
Having covered the fundamental theory and metrics (Accuracy, Precision, Recall, Specificity, F1-Score) along with the Precision-Recall trade-off, we will now examine the practical implementation of the Confusion Matrix and associated issues
5. The Battle of the Curves: When Data is "Skewed"
Imagine you are hunting for a "fraudster" in a sea of honest people (a fraud detection problem). Your data is severely imbalanced: 99.9% are good users (Negative Class), and only 0.1% are fraudsters (Positive Class).
This is exactly where standard evaluation metrics begin to play "visual tricks" on us.
5.1. The Deception of the ROC Curve
The ROC (Receiver Operating Characteristic) curve is very popular, but it has a fatal weakness: It is too "forgiving" to the Negative class.
Let's look at the formula for the False Positive Rate (FPR) – the x-axis of the ROC:
$$FPR = \frac{FP}{FP + TN}$$
* The Problem: In fraud detection, the number of clean transactions (TN - True Negatives) is usually massive (millions).
* The Consequence: Even if your model falsely accuses thousands of innocent people (FP skyrockets), that gigantic denominator $(FP + TN)$ will swallow up the error.
* The Conclusion: remains tiny ROC-AUC stays sky-high (e.g., 0.95) You think the model is great, but in reality, it's spamming false alarms.
5.2. The PR Curve (Precision-Recall): The Strict Judge
Unlike the ROC, the Precision-Recall (PR) curve is the most fair and impartial judge for imbalanced data. Why? Because it doesn't care about TN (the number of good people correctly identified).
The Precision Formula:
$$Precision = \frac{TP}{TP + FP}$$
- The Naked Truth: When false alarms (FP) go up, the denominator increases directly Precision drops immediately. There are no "millions of good people" (TN) to hide this mistake.
- Rule of Thumb: If your data is skewed, ditch the ROC. A model with an ROC of 0.95 might only have a PR of 0.30. The PR curve shows you a darker, but far more honest picture.
- Technical Note: When plotting the PR chart, never connect points with a straight line (linear interpolation) because the relationship between Precision and Recall is non-linear (hyperbolic). Drawing straight lines will lead to an overestimation of the area (AUC).
6. Cost-Sensitive Learning: The Business Case
In school, getting a multiple-choice question wrong costs you 0.2 points regardless of the question. But in the real world, the price of a mistake is never equal.
$$Total Cost = (FP \times \text{Cost of False Alarm}) + (FN \times \text{Cost of Missed Detection})$$
* Mistakenly flagging an email as Spam (FP): Just a minor annoyance.
* Missing a cancer patient diagnosis (FN): The consequence is a human life.
6.1. The Cost Matrix: Everything Has a Price
Instead of just counting errors, we attach a "price tag" (or risk factor) to each type of mistake.
Your goal now shifts from Maximum Accuracy to Minimum Total Cost:
6.2. Three Ways to Teach the Model to "Fear" Cost
How do we make the model understand that "it's better to raise a false alarm than to miss a threat"?
-
Threshold Moving – The Quickest Way:
* Normally, we only classify as Positive if the probability is > 50%.
* If missing a fraud (FN) is 9 times more expensive than a false alarm (FP), we lower the bar. Just a 10% suspicion is enough to trigger an alarm!
* Optimal Threshold Formula :
$$T = \frac{C(1,0)}{C(1,0) + C(0,1)}$$ -
Class Weighting – The Root Cause Fix:
* During training, we explicitly order the model: "If you guess the Positive class wrong, I will penalize you 10 times harder than if you guess the Negative class wrong."
* In code (e.g., Scikit-learn), you just need to addclass_weight='balanced'. -
MetaCost – "Old Wine in New Bottles":
* This is a clever technique: We re-label the input data based on cost, then feed it into a standard model. The model learns as usual, but because the data has been "adjusted" for cost, the output automatically becomes economically optimized.
7. Strategic Summary: Bringing the Model to Reality
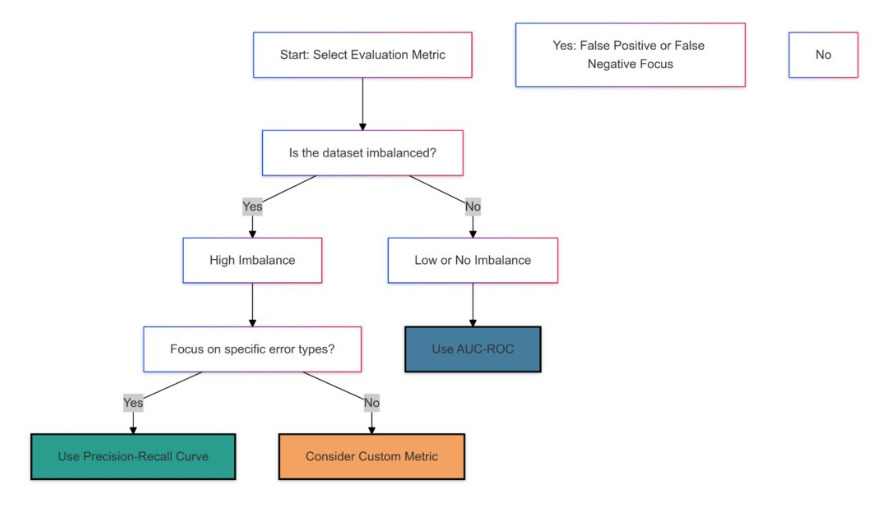
To avoid getting lost in theory, just remember these 4 Golden Rules when working in the field:
- Don't Trust a Single Number: Never report just the Accuracy to your boss. Look at the Confusion Matrix to see the distribution of errors.
-
Choose Metrics Based on Business Goals:
* Healthcare/Security (Fear of Missing Out): Optimize Recall.
* Spam/Hiring (Fear of False Accusations): Optimize Precision.
* Need Balance: Use F1-score. -
Imbalanced Data: Treat Accuracy as an enemy, ROC as a casual acquaintance, and PR-AUC as your soulmate.
- Business Mindset: Ultimately, a good model is one that saves costs or generates profit. Use the Cost Matrix to prove the real-world value of your AI.
Chưa có bình luận nào. Hãy là người đầu tiên!