Khi học về data cleaning, mọi thứ có vẻ rất đơn giản. Thiếu dữ liệu? Điền vào hoặc xoá đi. Bị trùng? Xoá. Sai chính tả? Chuẩn hoá.
Tất cả đều nghe rất hợp lý. Nhưng khi bạn bắt đầu làm việc với dữ liệu thực tế - đặc biệt là trong những lĩnh vực như Human Resources (HR), bạn sẽ nhận ra một điều quan trọng:
Dữ liệu không phải lúc nào cũng “bẩn”. Đôi khi, nó chỉ là chưa được hiểu đúng.
Và đó là lúc data cleaning trở nên nguy hiểm.

1. Data cleaning cơ bản
Hãy bắt đầu với một dataset cơ bản trên Kaggle: Cafe Sales Dataset.
Link Google Colab: Data cleaning demo
Ta sẽ làm theo 6 bước để clean data.
1.1. Bước 1: Khám phá dữ liệu
Mục tiêu của bước này là hiểu cấu trúc dữ liệu.
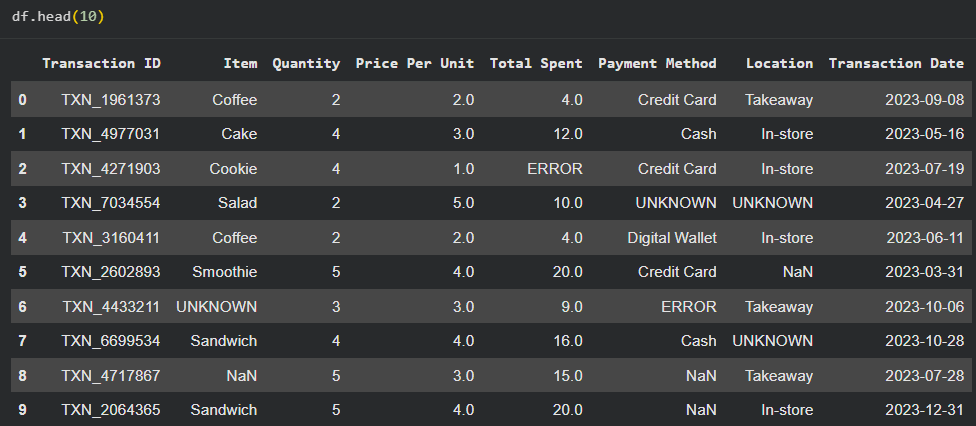
Ảnh: 10 hàng đầu tiên trong tệp dữ liệu.
Ta cần kiểm tra:
- Shape
- Data types
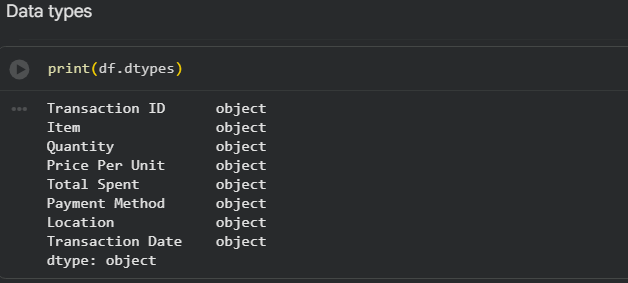
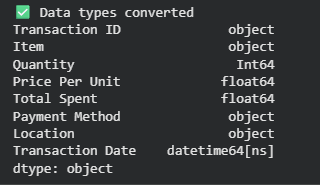
Hiện tại tất cả các cột đều mang data type object vì có lẫn các giá trị string trong đó.
- Null percentage
- Unique values counts
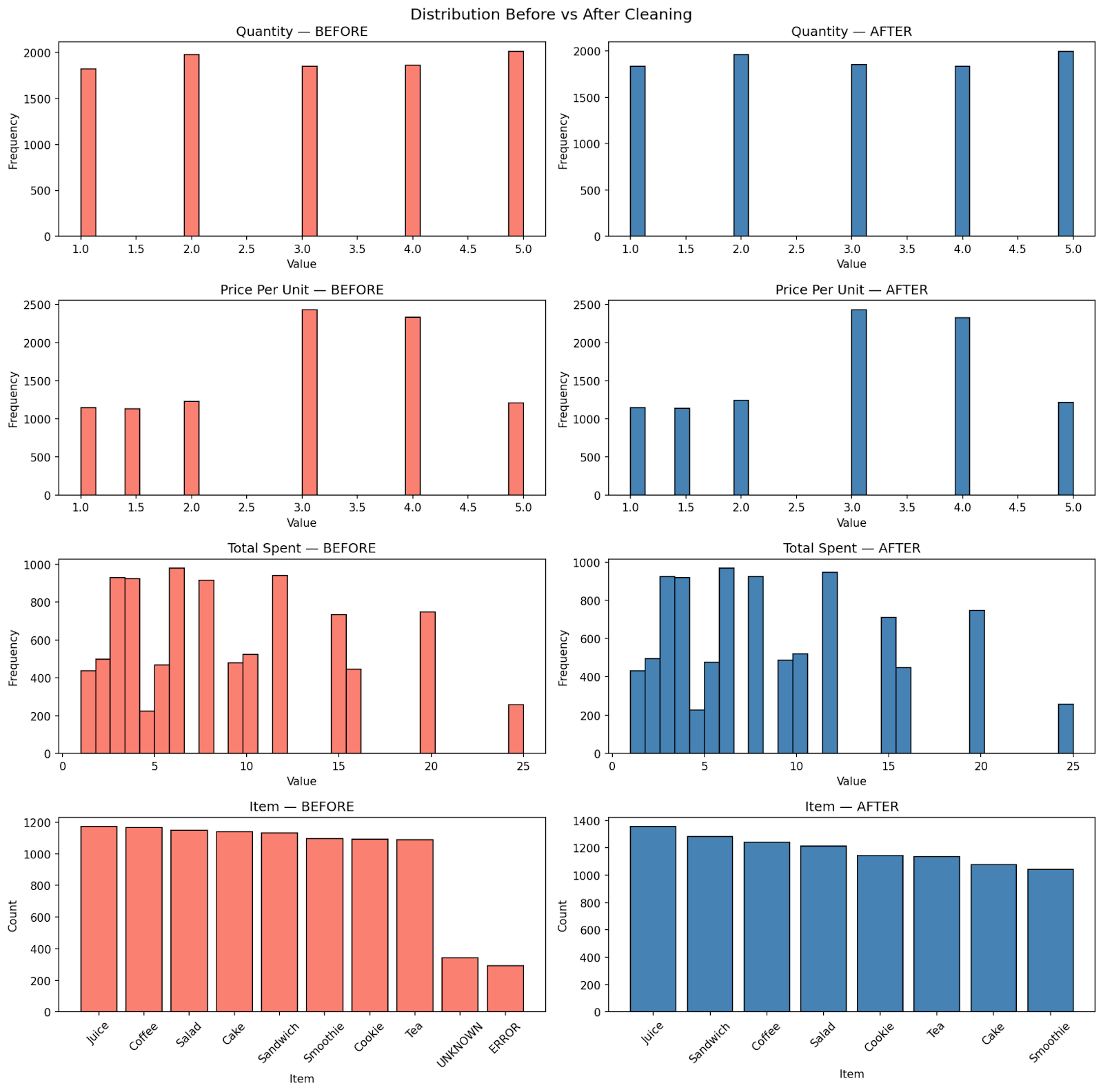
- Basic statistics and distributions: Tính các giá trị statistics cơ bản của dataset, sau khi clean chúng ta sẽ so sánh với những giá trị đó để kiểm tra xem quá trình clean có làm mất đi tính chất của dataset.
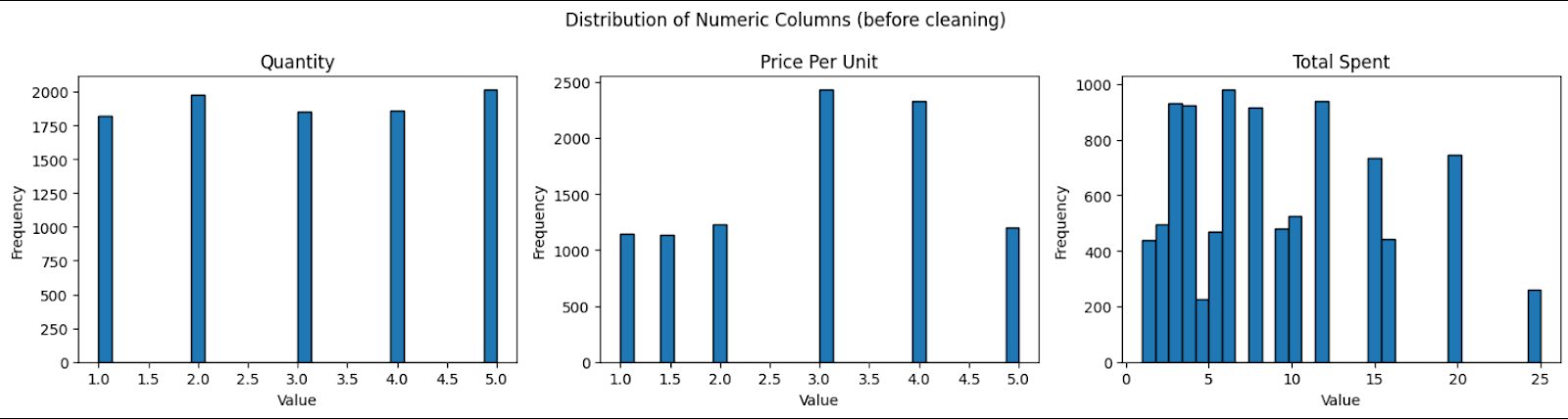
Ảnh: Dataset distribution trước khi clean
- Transaction Date: trải dài từ 2023-01-01 tới 2023-12-31
- Item: Juice, Coffee, Salad, Cake, Sandwich, Smoothie, Cookie, Tea và các giá trị rác
- Payment Method: Digital Wallet, Credit Card, Cash và các giá trị rác
- Location: Takeaway, In-store và các giá trị rác
1.2. Bước 2: Xác định các giá trị cần tập trung
- Giả sử bài toán là Theo dõi doanh thu theo thời gian, vì vậy ta sẽ tập trung vào những giá trị số trong bộ dataset này, kèm theo đó là việc 2 cột Payment Method và Location bị thiếu quá nhiều dữ liệu (>30%), vì vậy có thể chấp nhận những giá trị rác được điền là Unknown
- Transaction ID không bị thiếu dữ liệu
- Chúng ta sẽ tập trung vào clean các cột Item, Quantity, Price Per Unit và Total Spent, đồng thời chuyển chúng về kiểu dữ liệu đúng sau khi clean.
- Transaction Date: sử dụng forward fill / backward fill để điền vào những dòng bị thiếu nếu có thể
1.3. Bước 3: Xử lý giá trị bị thiếu
Đầu tiên chúng ta sẽ chuyển hết các giá trị UNKNOWN, ERROR ở tất cả các cột thành NaN, đồng thời copy dataset gốc sang 1 biến khác để có thể so sánh sau khi clean:
df_clean = df.copy()
df_clean.replace(['UNKNOWN', 'ERROR'], np.nan, inplace=True)
Sau đó chúng ta có thể sử dụng thư viện missingno để visualize missing pattern của các cột, sau đó chúng ta có thể sử dụng thư viện pyampute hoặc tự viết 1 hàm để kiểm tra xem missing pattern thuộc loại nào. Trong dataset này, missing pattern là MCAR, vì vậy nếu gặp các dòng bị thiếu dữ liệu ở cột Item, Quantity, Price Per Unit hoặc Total Spent ta hoàn toàn có thể xóa các dòng này. Tuy nhiên đây là cách làm chưa tối ưu, gây ra mất mát tới 14% dữ liệu sau khi clean.

Ảnh: Kết quả khi sử dụng pyampute
Có thể thấy mối quan hệ: Total Spent = Price Per Unit * Quantity. Vì vậy nếu 2 trong 3 cột dữ liệu có tồn tại thì ta hoàn toàn có thể tính toán cột còn lại đang bị thiếu.
mask_price = (df_clean['Price Per Unit'].isnull() &
df_clean['Total Spent'].notna() &
df_clean['Quantity'].notna())
df_clean.loc[mask_price, 'Price Per Unit'] = (
df_clean['Total Spent'] / df_clean['Quantity']
).round(2)
print(f"Price Per Unit calculated for : {mask_price.sum()} rows")
Nếu thiếu 2 cột trở lên bị thiếu thì chúng ta sẽ bỏ dòng đó:
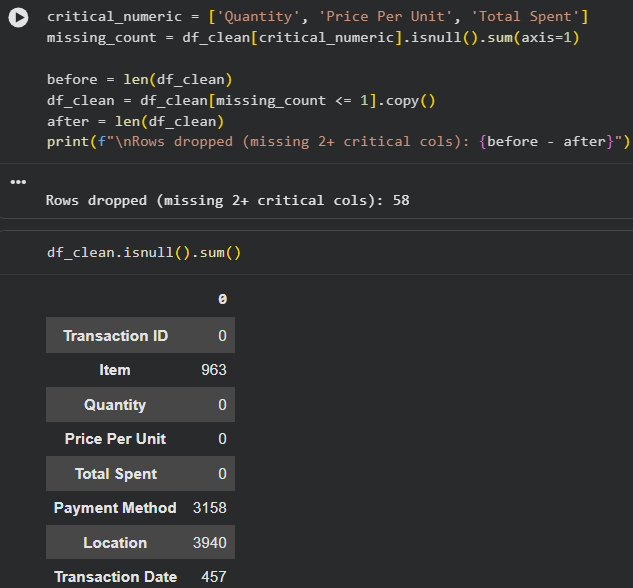
Có thể thấy chúng ta chỉ cần drop 58 dòng và vẫn clean được toàn bộ các giá trị số.
Tiếp theo cần clean cột Item. Ý tưởng ở đây là dựa vào cột Price Per Unit đã clean, chúng ta tính được giá trị trung bình cho từng loại Item. Sau đó ta sẽ tới từng dòng bị thiếu Item, kiểm tra Price Per Unit của dòng đó và gán Item cho giá trị mà Price Per Unit của dòng đó gần với giá trị trung bình nhất.
Nếu 2 hoặc nhiều Item mang cùng giá trị trung bình, ta sẽ lấy Item xuất hiện nhiều hơn (frequency):
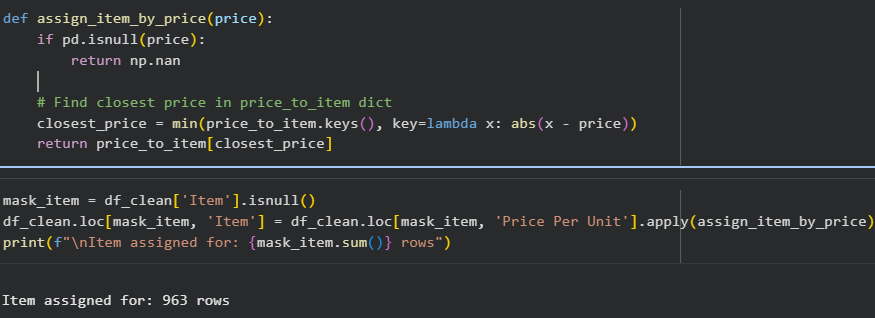
Ảnh: Toàn bộ 964 hàng Item bị thiếu đã được điền lại
Với 2 cột Location and Payment Method, ta thay các dòng chứa giá trị rác bằng string ‘Unknown’
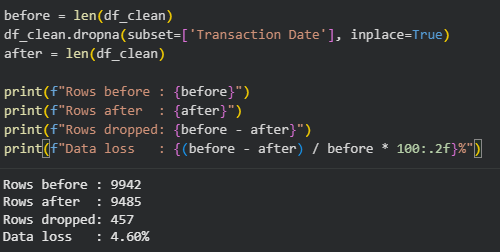
Với cột Transaction date, do dataset không được sắp xếp theo ngày tháng tăng dần, ta có 2 lựa chọn:
- Drop các dòng bị thiếu, 457 dòng tương đương với 4.5 % là 1 con số tốt
- Giữ lại các dòng bị thiếu, đẩy tất cả về cuối bằng hàm sort và sử dụng forward fill để điền tất cả các ngày bị thiếu thành 2023-12-31. Điều này có thể gây ra sai sót trong bài toán Time Series (những ngày cuối năm doanh thu đột ngột tăng).
Ta chọn lựa chọn 1.
Sau bước này toàn bộ dataset đã được clean hoàn chỉnh, kiểm tra statistic của dataset sau khi clean:
1.4. Bước 4: Chuẩn hoá dữ liệu
- Chuẩn hoá Text:
text_cols = ['Item', 'Payment Method', 'Location']
for col in text_cols:
df_clean[col] = df_clean[col].str.strip().str.title()
- Chuẩn hoá dữ liệu dạng số:
1.5. Bước 5: Xoá dòng trùng nhau
Dataset không có duplicate rows
1.6. Bước 6: Kiểm tra lại
Sau khi clean chúng ta mất 5.15% dataset và các tính chất thống kê vẫn được giữ nguyên. Bằng việc hiểu tính chất của các cột, chúng ta có thể không cần drop các dòng bị thiếu 1 cách máy móc mà vẫn có thể clean 1 cách hiệu quả.
Trong môi trường này, data cleaning chủ yếu là áp dụng các quy tắc, data cũng tuân theo một pattern nhất định. Tuy nhiên, trong thực tế, không phải lúc nào data cũng dễ xử lý như vậy. Vì vậy, data cleaning trong thực tế cũng khác rất nhiều.
2. Data cleaning trong thực tế - HR dataset
Giờ ta hãy nghiên cứu dataset về HR trong thực tế.
2.1. 3 đặc điểm của HR dataset
- Nguồn dữ liệu phân mảnh: Dữ liệu hiếm khi nằm ở một nơi duy nhất. Nó luân chuyển từ các khảo sát lương bên ngoài (được thực hiện bởi các đơn vị như Mercer, Willis Towers Watson hoặc Radford) và các hệ thống nội bộ của công ty. Chúng ta phải đối chiếu giữa dữ liệu "Nội bộ" (hồ sơ nhân viên) với dữ liệu "Bên ngoài" (điểm chuẩn thị trường), vốn hiếm khi sử dụng cùng một định dạng.
- Bẫy diễn giải: Không giống như việc phân loại "chó và mèo", dữ liệu nhân sự mang tính chủ quan. Ví dụ: một chuyên viên tuyển dụng có thể gắn nhãn một ứng viên là "Kỹ sư AI", với kỳ vọng họ có thể xử lý mọi thứ từ Web-dev, API đến hệ thống Cloud và backend. Một chức danh công việc đơn giản có thể có hàng tá cách hiểu khác nhau tùy thuộc vào người đang xem xét nó. Đó là một sự hỗn loạn đầy thú vị!
- Ranh giới quyền riêng tư: Các tệp hồ sơ nhân sự chứa thông tin nhạy cảm nhất của bạn—tên, địa chỉ nhà, lương và phúc lợi. Việc chuyển các dữ liệu này đi một cách tự do không chỉ là "thiếu chuyên nghiệp" mà thường là bất hợp pháp. Bảo vệ thông tin nhận dạng cá nhân (PII) là bước đầu tiên và quan trọng nhất trong bất kỳ quy trình làm việc với dữ liệu nhân sự nào.
Chính vì những đặc điểm này, các công ty phải phát triển các quy trình làm sạch chuyên biệt để đảm bảo tuân thủ pháp luật mà không biến việc phân tích trở thành một cơn ác mộng. Đây không chỉ là câu chuyện về sự gọn gàng; đó là câu chuyện về sự sống còn.
2.2. Xây dựng lá chắn kỹ thuật số
Trong ngành Nhân sự (HR), làm sạch dữ liệu bắt đầu bằng việc tập trung tối đa vào bảo mật và tuân thủ. Trong khi nhiều người nghĩ "làm sạch" chỉ đơn giản là sửa lỗi đánh máy hoặc xóa các bản ghi trùng lặp, thì trong lĩnh vực của chúng ta, nó hầu như luôn bắt đầu bằng việc Ẩn danh hóa (Anonymization). Vì hồ sơ nhân sự chứa các chi tiết nhạy cảm như địa chỉ nhà, tài khoản ngân hàng và mức lương, chúng ta phải loại bỏ hoặc che đi các thông tin nhận dạng cá nhân trước khi dữ liệu được đưa vào phân tích.
Quá trình này phần lớn được thúc đẩy bởi các yêu cầu pháp lý nghiêm ngặt. Các quy định như GDPR ở Châu Âu, CCPA ở California và các luật lao động địa phương tại Thành phố Hồ Chí Minh quy định cách chúng ta xử lý thông tin này. Ví dụ, theo GDPR, chúng ta phải tính đến "Quyền được lãng quên". Điều này có nghĩa là quy trình làm sạch dữ liệu của chúng ta phải có khả năng xóa vĩnh viễn các chi tiết cá nhân của một cá nhân nếu họ rời công ty, trong khi vẫn cho phép chúng ta giữ lại các xu hướng lịch sử cấp cao cho doanh nghiệp.
Trong bối cảnh thực tế hàng ngày, việc này thường liên quan đến Mã hóa (Encryption). Hầu hết các công ty sử dụng các tiêu chuẩn như AES-256 để xáo trộn các trường thông tin như tên, email và số định danh chính phủ. Thay vì làm việc với tên thật của một người, chúng ta làm việc với một "mã thông báo" (token) đã được mã hóa hoặc một ID ngẫu nhiên. Đây là một ví dụ thực tế về cách PII vận hành. Tất cả các trường như “EmployeeID”, “HireDate”, “FirstName”, “LastName”, “BirthDate”, “ReportToEmployeeID” và “Email” đều là các trường PII, và chúng được ẩn đi một cách có chủ đích đằng sau các lớp mã hóa này.
Việc thực hiện điều này sớm trong quy trình phục vụ hai mục đích:
- Nó đảm bảo công ty luôn tuân thủ pháp luật trong trường hợp xảy ra vi phạm dữ liệu.
- Nó giúp ngăn ngừa định kiến vô thức. Khi một nhà phân tích xem xét sự công bằng trong chi trả lương hoặc tỷ lệ thăng tiến, chúng ta có thể tập trung hoàn toàn vào các con số và năng lực mà không bị ảnh hưởng bởi việc biết chính xác dữ liệu đó thuộc về đồng nghiệp nào.
2.3. Thấu hiểu bối cảnh: Phát hiện những điểm bất thường
Nhiều nhà phân tích mới vào nghề chỉ học về công cụ, nhưng chúng ta cũng cần phải thấu hiểu ngành công nghiệp mà mình đang làm việc. Trong HR, thời gian không chỉ trôi theo một đường thẳng. Các hồ sơ luôn có Ngày hiệu lực (Effective Date), và việc làm sạch chúng đòi hỏi một quy trình gọi là Đối soát tại một thời điểm (Point-in-Time Reconciliation).
Hãy tưởng tượng kịch bản này: một nhân viên được tăng lương vào ngày 1 tháng 3, nhưng người quản lý không nhập dữ liệu đó vào hệ thống cho đến ngày 10 tháng 3. Nếu bạn xuất một báo cáo "hiện tại" vào ngày 5 tháng 3, mức lương của nhân viên đó là bao nhiêu? Chính là mức lương cũ.
Dữ liệu "bẩn" mà chúng ta phải xử lý được gọi là Hồ sơ trùng lặp (Overlapping Records). Nếu không có logic làm sạch nghiêm ngặt và kiến thức ngành, cùng một nhân viên có thể xuất hiện hai lần trong báo cáo kiểm kê nhân sự: một lần với chức danh cũ (có hiệu lực đến hết ngày 28 tháng 2) và một lần nữa với chức danh mới (có hiệu lực từ ngày 1 tháng 3). Quy trình làm sạch của chúng ta phải đủ tinh vi để xác định và loại bỏ hồ sơ đã lỗi thời dựa trên ngày hiệu lực. Nếu bạn lờ đi Ngày hiệu lực, số lượng nhân sự sẽ bị sai, báo cáo ngân sách sẽ bị đội lên, và bạn sẽ có một mớ hỗn độn mà không công thức nào có thể cứu vãn được.
Ngày hiệu lực (hoặc ngày công bố) cũng thường được sử dụng trong các báo cáo từ các nhà cung cấp lớn để phân loại ngày của dữ liệu. Những dữ liệu này được cập nhật hàng quý và là thông tin quan trọng nhất cần nắm vững trước khi thực hiện bất kỳ tác vụ nào.
Trong ngành Nhân sự, chúng ta phải cực kỳ nhạy bén với môi trường nơi dữ liệu được tạo ra. Chẳng hạn, bạn có thể thấy hai nhân viên có cùng chức danh công việc, nhưng một người lại có mức thu nhập cao hơn hẳn người kia. Trước khi vội kết luận đó là lỗi và tiến hành "làm sạch", chúng ta phải xem xét đến Chi phí lao động (Cost of Labor). Một nhân viên làm việc tại các trung tâm đắt đỏ như Boston hay San Francisco hiển nhiên sẽ có mức lương cao hơn một người ở vùng ngoại ô hoặc các thành phố nhỏ hơn. Nếu không hiểu những sắc thái địa lý này, chúng ta có thể gắn cờ sai cho những chênh lệch lương hoàn toàn hợp lệ và coi chúng là các mục dữ liệu cần "sửa".
Một cái bẫy phổ biến khác là Nhầm lẫn tiền tệ (Currency Confusion). Trong các công ty toàn cầu, việc khách hàng hoặc người quản lý nhập một con số lớn bất thường vào bảng tính là điều rất hay xảy ra. Nếu bạn thấy mức lương 2.000.000.000 được liệt kê dưới đơn vị "USD", trực giác của chúng ta phải được kích hoạt ngay lập tức. Rất có khả năng số tiền đó thực chất được nhập theo đơn vị VND (Việt Nam Đồng) nhưng lại bị phân loại sai mã tiền tệ. Nếu không nhạy cảm với các bối cảnh kinh doanh cụ thể này, chúng ta sẽ có nguy cơ tạo ra những báo cáo sai lệch một cách trầm trọng.
2.4. Chuẩn hóa "Yếu tố con người"
Lời khuyên làm sạch dữ liệu kiểu "chó và mèo" tiêu chuẩn ở trường học luôn hiệu quả vì chó thì luôn là chó, mèo luôn là mèo. Nhưng trong ngành Nhân sự, chúng ta đối mặt với thử thách về Sự chuẩn hóa mang tính chủ quan. Như đã đề cập, cùng một vị trí mà người quản lý này gọi là "Junior Developer", người khác lại gọi là "Associate Programmer". Đây chính là nơi "nghệ thuật" làm sạch dữ liệu xuất hiện. Chúng ta không thể chỉ chạy một đoạn mã để đổi tên mọi trường hợp từ "Wizard" thành "Specialist", bởi vì những từ đó có thể mang ý nghĩa khác nhau ở các phòng ban khác nhau. Đó là lý do tại sao chúng ta phải liên tục trao đổi với các bên liên quan trước khi nhấn nút "xóa" hoặc "thay thế".
Hãy tưởng tượng chúng ta đang làm sạch một danh sách các chức danh công việc để giúp công ty hiểu nhu cầu tuyển dụng của họ. Chúng ta thấy 20 chức danh khác nhau đều trông giống như "Trợ lý hành chính" (Administrative Assistant). Bản năng của chúng ta có thể là gộp tất cả chúng vào một danh mục duy nhất để dữ liệu trông "sạch" hơn. Tuy nhiên, nếu không kiểm tra với trưởng bộ phận trước, chúng ta có thể bỏ lỡ một chi tiết quan trọng: có lẽ 10 người trong số đó là trợ lý cấp cao dành cho ban điều hành (Executive-level) đòi hỏi kiến thức pháp lý chuyên sâu, trong khi 10 người còn lại là hỗ trợ văn phòng nói chung. Nếu chúng ta "làm sạch" bằng cách gộp họ vào cùng một nhóm mà không hỏi trước, chúng ta vừa khiến công ty không thể nhận ra rằng họ thực sự đang trả lương thấp cho các chuyên gia pháp lý của mình.
Một số công ty có thể chia cấp độ nhân viên của họ thành các danh mục khác nhau. Điều này có thể thay đổi từ cấp độ A (Associate - Cộng tác viên), cấp độ P (Professionals - Chuyên viên) đến cấp độ M (Management - Quản lý) hoặc thậm chí cấp độ E (Education - Giáo dục, hãy nghĩ về nó như các giáo sư trường học). Nếu chúng ta không hiểu các quy tắc và cấu trúc này, chúng ta sẽ mắc phải những sai lầm chết người trong quá trình làm sạch dữ liệu và báo cáo của mình.
Quy trình làm sạch trong HR không chỉ đơn thuần là làm cho bảng tính trông gọn gàng; đó là việc đảm bảo các danh mục có ý nghĩa đối với những người sử dụng chúng. Một bộ dữ liệu "sạch" chỉ thực sự hữu ích nếu nó phản ánh chính xác vai trò và trách nhiệm của những con người thực sự đang làm việc tại văn phòng.
2.5. Kiểm chứng thực tế về công cụ
Bạn có thể dành nhiều năm để học SQL, Python hoặc AI tiên tiến ở đại học, nhưng một khi bước chân vào văn phòng HR, bạn sẽ đối mặt với một thực tế phũ phàng:
Excel vẫn là vị vua không thể tranh cãi.
Thực tế là các bộ dữ liệu HR thường có quy mô từ nhỏ đến trung bình. Một tệp lương tiêu chuẩn có thể chỉ có vài nghìn dòng. Chúng ta không luôn cần các công cụ "dữ liệu lớn" (big data) để xử lý các yêu cầu này, mà cần một người có khả năng "kết bạn" với các bảng tính. Mặc dù các công cụ như VBA, Macros hay Power Query có tồn tại và hỗ trợ trong một số quy trình, nhưng chúng thường là ngoại lệ chứ không phải quy tắc chung. Việc học một công cụ ở trường rất khác với việc áp dụng nó trong thế giới thực.
Trong quy trình làm việc hàng ngày, chúng ta dựa dẫm rất nhiều vào các hàm cốt lõi như XLOOKUP, IFS, và các hàm xử lý văn bản như LEFT, RIGHT, and CONCAT. Chúng ta cũng sử dụng các tiện ích bổ sung chuyên dụng như ASAP Utilities để tăng tốc các tác vụ lặp đi lặp lại mà nếu làm thủ công sẽ mất hàng giờ.
Qua kinh nghiệm làm Nhà phân tích dữ liệu nhân sự, mình nhận thấy rằng những bước làm sạch quan trọng nhất không hề cao siêu, chúng là những bước nền tảng:
- Loại bỏ các ký tự ẩn: Chúng ta triệt để loại bỏ các ký tự đặc biệt như tab, xuống dòng (linefeeds) hoặc xuống dòng về đầu dòng (carriage returns). Những ký tự "vô hình" này có thể làm hỏng công thức và khiến một hàm VLOOKUP được viết hoàn hảo vẫn thất bại mà không rõ lý do.
- Quy tắc "General" cho tiền tệ: Chúng ta đảm bảo các loại dữ liệu là chính xác, đặc biệt là tiền bạc. Chúng ta thường để tiền tệ ở định dạng General thay vì định dạng "Currency" vì dấu phẩy đôi khi có thể bị các công cụ báo cáo khác hiểu nhầm là văn bản, dẫn đến những lỗi tính toán khổng lồ.
- Không khoan nhượng với các ô trống: Khi thấy dữ liệu trống, chúng ta không chỉ đơn giản là "điền vào chỗ trống". Trong HR, một ô trống có thể mang ý nghĩa từ lỗi hệ thống đến một tình trạng pháp lý nhạy cảm. Chúng ta hầu như luôn báo cáo những khoảng trống này cho quản lý trước khi thực hiện bất kỳ thay đổi nào.
- Săn tìm các bản ghi trùng lặp "vô lý": Về mặt logic, một nhân viên không thể có hai mức lương cơ bản khác nhau cho cùng một công việc tại cùng một thời điểm. Chúng ta sử dụng Conditional Formatting (Định dạng có điều kiện) để làm nổi bật các trường hợp trùng lặp này, sau đó bắt đầu trao đổi với bộ phận nguồn để tìm ra đâu là bản ghi "sự thật".
- Kiểm tra trực giác: Cuối cùng, chúng ta tìm kiếm những điểm bất thường. Đây là nơi trực giác của một nhà phân tích phát huy tác dụng. Mức lương đó có vẻ quá cao so với khu vực đó không? Ngày bắt đầu làm việc có bị đặt ở tương lai không? Điều này đòi hỏi mắt nhìn của con người và sự giao tiếp liên tục.
- Ràng buộc của tệp mẫu (Template): Dữ liệu phải được làm sạch để khớp với một "Template tải lên" cụ thể, nơi mà chỉ cần một khoảng trắng thừa trong một ô cũng sẽ khiến toàn bộ hệ thống từ chối tệp tin. Thông thường, khách hàng thậm chí sẽ không làm theo đúng Template đã được đưa cho họ.
- Lưu vết kiểm tra (Audit Trails): Luôn sao lưu, giữ một bản dữ liệu thô (raw) và một bản sạch (clean) cho công việc của bạn. Trong HR, nếu ai đó hỏi tại sao lương của một nhân viên bị thay đổi trong báo cáo, bạn cần phải có khả năng trình bày logic từng bước về cách bạn đã làm sạch dữ liệu đó.
3. Khoảng cách thực sự giữa lý thuyết và thực tế
Sự khác biệt giữa data cleaning theo lý thuyết và trong thực tế không nằm ở tools, mà nằm ở cách bạn hiểu và xử lý dữ liệu.
| Bạn học | Thực tế |
|---|---|
| Data có cấu trúc rõ ràng | Data gắn liền với hoàn cảnh thực tế |
| Thiếu giá trị có thể sửa | Thiếu giá trị có thể có nhiều ý nghĩa |
| Duplicate là lỗi phải xoá | Duplicate là lịch sử |
| Clean = Đúng | Clean có thể sai |
4. Kết luận
Data cleaning thường được dạy như một quy trình kỹ thuật - một việc bạn làm để “sửa” dữ liệu bẩn.
Nhưng trong thực tế, nó không chỉ đơn giản như vậy. Đó là một quá trình đưa ra quyết định:
- Giữ lại điều gì
- Loại bỏ điều gì
- Tin tưởng điều gì
- Và quan trọng nhất, là điều gì không nên thay đổi
Bởi vì mỗi dataset đều là một sự phản ánh của thế giới thực, mà dataset trong thế giới thực thì hiếm khi sạch sẽ, nhất quán hay được cấu trúc hoàn hảo.
Mục tiêu của data cleaning không phải là làm cho dữ liệu trông “đẹp” hơn, mà là làm cho dữ liệu trở nên có thể sử dụng được nhưng không làm mất đi ý nghĩa của nó.
Với những dataset đơn giản, điều này khá dễ dàng. Nhưng trong những lĩnh vực thực tế như HR, nó đòi hỏi context, giao tiếp và sự phán đoán cẩn thận.
Và nếu có một điều cần nhớ, thì đó là:
Rủi ro lớn nhất trong data cleaning không phải là dữ liệu bẩn, mà là việc tự tin làm sạch nó theo cách sai.
Chưa có bình luận nào. Hãy là người đầu tiên!