mại (khi hai công ty tương tự cần hợp nhất cơ sở dữ liệu của họ) và khoa học (ví dụ, kết hợp các kết quả nghiên cứu từ các kho dữ liệu sinh học khác nhau).
- Merging: Merging là quá trình kết hợp hai hoặc nhiều tập dữ liệu dựa trên các cột chung giữa chúng.
# Giả sử 'df1' và 'df2' là các DataFrame của bạn
merged_df = pd.merge(df1, df2, on='common_column')
- Joining: Joining là một phương pháp thuận tiện để kết hợp các cột của hai DataFrame có thể có chỉ mục khác nhau thành một DataFrame kết quả duy nhất. Trong Pandas, chúng ta có thể join các DataFrame bằng cách sử dụng hàm join.
# Giả sử 'df1' và 'df2' là các DataFrame của bạn
joined_df = df1.join(df2, lsuffix='_df1', rsuffix='_df2')
- Concatenating: Concatenation là quá trình nối các tập dữ liệu, tức là thêm các DataFrame theo một trục cụ thể, có thể theo hàng hoặc theo cột.
# Giả sử 'df1' và 'df2' là các DataFrame của bạn
concat_df = pd.concat([df1, df2])
2. Các kỹ thuật biến đổi dữ liệu
Biến đổi dữ liệu là quá trình chuyển đổi dữ liệu từ một định dạng hoặc cấu trúc này sang một định dạng hoặc cấu trúc khác.
- Binning: Binning là một kỹ thuật biến đổi dữ liệu được sử dụng để nhóm một tập các giá trị liên tục thành các khoảng (bins) hoặc nhóm (buckets). Điều này đặc biệt hữu ích trong việc xử lý nhiễu hoặc các giá trị ngoại lai.
# Giả sử 'df' là DataFrame của bạn và 'age' là cột cần chia thành các khoảng (bin)
bins = [0, 18, 35, 60, np.inf]
names = ['<18', '18-35', '35-60', '60+']
df['age_range'] = pd.cut(df['age'], bins, labels=names)
- Log Transformation: Biến đổi log là một phương pháp biến đổi dữ liệu trong đó mỗi biến x được thay bằng log(x). Việc lựa chọn cơ số của log thường do người phân tích quyết định và phụ thuộc vào mục đích của mô hình thống kê.
# Giả sử 'df' là DataFrame của bạn và 'price' là cột cần biến đổi
df['log_price'] = np.log(df['price'])
- Power Transformation: Biến đổi lũy thừa là một kỹ thuật thống kê nhằm làm cho dữ liệu gần với phân phối chuẩn hơn.
from sklearn.preprocessing import PowerTransformer
# Giả sử 'X' là tập đặc trưng của bạn
pt = PowerTransformer()
X_transformed = pt.fit_transform(X)
3. Xử lý phân phối lệch và mối quan hệ phi tuyến
Trong thống kê, độ lệch (skewness) là thước đo mức độ bất đối xứng của phân phối xác suất của một biến ngẫu nhiên thực so với giá trị trung bình của nó. Nói cách khác, skewness cho biết mức độ và hướng lệch (sự lệch khỏi tính đối xứng). Giá trị skewness có thể dương, âm hoặc không xác định.
Để xử lý dữ liệu bị lệch, chúng ta thường sử dụng các phép biến đổi như logarit, căn bậc hai hoặc căn bậc ba để chuẩn hóa dữ liệu.
# Biến đổi log để xử lý phân phối lệch phải (right skewness)
# Giả sử 'df' là DataFrame của bạn và 'income' là đặc trưng bị lệch
df['log_income'] = np.log(df['income'] + 1) # Cộng thêm 1 để xử lý các giá trị bằng 0
# Kiểm tra sự thay đổi của độ lệch (skewness)
print("Old skewness:", df['income'].skew())
print("New skewness:", df['log_income'].skew())
Mối quan hệ phi tuyến giữa các biến có thể được xử lý theo nhiều cách. Một trong những cách phổ biến nhất là sử dụng các đặc trưng đa thức (polynomial features), trong đó các đặc trưng được nâng lên lũy thừa để nắm bắt các mối quan hệ phức tạp hơn.
from sklearn.preprocessing import PolynomialFeatures
# Giả sử 'X' là tập đặc trưng của bạn
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
Mục này đã cung cấp một cái nhìn tổng quan về các kỹ thuật tích hợp và biến đổi dữ liệu, những yếu tố thiết yếu trong quá trình tiền xử lý dữ liệu. Việc hiểu rõ các kỹ thuật này là rất quan trọng, vì dữ liệu thực tế thường yêu cầu nhiều bước làm sạch, tiền xử lý và biến đổi để khám phá các mẫu và thông tin tiềm ẩn.
Kết luận
Toàn bộ nội dung đã trình bày một cách hệ thống các bước quan trọng trong quy trình làm sạch và tiền xử lý dữ liệu, đây là một giai đoạn mang tính nền tảng nhưng lại thường bị đánh giá thấp trong khoa học dữ liệu. Từ việc nhận diện các vấn đề chất lượng dữ liệu như giá trị khuyết, dữ liệu trùng lặp, ngoại lệ, cho đến các kỹ thuật nâng cao như chuẩn hóa, mã hóa biến phân loại, giảm chiều dữ liệu và xử lý mất cân bằng, tất cả đều đóng vai trò quyết định đến hiệu suất cuối cùng của mô hình.
Một điểm quan trọng cần nhấn mạnh là không tồn tại một “công thức chung” cho mọi bài toán. Việc lựa chọn kỹ thuật xử lý phù hợp phụ thuộc rất lớn vào bản chất dữ liệu, mục tiêu phân tích và loại mô hình được sử dụng. Ví dụ, việc xử lý missing data cần cân nhắc giữa độ chính xác và độ phức tạp; xử lý outliers cần phân biệt giữa nhiễu và thông tin giá trị; hay việc chọn phương pháp encoding có thể ảnh hưởng trực tiếp đến dimensionality và nguy cơ overfitting.
Bên cạnh đó, các kỹ thuật như feature selection, feature extraction hay scaling không chỉ giúp cải thiện hiệu suất mô hình mà còn góp phần giảm chi phí tính toán và tăng khả năng giải thích. Trong thực tế, quy trình tiền xử lý dữ liệu thường mang tính lặp lại, bạn có thể phải quay lại điều chỉnh nhiều lần trước khi đạt được kết quả tối ưu.
Cuối cùng, có thể khẳng định rằng: chất lượng dữ liệu đầu vào quyết định trực tiếp đến chất lượng của mô hình đầu ra. Một pipeline tiền xử lý tốt không chỉ giúp mô hình hoạt động hiệu quả hơn mà còn giúp bạn hiểu sâu hơn về dữ liệu, yếu tố cốt lõi trong mọi bài toán data science.
TÀI LIỆU THAM KHẢO
Géron, A. (2019). Hands-on machine learning with scikit-learn, keras, and tensorflow (2nd ed.). O'Reilly Media. https://www.oreilly.com/library/view/hands-on-machine-learning/9781492032632/
McKinney, W. (2022). Python for data analysis (3rd ed.). O'Reilly Media. https://wesmckinney.com/book/
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., ... Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830. https://jmlr.org/papers/v12/pedregosa11a.html
The pandas development team. (2023). Pandas: powerful Python data analysis toolkit. Pandas documentation. https://pandas.pydata.org/docs/
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321–357. https://doi.org/10.1613/jair.953
AI ML Analytics. (2024). Feature scaling [Image]. AI ML Analytics. https://ai-ml-analytics.com/feature-scaling
Babbar, T. (2023). Beyond the norm: How outlier detection transforms data analysis [Image]. AlliedOffsets. https://blog.alliedoffsets.com/beyond-the-norm-how-outlier-detection-transforms-data-analysis
Boutnaru, S. (2024). The artificial intelligence journey: PCA (principal component analysis) [Image]. Medium. https://medium.com/@boutnaru/the-artificial-intelligence-journey-pca-principal-component-analysis-80b4d12b2cd2
Mazur, I., & Moshenko, K. (2021). Business/technical mathematics illustration [Image]. BCcampus. https://pressbooks.bccampus.ca/businessmathematics/
Roy, B. (2020). All about feature scaling [Image]. Towards Data Science. https://towardsdatascience.com/all-about-feature-scaling-bcc0ad75cb35
Sampaio, F. (2023). Oversampling and undersampling techniques in fraud prevention [Image]. Medium. https://medium.com/@fernandasampaio_74014/oversampling-and-undersampling-techniques-in-fraud-prevention-53129148281a
Sharma, S. (2026). One hot encoding vs label encoding [Image]. GeeksforGeeks. https://www.geeksforgeeks.org/machine-learning/one-hot-encoding-vs-label-encoding/
Single-cell best practices developers. (2023). Dimensionality reduction [Image]. Single-cell best practices. https://www.sc-best-practices.org/preprocessing_visualization/dimensionality_reduction.html
Zhang, D. (2020). Dimensionality reduction using t-distributed stochastic neighbor embedding (t-SNE) on the MNIST dataset [Image]. Medium. https://medium.com/data-science/dimensionality-reduction-using-t-distributed-stochastic-neighbor-embedding-t-sne-on-the-mnist-9d36a3dd4521
Edure. (2024). Data cleaning illustration [Image]. Edure. https://edure.in/data-cleaning-in-data-science/
Chưa có bình luận nào. Hãy là người đầu tiên!