
Mở đầu
Theo nghiên cứu của Reichheld (2001), chi phí giữ chân khách hàng thấp hơn 5–7 lần so với thu hút khách hàng mới. Trong E-commerce, tỷ lệ churn trung bình lên tới 30–40% mỗi năm, trong khi 80% doanh thu đến từ 20% khách hàng trung thành. Vì vậy, churn không chỉ là chỉ số rời bỏ mà còn phản ánh vấn đề trong trải nghiệm người dùng.
Một mô hình churn hiệu quả không chỉ dự đoán ai sẽ rời đi, mà quan trọng hơn là phát hiện sớm ai có nguy cơ rời đi để can thiệp kịp thời.
Dựa trên mục tiêu đó, dự án Churn Alert được xây dựng như một pipeline hoàn chỉnh, chuyển hóa dữ liệu đầu vào thành sản phẩm ứng dụng (Streamlit), thay vì chỉ dừng ở mô hình phân loại.
Dataset sử dụng là E-commerce Customer Churn (Kaggle) gồm 5,630 khách hàng với 20 đặc trưng (hành vi, nhân khẩu học). Tỷ lệ churn là 16.8% (~1/6 khách hàng), phản ánh rõ bài toán mất cân bằng dữ liệu trong thực tế.
Toàn bộ quy trình xây dựng mô hình trong dự án Churn Alert, từ bước xử lý dữ liệu ban đầu đến triển khai ứng dụng thực tế như sau:
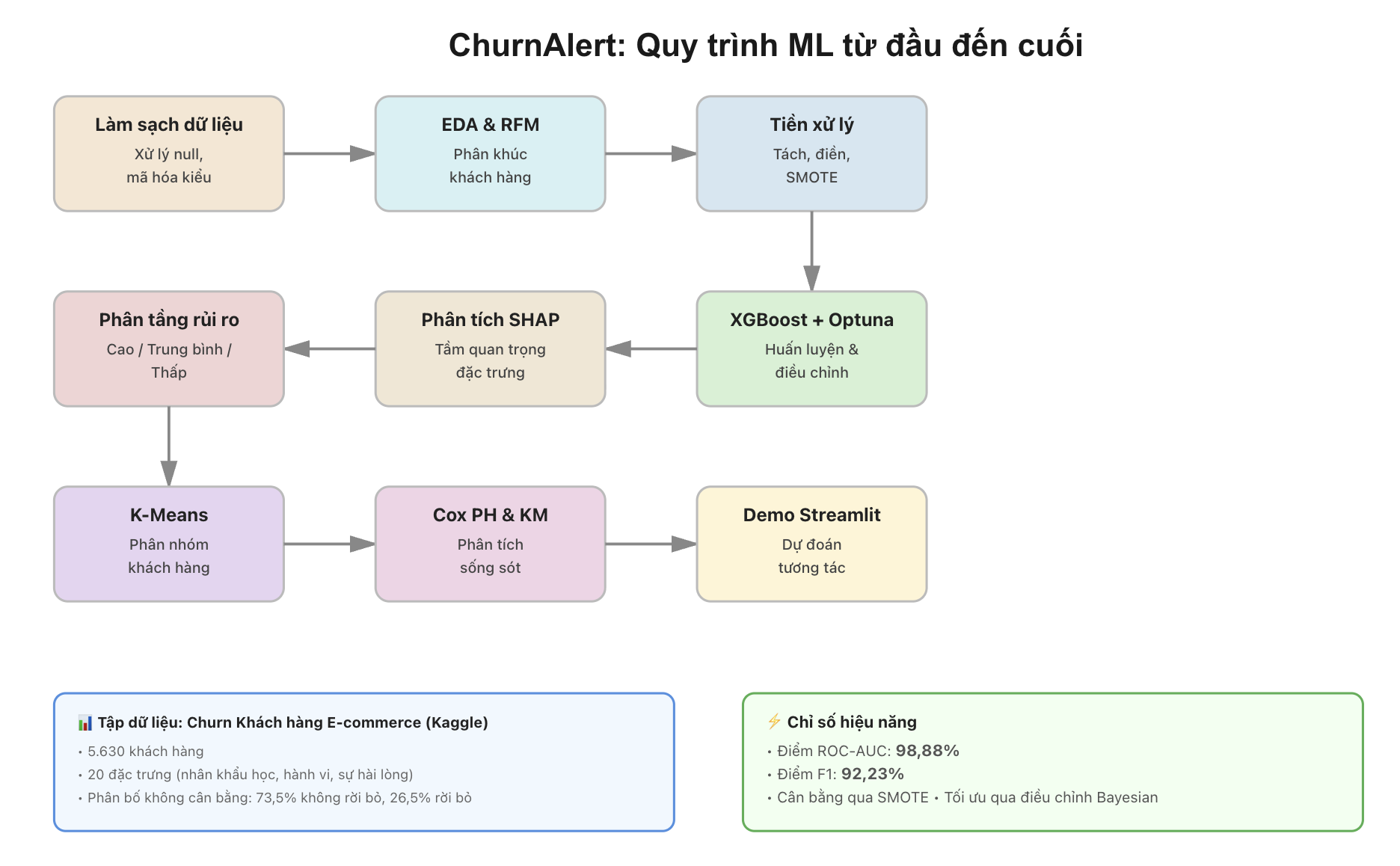
Nguồn: Generative AI
1. Khởi tạo và Làm sạch Dữ liệu
-
Chuyển đổi kiểu dữ liệu: Đưa các biến mang tính chất phân loại như CityTier và Complain về đúng định dạng categorical/object.
-
Xử lý lỗi đánh máy: Hợp nhất các giá trị bị gõ sai hoặc đồng nghĩa để tránh làm nhiễu mô hình. Ví dụ: Gom 'Mobile' và 'Mobile Phone' thành một; gom 'CC' thành 'Credit Card', 'COD' thành 'Cash On Delivery'
2. Phân tích Dữ liệu Thiếu
Thay vì điền khuyết bừa bãi, quy trình tiếp cận theo chuẩn thống kê:
1. Trực quan hóa (Missingness Matrix): Xác định các cột bị thiếu dữ liệu (như Tenure, WarehouseToHome, OrderCount,...).
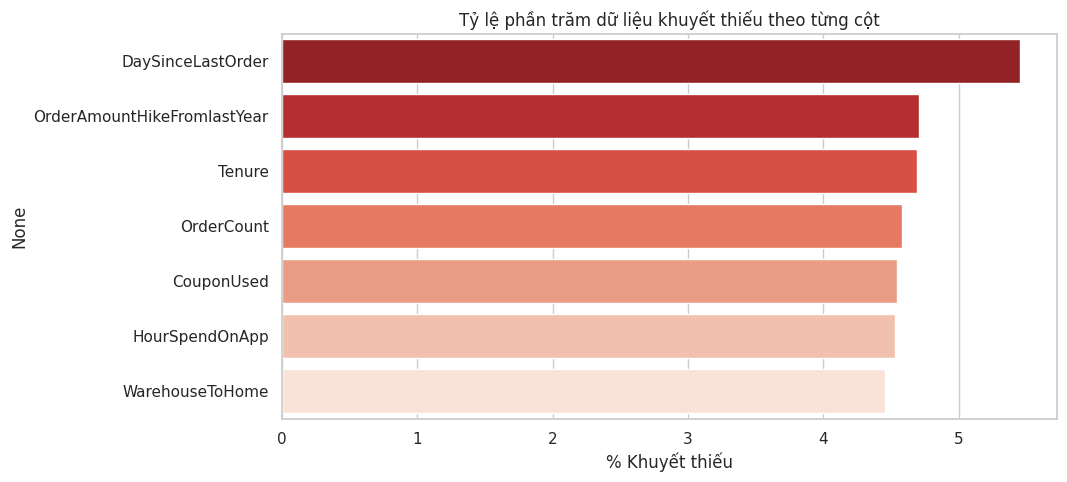
Nguồn: Kết quả chạy chương trình
Trực quan hóa Mẫu hình Thiếu hụt:
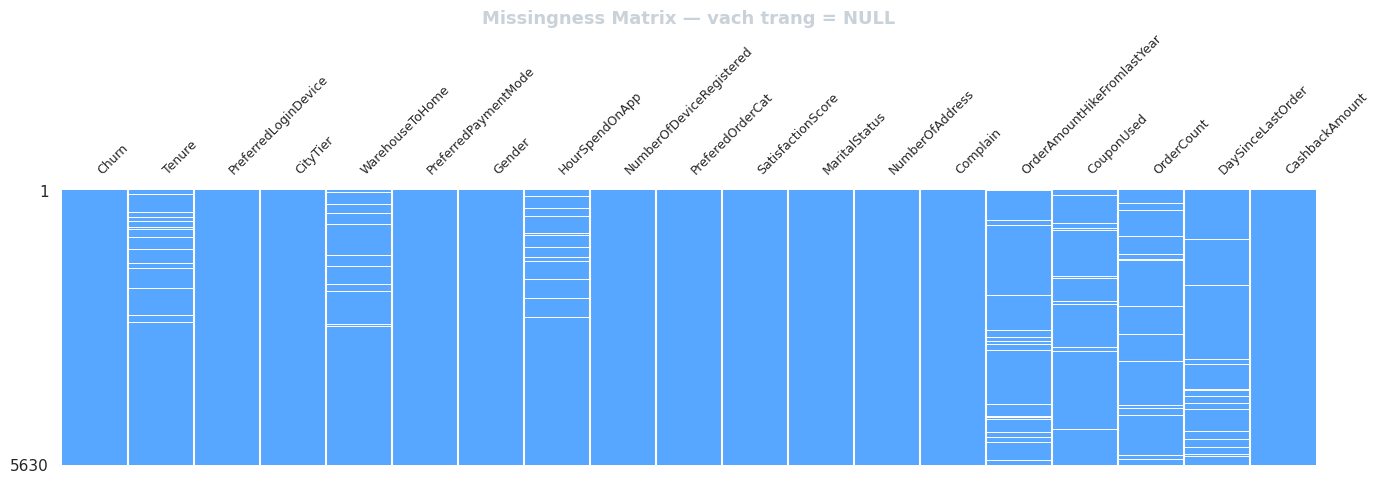
Nguồn: Kết quả chạy chương trình
Biểu đồ này giúp xem xét liệu dữ liệu bị thiếu là lác đác ngẫu nhiên hay bị mất theo từng mảng lớn, có thể thấy các vạch trắng xuất hiện khá mỏng và rải rác ở 7 cột. Số lượng thiếu không quá nghiêm trọng đến mức phải xóa bỏ cột, do đó chiến lược Điền khuyết (Imputation) là hoàn toàn khả thi.
2.Kiểm định MCAR/MAR/MNAR:
Trả lời câu hỏi: "Việc khách hàng bị thiếu thông tin có liên quan trực tiếp đến việc họ quyết định rời bỏ (Churn) hay không?"
-
Nhóm MCAR (Thiếu hoàn toàn ngẫu nhiên): Ở cột DaySinceLastOrder hay HourSpendOnApp. Sự thiếu hụt này không mang ý nghĩa gì đặc biệt.
-
Nhóm MAR/MNAR (Thiếu có chủ đích - Một tín hiệu cảnh báo): Khi xét đến cột Tenure và WarehouseToHome, những người bị trống dữ liệu có tỷ lệ Churn lên tới $30.7\%$ và $33.5\%$.
Insight: Nó có thể là do những khách hàng này vừa tạo tài khoản, dùng thử thấy không thích nên lập tức rời đi nên khiến hệ thống chưa kịp ghi nhận thời gian gắn bó. Nếu điền khuyết một cách mù quáng, mô hình sẽ bị mất đi tín hiệu quý giá này.
3. Phân tích phân phối (Skewness): Vẽ biểu đồ phân phối để xem độ lệch. Do hầu hết các cột chứa ngoại lai (lệch phải), phương án điền khuyết an toàn là Median (Trung vị) hoặc dùng KNN Imputer sẽ mang lại hiệu quả tốt hơn
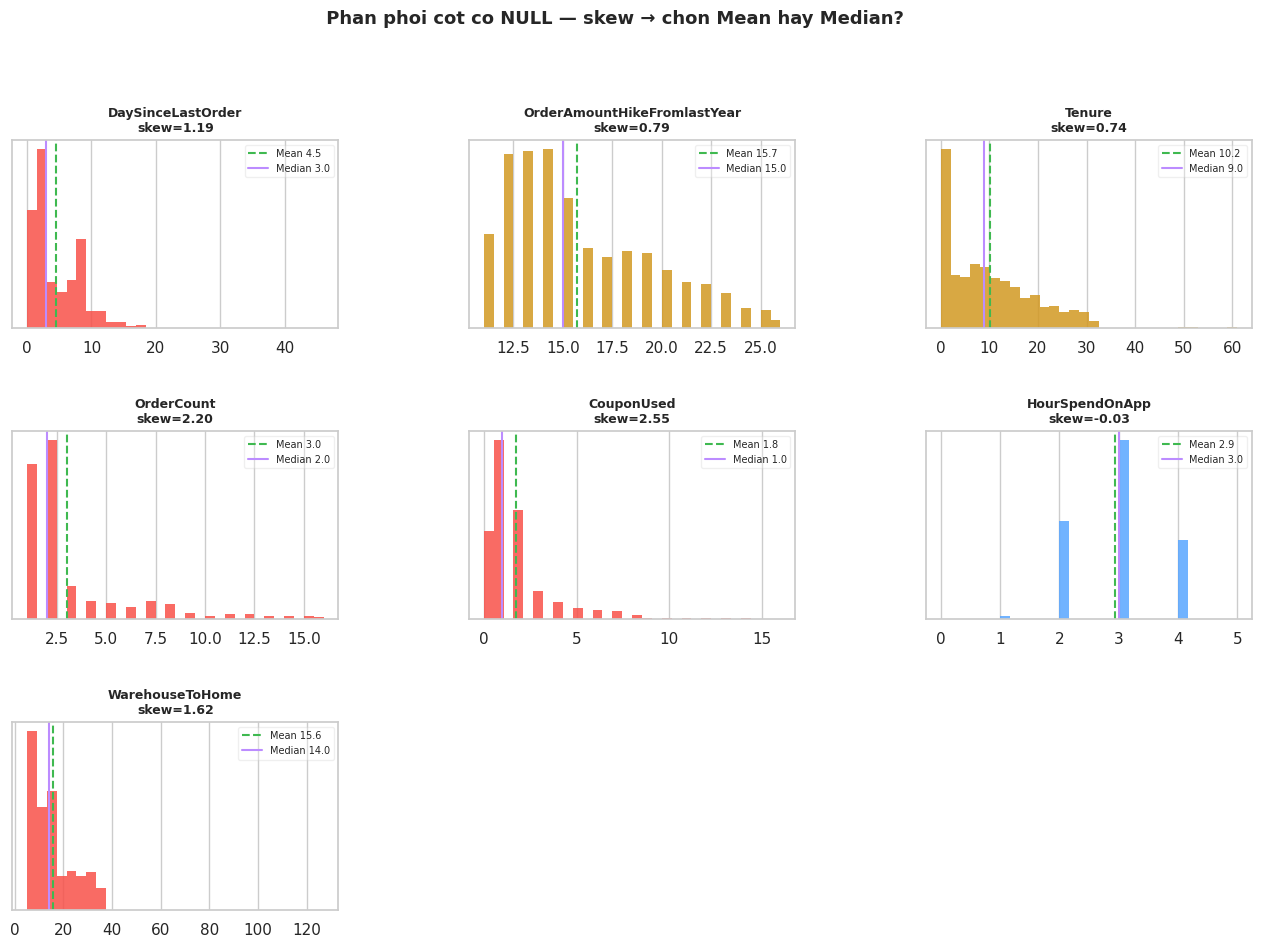
Nguồn: Kết quả chạy chương trình
3. Khám phá Dữ liệu Chuyên sâu
3.1. Phân tích Tổng quan Biến Mục tiêu
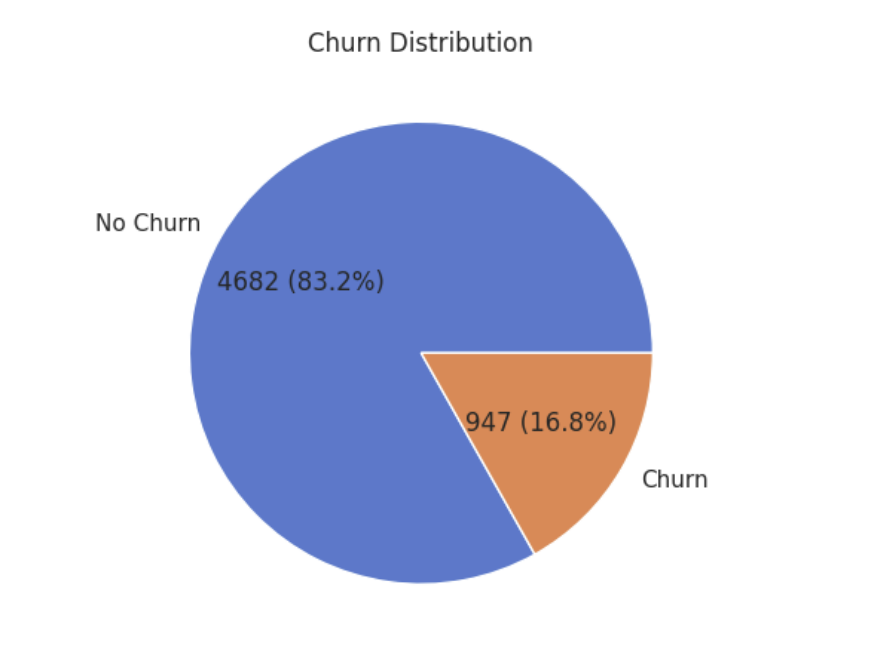
Nguồn: Kết quả chạy chương trình
Biểu đồ cho thấy sự Mất cân bằng lớp (Class Imbalance) cực kỳ nghiêm trọng. Sự chênh lệch này là lời cảnh báo sớm cho khâu Model. Nếu đưa dữ liệu này thẳng vào ML, mô hình sẽ trở nên "lười biếng" và đoán toàn bộ là "Không rời bỏ". Vì vậy, có căn cứ để áp dụng thuật toán SMOTE (sinh mẫu nhân tạo) nhằm cân bằng lại dữ liệu.
3.2. Thời gian gắn bó và mức độ hài lòng
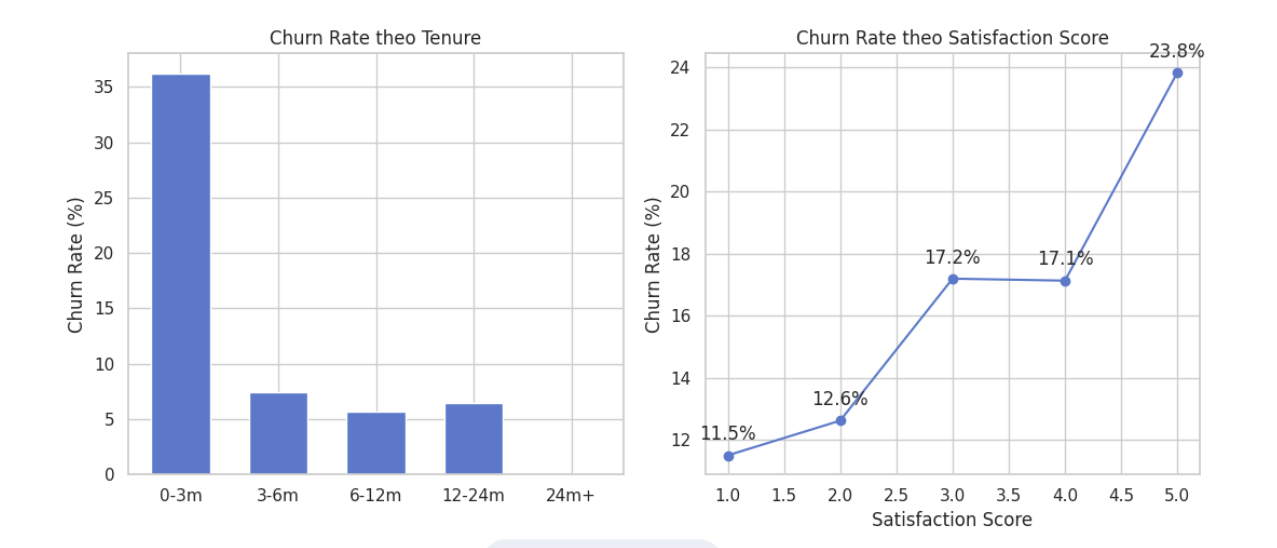
Nguồn: Kết quả chạy chương trình
Theo Tenure: Kết quả chỉ ra một "thung lũng tử thần" ở giai đoạn 0-3 tháng đầu tiên với tỷ lệ rời bỏ cao chót vót. Nếu vượt qua được mốc 12 tháng, tỷ lệ Churn giảm xuống mức cực kỳ an toàn.
Business insight: Doanh nghiệp cần dồn toàn bộ ngân sách khuyến mãi vào quy trình Onboarding (chào mừng) trong 90 ngày đầu tiên.
Theo Satisfaction Score: Đồ thị không hề đi xuống thẳng băng như logic thông thường (điểm cao thì ở lại), mà nó có hình chữ U úp ngược. Nhóm khách hàng chấm 5 sao lại có tỷ lệ rời bỏ cao nhất ($23.8\%$).
Business insight: Cần xem xét lại hệ thống đánh giá, có thể khách hàng bị ép đánh giá 5 sao để nhận voucher mua hàng 1 lần rồi xóa app; hoặc nền tảng chủ yếu bán các mặt hàng mua 1 lần (như tủ lạnh, tivi), dù hài lòng nhưng rất lâu mới quay lại.
3.3. Săn tìm Sự Trùng lặp Dữ liệu
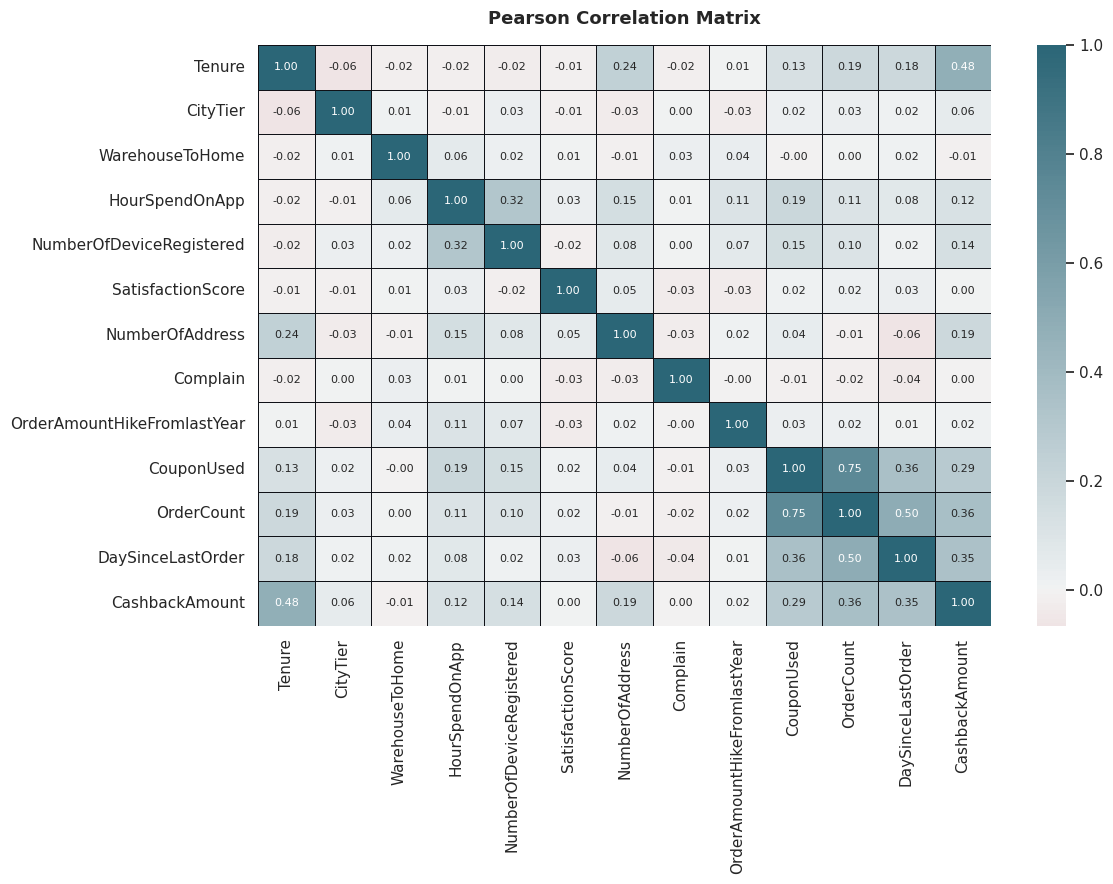
Nguồn: Kết quả chạy chương trình
Biểu đồ Pearson (Cho biến dạng số): OrderCount và CouponUsed có tương quan khá mạnh ($0.75$). Khách hàng chốt nhiều đơn là nhờ họ săn được nhiều mã giảm giá.
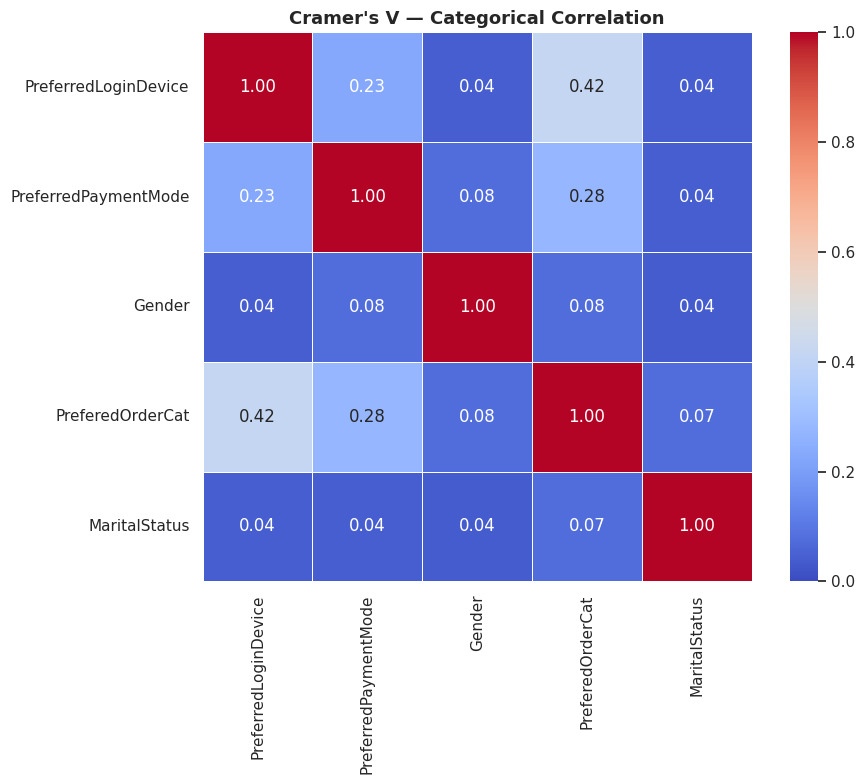
Nguồn: Kết quả chạy chương trình
Biểu đồ Cramer's V (Cho biến phân loại): giá trị cao nhất chỉ là $0.42$ (giữa Cách thanh toán và Danh mục hàng), khẳng định dữ liệu chữ phân mảnh rất tốt, đa dạng và sạch để đưa vào mô hình.
3.4. Tương quan điểm - nhị phân
Dùng phép thống kê này để so sánh trực tiếp xem: Cột số nào đẩy tỷ lệ Churn (biến nhị phân 0-1) lên cao, và cột nào kéo nó xuống.
Kết quả:
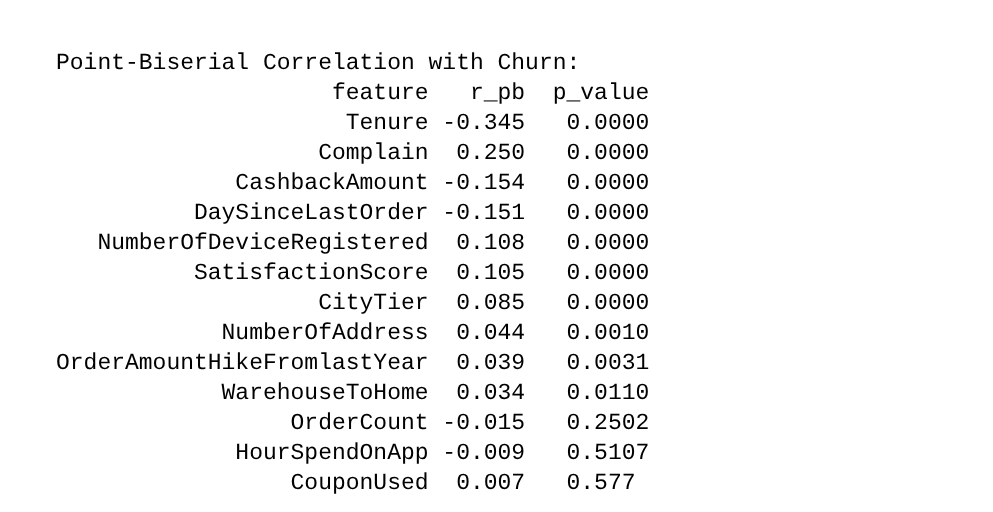
Nguồn: Kết quả chạy chương trình
-
Tương quan nghịch: Tenure và CashbackAmount là 2 yếu tố giữ chân người dùng mạnh nhất. Việc bơm tiền hoàn hợp lý đang phát huy tác dụng.
-
Tương quan thuận: NumberOfDeviceRegistered. Khách hàng dùng càng nhiều thiết bị, khả năng Churn càng cao. Có thể họ là dân săn sale ảo, hoặc app bị văng/lỗi đồng bộ trên nhiều thiết bị khiến họ bực mình.
3.5. Phác họa Chân dung Kẻ Rời Bỏ
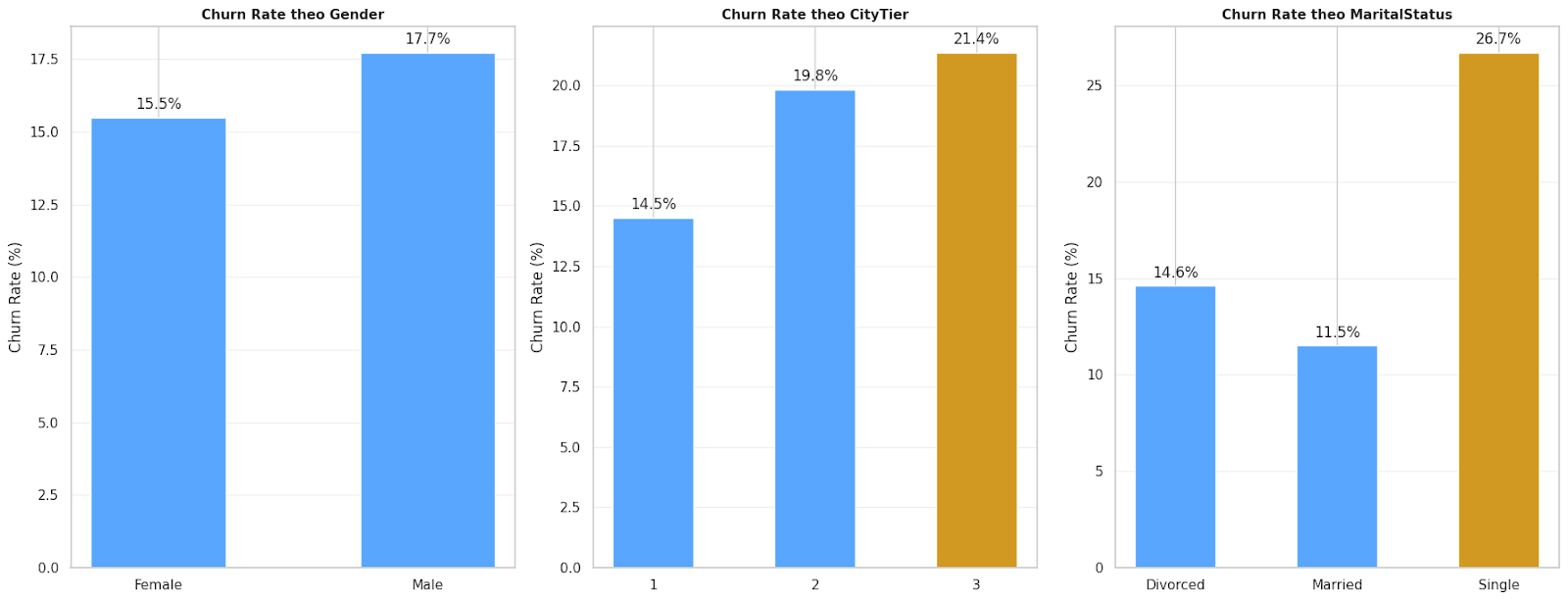
Nguồn: Kết quả chạy chương trình
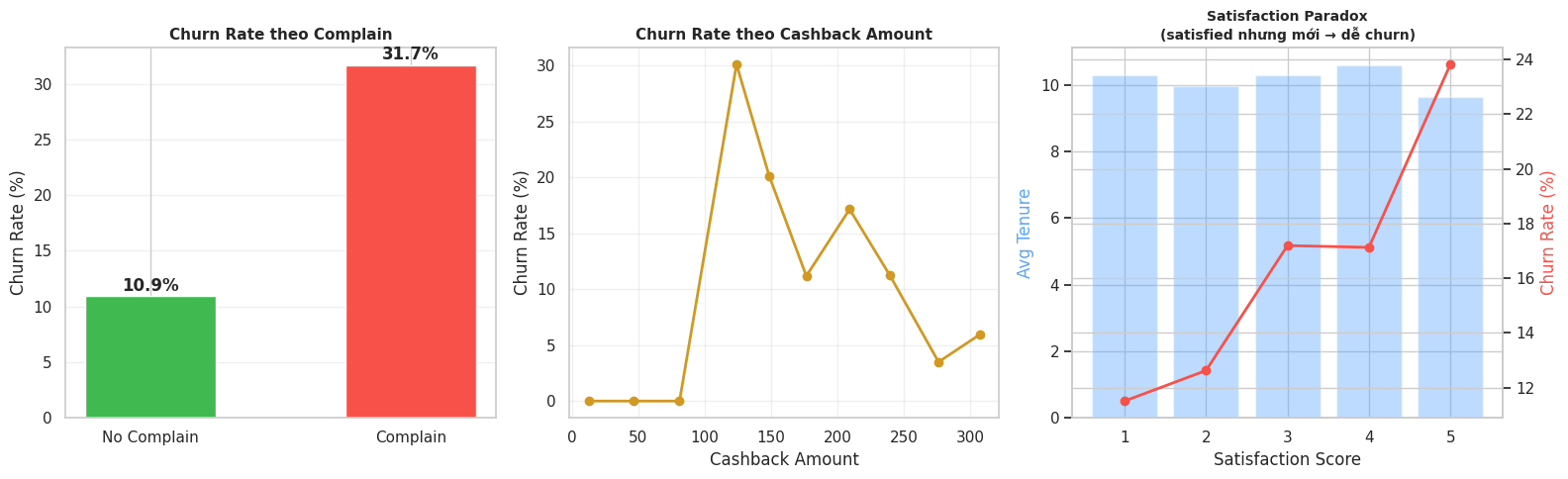
Nguồn: Kết quả chạy chương trình
Khách hàng Rủi ro cao: Là Nam giới, tình trạng Độc thân, sống ở khu vực City Tier 3 (Thành phố loại 3), và Đã từng khiếu nại (Complain = 1).
Insight: Biểu đồ cho thấy khách hàng từng có khiếu nại có tỷ lệ rời bỏ lên tới $31.7\%$ (gấp 3 lần người không khiếu nại), cho thấy hệ thống chăm sóc khách hàng đang xử lý tệ.
4. Phân khúc Khách hàng bằng RFM
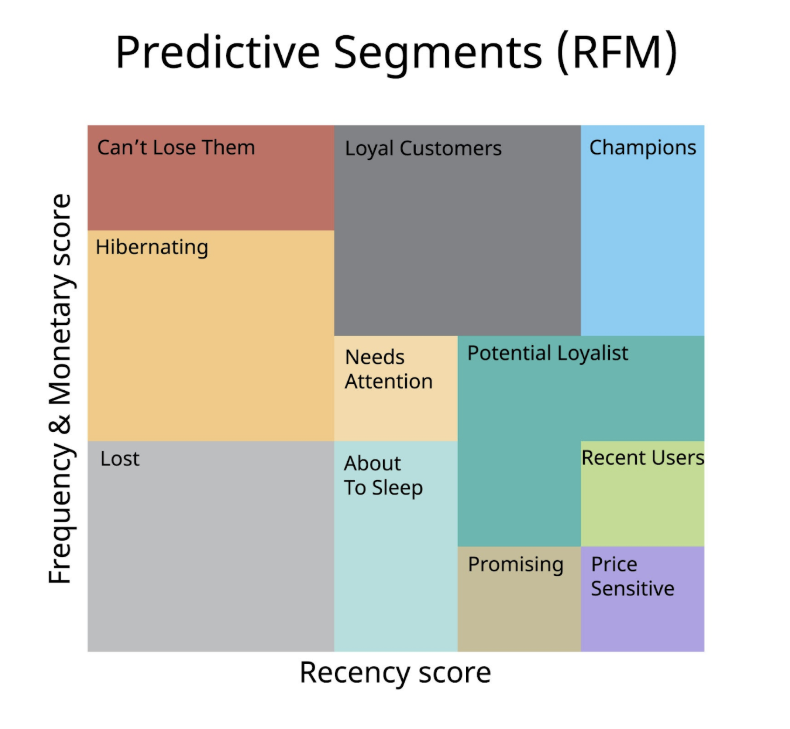
Nguồn: Internet
4.1. Định nghĩa lại R-F-M
Vì tập dữ liệu gốc không có lịch sử từng đơn hàng cụ thể, cần ánh xạ trực tiếp 3 chữ cái R-F-M vào 3 cột dữ liệu có sẵn một cách rất logic:
-
R (Recency - Độ mới): Dùng cột DaySinceLastOrder (Số ngày kể từ đơn hàng cuối). Khách mua càng gần đây thì điểm R càng cao.
-
F (Frequency - Tần suất): Dùng cột OrderCount (Tổng số đơn hàng). Mua càng nhiều lần, điểm F càng cao.
-
M (Monetary - Giá trị): Vì không có cột tổng số tiền đã chi, nhóm sử dụng CashbackAmount (Số tiền hoàn lại) làm biến đại diện.
4.2. Dùng SQL trong Python
Khởi tạo một cơ sở dữ liệu ảo và đẩy dữ liệu vào.
import sqlite3
import pandas as pd
# Khởi tạo in-memory database
conn = sqlite3.connect(":memory:")
# Đẩy dữ liệu vào
df.to_sql('customers', conn,
if_exists='replace', index=False)
4.3. Chấm điểm Khách hàng bằng Window Function (NTILE)
Sử dụng hàm phân tích phân rã NTILE(5) của SQL. Thuật toán tự động xếp hàng khách hàng, sau đó chia làm 5 phần. Khách hàng nằm ở phần nào sẽ được chấm điểm từ 1 đến 5 cho từng chỉ số R, F, và M.
-
Với F và M: Xếp hạng tăng dần, nghĩa là mua càng nhiều đơn/hoàn tiền càng nhiều thì điểm càng xích lên 4, 5.
-
Với R (DaySinceLastOrder): Phải xếp hạng giảm dần, bởi vì số ngày nghỉ mua càng THẤP (mua gần đây) thì điểm R mới phải càng CAO.
4.4. Gán nhãn Phân khúc
Sau khi mỗi khách hàng có một bộ điểm (ví dụ: R=5, F=5, M=5 là khách VIP), dùng lệnh CASE WHEN trong SQL để dán nhãn họ thành các nhóm (Cohorts) mang tính kinh doanh:
-
Champions / Loyal: Nhóm xuất sắc, điểm F và M đều cao.
-
Recent Customers: Nhóm khách mới, điểm R cao (mới mua) nhưng F và M chưa cao.
-
At Risk / Hibernating: Nhóm nguy cơ, điểm R thấp (lâu rồi không mua).
4.5. Phát hiện cú sốc từ Dữ liệu
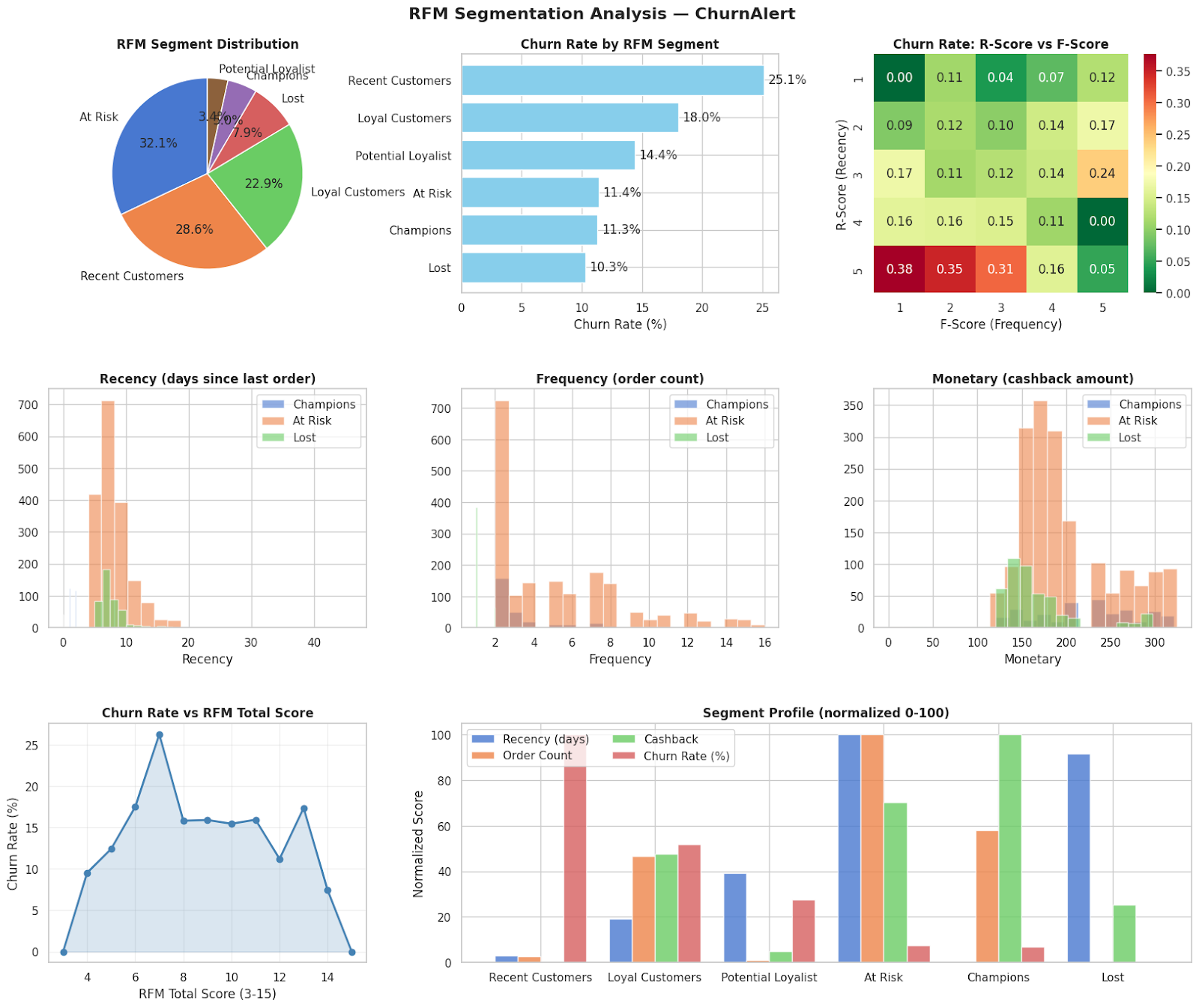
Nguồn: Kết quả chạy chương trình
Sau khi chia nhóm, đến bước tính toán Tỷ lệ Churn (Rời bỏ) cho từng nhóm và vẽ biểu đồ. Lúc này, một Insight "chí mạng" xuất hiện:
- Theo lẽ thường, nhóm "At Risk" (lâu không mua) sẽ là nhóm dễ rụng nhất nhưng dữ liệu thực tế lại chỉ ra: Nhóm "Recent Customers" lại có tỷ lệ rời bỏ cao đỉnh điểm, lên tới $25.1\%$. Nhóm Champions tỷ lệ rụng chỉ $<10\%$.
Insight: Doanh nghiệp đang rơi vào tình trạng "Lủng đáy thùng". Marketing có thể đang hiệu quả, thu hút khách mới liên tục nhưng trải nghiệm quá tệ. Cần chuyển ngay ngân sách từ việc "Tìm khách mới" sang "Chăm sóc khách mới trong 90 ngày đầu".
4.6. Thêm feature RFM vào model
-
Lấy tổng điểm RFM (rfm_total = R + F + M) và các nhãn phân khúc vừa tạo, ghép trở lại vào tập dữ liệu gốc để làm thành các Đặc trưng mới.
-
Mục đích: Nếu đưa con số tổng điểm rfm_total này cho thuật toán XGBoost học, mô hình sẽ dự đoán khách hàng Churn chính xác hơn rất nhiều so với việc chỉ đưa các con số thô như Số ngày, Số đơn. (Khách có rfm_total cao thì xác suất Churn sẽ thấp).
4.7. RFM Segment có predict được churn không?
Lấy tổng điểm rfm_total làm một "mô hình dự đoán mini". Điểm RFM càng thấp -> Tỷ lệ Churn càng cao. Sau đó, đem chấm điểm bằng thước đo ROC-AUC của Machine Learning.
Kết quả: hệ thống RFM đơn giản này cho ra một chỉ số ROC-AUC nhất định (dù thấp hơn mức $0.95+$ của mô hình XGBoost chuyên nghiệp).
Insight cốt lõi: "RFM đơn thuần kém hơn ML, nhưng dễ giải thích và không cần training".
5. Preprocessing
Trong bước tiền xử lý dữ liệu, nhóm đã thực hiện một pipeline gồm nhiều kỹ thuật nhằm chuẩn bị dữ liệu tối ưu cho mô hình học máy:
5.1 Encoding
Trong bộ dữ liệu thương mại điện tử, xuất hiện nhiều biến đầu vào ở dạng phân loại (categorical) như giới tính, thiết bị, khu vực hay phương thức thanh toán. Tuy nhiên, các mô hình học máy như XGBoost chỉ xử lý được dữ liệu số, nên cần thực hiện encoding để chuyển các giá trị dạng chữ thành số.
Việc encoding là cần thiết vì:
- Mô hình không thể xử lý dữ liệu dạng văn bản.
- Giúp giữ lại các thông tin quan trọng liên quan đến hành vi churn.
- Tránh việc mô hình hiểu sai thứ tự giữa các nhóm không có tính thứ bậc.
- Đảm bảo dữ liệu đầu vào nhất quán cho toàn bộ pipeline xử lý và huấn luyện
5.2 Train-Test Split
-
Dữ liệu được chia thành training set và test set (thường theo tỷ lệ 80:20).
-
Mục đích: đảm bảo mô hình được đánh giá trên dữ liệu chưa từng thấy → tránh overfitting.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
# 1. Chia dữ liệu TRƯỚC (Dữ liệu thô, chưa encode)
X = df.drop(columns=['Churn'])
y = df['Churn'].astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 2. Khởi tạo Encoder
# handle_unknown='ignore' giúp model không bị crash khi gặp giá trị lạ ở tập Test
encoder = OneHotEncoder(handle_unknown='ignore', sparse_output=False, drop='first')
# 3. FIT chỉ trên Train - TRANSFORM trên cả hai
# Xác định các cột chữ cần encode
cat_cols = X_train.select_dtypes(include=['object','category']).columns.tolist()
# Học từ Train
encoder.fit(X_train[cat_cols])
# Áp dụng (Tạo ra mảng số)
X_train_enc = encoder.transform(X_train[cat_cols])
X_test_enc = encoder.transform(X_test[cat_cols])
5.3 KNN Imputation
Trong quá trình tiền xử lý, bộ dữ liệu xuất hiện tỷ lệ giá trị thiếu khá lớn.Bộ dữ liệu có nhiều giá trị thiếu, và các phương pháp đơn giản (mean/mode hoặc suy luận theo cột) không phù hợp vì làm mất cấu trúc dữ liệu. Do đó, nhóm sử dụng KNN Imputation để ước lượng giá trị thiếu dựa trên các quan sát tương tự.
Cụ thể, với mỗi điểm bị thiếu, thuật toán tìm K neighbors gần nhất (theo khoảng cách Euclidean), sau đó:
- Lấy trung bình với biến số
- Lấy mode với biến phân loại
# ── Scaling & KNN Impute — fit ONLY on train ──
num_cols_imp = X_train.select_dtypes(include=[np.number]).columns
# 1. Bắt buộc Scaling trước khi KNN
scaler = MinMaxScaler()
X_train[num_cols_imp] = scaler.fit_transform(X_train[num_cols_imp])
X_test[num_cols_imp] = scaler.transform(X_test[num_cols_imp])
# 2. Bây giờ KNN mới hoạt động chính xác
imputer = KNNImputer(n_neighbors=5)
X_train[num_cols_imp] =imputer.fit_transform(X_train[num_cols_imp])
X_test[num_cols_imp]=imputer.transform(X_test[num_cols_imp])
Phương pháp này giúp giữ được mối quan hệ giữa các đặc trưng, phản ánh dữ liệu tốt hơn so với cách điền giá trị đơn giản. Tuy nhiên, KNN nhạy với scaling, tốn chi phí tính toán và có thể làm mượt dữ liệu, nên chỉ hiệu quả khi dữ liệu có tính tương đồng rõ ràng.
Ví dụ: Hai khách hàng có hành vi mua sắm tương tự nhau (số lần mua, thời gian truy cập, giá trị đơn hàng) thì nếu một người bị thiếu dữ liệu, ta có thể dự đoán giá trị đó dựa trên người còn lại.
5.4 SMOTE (Synthetic Minority Over-sampling Technique)
Trong bài toán dự đoán churn, dữ liệu thường gặp tình trạng mất cân bằng (imbalanced data), khi số lượng khách hàng không churn (0) lớn hơn rất nhiều so với churn (1). Điều này khiến mô hình dễ bị thiên lệch và dự đoán tốt cho lớp majority nhưng kém với lớp minority.
Để giải quyết vấn đề này, phương pháp SMOTE (Synthetic Minority Over-sampling Technique) được sử dụng nhằm tăng số lượng mẫu của lớp thiểu số một cách thông minh.
#Sử dụng pd.get_dummies hoặc OneHotEncoder (tốt nhất là OneHotEncoder để tránh leakage)
import pandas as pd
X_train_encoded = pd.get_dummies(X_train, columns=cat_cols, drop_first=True)
# Lưu ý: Nếu dùng get_dummies ở đây, bạn cũng phải làm tương tự cho X_test sau này
# ── SMOTE — bây giờ sẽ chạy mượt ──
print(f"\nBefore SMOTE: {y_train.value_counts().to_dict()}")
# Dùng dữ liệu đã encoded (X_train_encoded) thay vì X_train gốc
smote = SMOTE(random_state=42, k_neighbors=5)
X_train_res, y_train_res = smote.fit_resample(X_train_encoded, y_train)
Với việc sử dụng SMOTE chúng tôi có thể giải quyết mất cân bằng dữ liệu. Nếu không xử lý imbalance một cách chính xác, có thể dẫn đến việc mô hình có thể đạt accuracy cao nhưng thực chất không phát hiện tốt tỷ lệ churn.
Kết quả: Phân phối lớp (SMOTE Balancing)
# 1. TRƯỚC KHI XỬ LÝ (Imbalanced - 5:1)
# ------------------------------------
# Lớp 0: [████████████████████████] 3746 mẫu
# Lớp 1: [█████] 758 mẫu
# 2. SAU KHI XỬ LÝ (Balanced - 1:1)
# ------------------------------------
# Lớp 0: [████████████████████████] 3746 mẫu
# Lớp 1: [████████████████████████] 3746 mẫu (Synthetic)
# Kết quả: {0: 3746, 1: 3746}`
Sau khi xử lý, tỷ lệ đã được cân bằng hoàn toàn
6. Modelling (XGBoost + Optuna)
Sau khi hoàn tất các bước tiền xử lý dữ liệu, mô hình được sử dụng cho bài toán dự đoán churn là XGBoost, kết hợp với Optuna để tối ưu hóa hyperparameters, từ đó đạt hiệu suất cao nhất.
6.1 Nguyên lý hoạt động:
-
XGBoost (Extreme Gradient Boosting) là mô hình boosting xây dựng các cây quyết định theo dạng tuần tự, trong đó mỗi cây học từ sai số của các cây trước thông qua tối ưu hàm loss. Nhờ khả năng nắm bắt quan hệ phi tuyến và cơ chế regularization (L1, L2, pruning), XGBoost cho hiệu quả cao và kiểm soát tốt overfitting trên dữ liệu dạng bảng.
-
Optuna được sử dụng để tối ưu siêu tham số bằng Bayesian Optimization (TPE), cho phép quá trình tìm kiếm tập trung vào các vùng tham số tiềm năng dựa trên kết quả các trial trước, từ đó hiệu quả hơn so với Grid/Random Search.
-
ImbPipeline đảm bảo SMOTE được áp dụng đúng trong cross-validation: mỗi fold chỉ oversample trên tập train riêng, giúp tránh data leakage và đảm bảo đánh giá mô hình đáng tin cậy.
-
CalibratedClassifierCV được dùng để hiệu chỉnh xác suất dự đoán. Do SMOTE làm thay đổi phân phối dữ liệu, xác suất đầu ra có thể bị lệch; Isotonic Regression giúp đưa các giá trị predict_proba về đúng ý nghĩa xác suất thực, đặc biệt quan trọng cho các quyết định churn.
6.3 Model Performance
Bảng kết quả mô hình:
| - | Model | Threshold | Accuracy | Precision | Recall | F1 | ROC_AUC | PR_AUC |
|---|---|---|---|---|---|---|---|---|
| - | XGBoost (Optuna + Calibrated) | 0.492 | 0.9742 | 0.9399 | 0.9053 | 0.9223 | 0.9888 | 0.9483 |
Phân tích các chỉ số:
| Chỉ số | Ý nghĩa | Kết quả |
|---|---|---|
| Accuracy | Tổng tỷ lệ dự đoán đúng | 97.42% dự đoán đúng (cao nhưng không phải chỉ số quan trọng nhất với imbalanced data) |
| Precision | Trong số người model báo là Churn, bao nhiêu % thật sự Churn | 93.99% — khi model báo "người này sẽ rời", 9/10 lần đúng |
| Recall | Trong số người thật sự Churn, model bắt được bao nhiêu % | 90.53% — cứ 100 người sẽ rời, model bắt được ~87 người |
| F1 Score | Trung bình hài hoà giữa Precision và Recall | 92.23% — rất tốt (gần 1 = hoàn hảo) |
| ROC AUC | Khả năng phân biệt Churn vs Non-Churn của model | 98.88% — xuất sắc (0.5 = random, 1.0 = hoàn hảo) |
| PR AUC | Tương tự ROC AUC nhưng quan trọng hơn với imbalanced data | 94.83% — rất tốt |
Sau khi huấn luyện và tối ưu, mô hình đạt được: AUC = 0.989
Đây là một kết quả rất cao, cho thấy:
-
Mô hình có khả năng phân biệt rất tốt giữa khách churn và không churn
-
Đường ROC gần như lý tưởng → khả năng dự đoán mạnh mẽ
-
Pipeline preprocessing (encoding, imputation, SMOTE) đã hoạt động hiệu quả
6.4 SHAP Explainability
Mặc dù kết quả mô hình XGBoost có hiệu suất rất tốt, nhưng nó lại thuộc trong nhóm black-box model (khó hiểu được bên trong mô hình đã hoạt động và đưa ra dự đoán như thế nào). Điều này sẽ là một điểm hạn chế khi cần giải thích kết quả cho business problem hiện tại đang phải đối mặt.
Và để giải quyết cho chính vấn đề này, phương pháp SHAP (Shapley Additive explanations) được sử dụng với mục đích giải thích và diễn giải các dự đoán của mô hình một cách rõ ràng.
# ── SHAP explainer trên XGBoost core──
xgb_core = inner_pipeline.named_steps["classifier"]
explainer = shap.TreeExplainer(xgb_core)
shap_values = explainer.shap_values(X_test_df)
base_val = float(np.array(explainer.expected_value).squeeze())
# Summary plot
print("SHAP Summary Plot:")
shap.summary_plot(shap_values, X_test_df, show=True)
Bảng tham chiếu kết quả
| Feature | Tác động lên Churn | Loại | Ghi chú |
|---|---|---|---|
| device_per_tenure | Cao → 🔴 Tăng mạnh nhất | Tự tạo | Tín hiệu phân tách sắc nét nhất |
| Complain | Có → 🔴 Tăng | Gốc | Cờ đỏ số 1 trong feature gốc |
| Tenure | Cao → 🟢 Giảm | Gốc | ⚠️ Ngược chiều |
| NumberOfAddress | Cao → 🔴 Tăng | Gốc | Pattern phi tuyến — EDA bỏ sót |
| WarehouseToHome | Cao → 🔴 Tăng | Gốc | Yếu tố logistics |
| MaritalStatus_Single | Có → 🔴 Tăng | Gốc (OHE) | |
| CityTier | Cao → 🔴 Tăng | Gốc | Tier 3 nguy hiểm hơn |
| DaySinceLastOrder | Tín hiệu không rõ | Gốc | Chu kỳ mua thưa — không chắc kết luận |
| CashbackAmount | Cao → 🟢 Giảm | Gốc | ⚠️ Ngược chiều — mỏ neo giữ chân |
| SatisfactionScore | Cao → 🔴 Tăng | Gốc | Nghịch lý 5 sao |
| cashback_per_order | Cao → 🟢 Giảm | ✨ Tự tạo | ⚠️ Ngược chiều |
| PreferedOrderCat_Laptop | Có → 🔴 Tăng | Gốc (OHE) | Hàng mua 1 lần |
| inactivity_ratio | Cao → 🔴 Tăng | ✨ Tự tạo | Bắt được bất thường hành vi |
Kết luận: Ta thu được giá trị đóng góp của từng đặc trưng vào dự đoán của mô hình. Mỗi giá trị SHAP thể hiện mức độ và hướng ảnh hưởng của một feature đến output: giá trị dương làm tăng xác suất churn, trong khi giá trị âm làm giảm xác suất này.
7. Phân tích Cụm
7.1. Vượt qua sự "Cảm tính": Tìm số cụm K tối ưu
Người ta thường gán bừa K=3 hoặc K=4. Để tìm ra con số K chuẩn xác nhất, cần sử dụng:
-
Elbow Method: chạy thử K từ 2 đến 10, đo lường WCSS/Inertia để tìm K tối ưu.
-
Silhouette Score: chọn điểm K có điểm Silhouette cao nhất để chốt hạ.
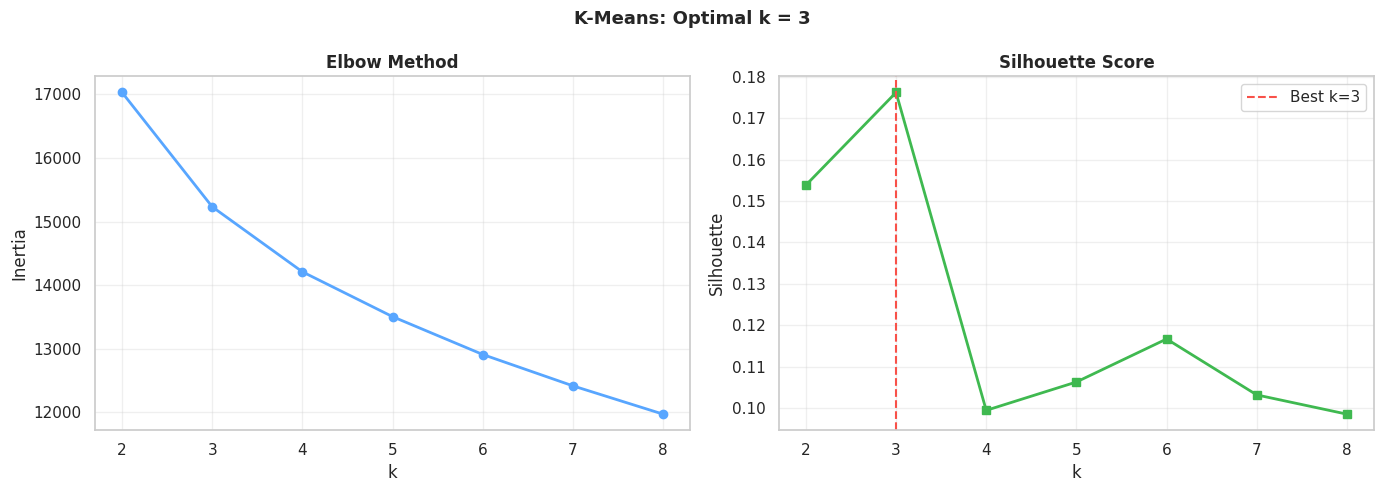
Nguồn: Kết quả chạy chương trình
7.2. Thực thi Phân cụm & Vẽ Chân dung Khách hàng (Cluster Profiling)
Sau khi tìm được K tối ưu, chạy lệnh .fit_predict() để thuật toán tự động gán nhãn, KHÔNG gom nhóm trên dữ liệu X_scaled mà tạo một bản sao từ X_test_raw.
Kết quả:
| segment | count | churn_rate | avg_churn_prob | avg_tenure | churn_rate_pct |
|---|---|---|---|---|---|
| 0 | 92 | 0.543 | 0.57 | 0.0 | 54.3 |
| 1 | 776 | 0.144 | 0.139 | 10.05 | 14.4 |
| 2 | 258 | 0.109 | 0.094 | 14.309 | 10.9 |
- Cụm 0 (avg_tenure $= 0.000$): vừa mới đăng ký tài khoản. Tỷ lệ rời bỏ lên tới $54.3\%$. Xác suất dự đoán của mô hình (avg_churn_prob $= 57\%$) cũng khớp hoàn hảo với thực tế này.
Chiến lược: Doanh nghiệp gặp lỗi nghiêm trọng ở khâu chào mừng người dùng mới (Onboarding), có thể app khó dùng, hoặc họ chỉ tải app để lấy mã giảm giá. Cần thay đổi trải nghiệm khách hàng trong tháng đầu tiên thay vì tìm khách mới.
- Cụm 1 (avg_tenure $= 10.050$): Tỷ lệ rời bỏ ở mức $14\%$ – kiểm soát được đối với ngành E-commerce.
Chiến lược: duy trì các chương trình khuyến mãi đều đặn, tối ưu hóa dịch vụ giao hàng và giải quyết tốt khiếu nại để dần dần chuyển đổi sang nhóm trung thành.
- Cụm 2 (avg_tenure $= 14.309$): Tỷ lệ rời bỏ chỉ $10.9\%$. Mô hình AI cũng dự đoán rủi ro của họ rất thấp (xác suất chỉ $9\%$).
Chiến lược: riển khai các chương trình VIP (hoàn tiền cao hơn, giao hàng miễn phí đặc quyền) để tri ân và khai thác thêm giá trị vòng đời thông qua cross-sell/up-sell.
7.3. Tại sao lại cần K-Means khi đã có XGBoost đoán Churn?
-
XGBoost (Học có giám sát) chỉ trả lời cho bạn câu hỏi: "KHÁCH HÀNG NÀO có nguy cơ rời bỏ (Xác suất 90%)?"
-
K-Means (Học không giám sát) trả lời câu hỏi: "Nhóm người rời bỏ này CÓ ĐẶC ĐIỂM GÌ CHUNG?"
Hành động: Giả sử XGBoost xuất ra danh sách 500 khách hàng sắp rời bỏ. Nếu bộ phận Marketing gửi chung 1 email "Đừng đi, tặng bạn voucher 10%" cho cả 500 người, hiệu quả sẽ rất thấp. Thay vào đó, nhờ có K-Means dán nhãn, Marketing sẽ chia 500 người này ra xử lý.
8. Risk Tier Assignment — Chuyển hóa Dự đoán thành Hành động (Actionable Insights)
Sau khi huấn luyện mô hình XGBoost, thay vì chỉ dùng nhãn phân loại nhị phân (Churn / Non-churn), chúng ta sử dụng trực tiếp xác suất dự đoán (predicted probability) để phân nhóm khách hàng và ánh xạ ra các hành động cụ thể cho bộ phận vận hành.
8.1. Phân loại Rủi ro (Risk Tiering)
Dựa trên xác suất dự đoán, khách hàng được chia thành 3 nhóm chiến lược nhằm tối ưu chi phí:
- High Risk (> 0.7)
Mức độ: Rủi ro cao
Hành động: Gọi ngay + Giảm 20% để can thiệp và giữ chân lập tức.
- Medium Risk (0.4 - 0.69)
Mức độ: Rủi ro tiềm ẩn
Hành động: Gửi Email ưu đãi để tiếp cận tự động với chi phí thấp.
- Low Risk (< 0.4)
Mức độ: Vùng an toàn
Hành động: Chỉ theo dõi, tránh can thiệp thừa gây lãng phí nguồn lực.
8.2. Hiệu quả phân nhóm (Risk Tier Distribution)
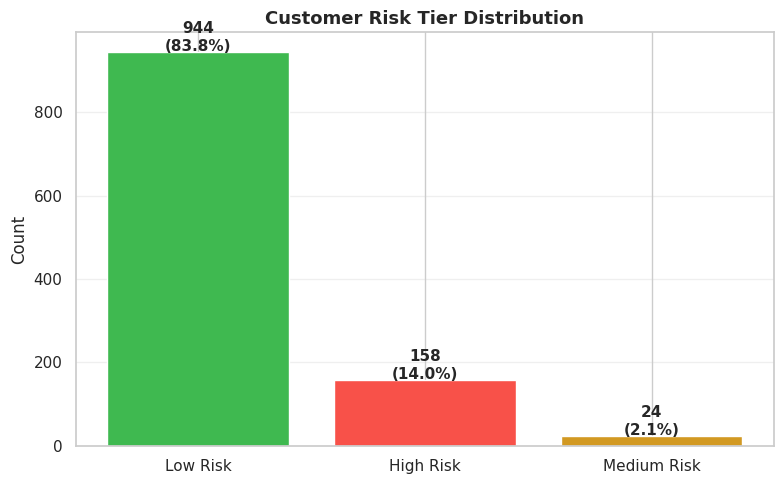
Nguồn: Kết quả chạy chương trình
Biểu đồ phân phối cho thấy khả năng nhận diện rủi ro của mô hình bám rất sát thực tế:
- Low Risk (83.8% | 944 khách hàng)
Tỷ lệ rời bỏ thực tế chỉ 2.3%. Mô hình lọc nhiễu tốt, giúp doanh nghiệp không lãng phí tài nguyên chăm sóc sai đối tượng.
- High Risk (14.0% | 158 khách hàng)
Tỷ lệ rời bỏ thực tế lên đến 96.2%. Hệ thống khoanh vùng chính xác tệp khách hàng trọng điểm để dồn ngân sách can thiệp khẩn cấp.
- Medium Risk (2.1% | 24 khách hàng)
Tỷ lệ rời bỏ thực tế 66.7%. Đây là nhóm rủi ro trung gian, phù hợp áp dụng các kịch bản giữ chân tự động (email/app push) với chi phí thấp.
8.3. Giá trị Vận hành (Business Value)
Kết quả phân loại mang lại hai lợi ích lớn trong vận hành thực tế:
- Tối ưu ngân sách:
Thay vì tung mã giảm giá 20% đại trà gây lãng phí, doanh nghiệp có thể tập trung toàn bộ nguồn lực để chăm sóc chính xác 163 khách hàng thuộc nhóm High Risk.
- Tự động hóa:
Tập dữ liệu đầu ra đã sẵn sàng tích hợp lên vào ứng dụng, giúp cấp quản lý theo dõi chỉ số hàng ngày và tự động hóa các chiến dịch giữ chân khách hàng (retention campaign).
9. Định lượng rủi ro với mô hình Cox Proportional Hazards (Cox PH)
Nếu XGBoost đã trả lời được câu hỏi "Ai sẽ rời đi?", thì bài toán tiếp theo của bộ phận vận hành là: "Khi nào họ đi?". Việc xác định đúng thời điểm giúp phân bổ mức độ ưu tiên can thiệp hợp lý (ví dụ: khách hàng sắp rời đi trong 1 tuần tới cần xử lý gấp hơn khách hàng sau 6 tháng). Để giải quyết bài toán thời gian (Timing), chúng ta áp dụng Phân tích Sống còn (Survival Analysis). Thay vì một mức xác suất tĩnh, phương pháp này cung cấp:
Đường cong sống còn S(t): Thể hiện tỷ lệ xác suất khách hàng tiếp tục sử dụng dịch vụ qua từng tháng.
Xử lý dữ liệu bị ẩn (Censored data): Tích hợp hiệu quả thông tin của những khách hàng hiện vẫn đang dùng dịch vụ mà hệ thống chưa rõ trạng thái tương lai.
9.1. Trực quan hóa đường cong sống còn (Kaplan-Meier)
Thuật toán Kaplan-Meier theo dõi tỷ lệ khách hàng tiếp tục sử dụng dịch vụ (Survival Probability) qua từng tháng (Tenure). Đường cong càng dốc, tốc độ rời bỏ càng nhanh.
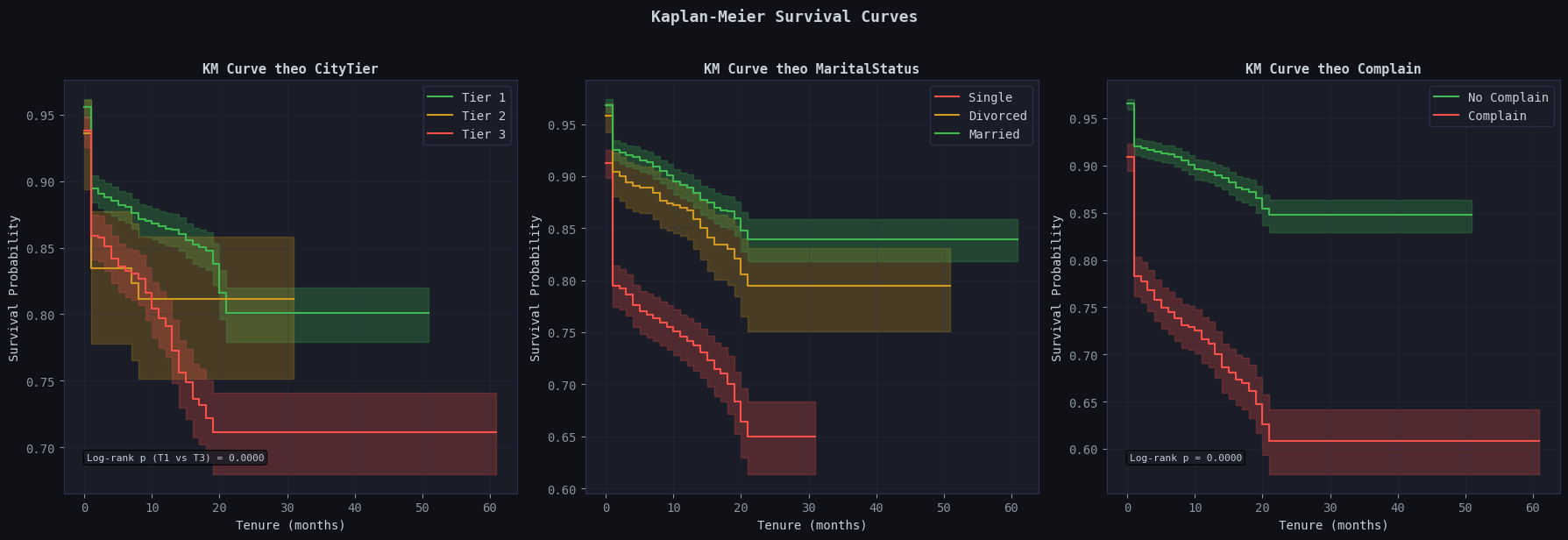
Nguồn: Kết quả chạy chương trình
Phân tích 3 biến số chính cho thấy:
- Hạng thành phố (CityTier): Nhóm Tier 1 (thành phố lớn) có tỷ lệ ở lại ổn định nhất, trong khi Tier 3 giảm nhanh rõ rệt (p-value = 0.0000).
Insight: Cần kiểm tra rà soát lại chất lượng giao hàng (logistics) và dịch vụ hỗ trợ tại các khu vực tỉnh lẻ.
- Tình trạng hôn nhân (MaritalStatus): Khách hàng Độc thân (Single) rời bỏ nhanh nhất, trái ngược với sự ổn định của nhóm Đã kết hôn (Married).
Insight: Người có gia đình ưu tiên tính ổn định, trong khi người độc thân nhạy cảm hơn với các chương trình khuyến mãi từ đối thủ cạnh tranh.
- Lịch sử khiếu nại (Complain): Đường cong của nhóm có khiếu nại sụt giảm mạnh ngay từ những tháng đầu.
Insight: Khách hàng có độ dung sai thấp với trải nghiệm tệ. Việc xử lý khiếu nại không dứt điểm sẽ dẫn đến rời bỏ lập tức.
Giải thích chỉ số Median Survival Time = inf (Vô cực) Thời gian sống sót trung vị (Median Survival Time) là mốc thời gian ghi nhận 50% khách hàng rời bỏ dịch vụ. Kết quả trả về inf vì tại tháng thứ 60 (điểm cuối của dữ liệu), ngay cả nhóm rời bỏ cao nhất (Complain) vẫn duy trì tỷ lệ ở lại trên 60%.
Do tỷ lệ sống sót chưa từng chạm ngưỡng 50% (0.5), thuật toán không thể tìm ra điểm cắt. Điều này chứng tỏ doanh nghiệp đang duy trì tỷ lệ giữ chân (Retention Rate) tổng thể rất tốt trong suốt 5 năm qua.
9.2. Định lượng rủi ro với mô hình Cox Proportional Hazards (Cox PH)
Mô hình Cox PH đo lường mức độ tác động của từng đặc trưng lên thời gian gắn bó của khách hàng thông qua chỉ số Tỷ suất rủi ro (Hazard Ratio - HR). Mô hình đạt độ chính xác cao với chỉ số Concordance = 0.7672.
.png)
Nguồn: Kết quả chạy chương trình
Cách đọc kết quả:
-
HR > 1: Tăng rủi ro rời bỏ.
-
HR < 1: Giảm rủi ro rời bỏ.
(Chỉ phân tích các biến có ý nghĩa thống kê với mức p-value < 0.05)
Kết quả bóc tách các yếu tố chính:
-Khiếu nại (Complain | HR = 2.173): Khách hàng từng khiếu nại có nguy cơ rời bỏ tăng vọt 117%.
$\rightarrow$ CSKH phải giải quyết khiếu nại triệt để, vì chi phí này rẻ hơn rất nhiều so với chi phí tìm khách mới.
- Số thiết bị (NumberOfDeviceRegistered | HR = 1.234): Thêm 1 thiết bị đăng nhập, rủi ro tăng 23%.
$\rightarrow$ Đội Product/Tech cần rà soát lại luồng UX đa thiết bị (lỗi đồng bộ, bắt đăng nhập lại nhiều lần).
- Điểm hài lòng (SatisfactionScore | HR = 1.124): Điểm tăng 1, rủi ro tăng 12%. Nghịch lý này thường do khách chỉ mua một lần (one-off purchase) hoặc đánh giá ảo 5 sao để nhận ưu đãi.
$\rightarrow$ Biến này đang bị nhiễu và không phản ánh đúng lòng trung thành.
- Hoàn tiền (CashbackAmount | HR = 0.994): Hoàn tiền tăng giúp giảm 1% rủi ro rời bỏ.
$\rightarrow$ Chương trình Loyalty (tích điểm/ví thưởng) đang phát huy tốt vai trò "mỏ neo" giữ chân khách hàng.
- Các biến vô nghĩa thống kê (p > 0.05): Số đơn hàng (OrderCount), Mã giảm giá (CouponUsed) và Thời gian dùng app (HourSpendOnApp).
$\rightarrow$ Số lượng tương tác không quyết định thời gian ở lại của khách hàng; chất lượng trải nghiệm (không lỗi, không khiếu nại) mới là yếu tố quyết định.
9.3. Dự báo cá nhân hóa (Individual Survival Curves)
.png)
Nguồn: Kết quả chạy chương trình
Mô hình Cox PH vẽ ra quỹ đạo dự báo rời bỏ riêng cho từng khách hàng, giúp cá nhân hóa kịch bản chăm sóc:
-
C3 (Rủi ro cao): Mới dùng 1 tháng, có khiếu nại. Xác suất ở lại rớt dưới 70% trước tháng thứ 6. $\rightarrow$ Cần xử lý khẩn cấp trên hệ thống CRM.
-
C5 (Ổn định): Đã dùng 15 tháng, không khiếu nại. Xác suất ở lại duy trì >90%. $\rightarrow$ Trung thành tự nhiên nhờ thâm niên và trải nghiệm không lỗi.
Tác động của Khiếu nại (C1 vs C2): C2 chấm 5 sao nhưng có khiếu nại (xác suất rớt còn 70-80%). C1 chấm 1 sao nhưng không khiếu nại (xác suất >90%).
$\rightarrow$ Việc mở khiếu nại đẩy nhanh tốc độ rời bỏ hơn rất nhiều so với việc chỉ chấm điểm thấp.
Ứng dụng thực tế: Thiết lập điểm chạm tự động
Xác suất ở lại trung bình của toàn hệ thống tại mốc 6 tháng là 85.7%. Dựa vào mức này, thay vì gửi email ưu đãi đại trà tốn kém, hệ thống chỉ tự động kích hoạt (trigger) cuộc gọi chăm sóc cho những khách hàng có xác suất rớt xuống dưới 70% trước mốc 6 tháng. Cách tiếp cận này giúp tối ưu hóa triệt để chi phí vận hành.
9.4. Tích hợp Classification (XGBoost) và Survival Analysis (Cox PH)
Thay vì sử dụng độc lập, việc kết hợp cả hai mô hình tạo ra một chiến lược giữ chân khách hàng toàn diện, khép kín từ dự báo đến hành động.
1. Phân định vai trò của hai mô hình:
-
XGBoost (Classification): Giải quyết bài toán "Ai sẽ rời đi?" (Who). Mô hình xuất ra xác suất rời bỏ (0 đến 1) và nhận diện nhóm rủi ro cao. Điểm yếu là không đo lường được yếu tố thời gian và không xử lý được dữ liệu bị ẩn (Censored data).
-
Cox PH (Survival Analysis): Giải quyết bài toán "Khi nào họ rời đi?" (When). Lấp đầy khoảng trống của XGBoost bằng cách xuất ra đường cong sống còn $S(t)$, dự báo chính xác thời điểm rớt hạng của khách hàng.
| Tiêu chí | XGBoost (Classification) | Cox PH (Survival Analysis) |
|---|---|---|
| Mục tiêu | Dự báo Ai (Who) | Dự báo Khi nào (When) |
| Đầu ra | Xác suất 0 → 1 | Đường cong sống còn $S(t)$ |
| Ứng dụng CRM | Khoanh vùng đối tượng can thiệp | Lên lịch thời điểm can thiệp |
2. Ứng dụng thực tiễn (Proactive Intervention):
Khi đặt cạnh nhau, output của hai hệ thống tạo ra chỉ thị chăm sóc khách hàng (CS) được cá nhân hóa tuyệt đối.
Ví dụ giao diện CRM: "Khách hàng A có xác suất rời bỏ 78% (XGBoost) và dự kiến sẽ đóng tài khoản trong 2.3 tháng tới (Cox PH)."
$\rightarrow$ Kết luận: Hệ thống kép giúp doanh nghiệp chấm dứt việc chạy chiến dịch Marketing đại trà lãng phí; chuyển hẳn sang trạng thái can thiệp chủ động: Tìm ra đúng người (XGBoost) và tiếp cận vào đúng thời điểm (Cox PH).
10. Đề xuất chiến lược & Kết luận (Recommendations & Conclusions)
Mục tiêu cuối cùng của dự án không phải là mô hình, mà là câu trả lời cho ban lãnh đạo: "Chúng ta phải làm gì tiếp theo?". Hệ thống ChurnAlert cô đọng kết quả thành một bản kế hoạch hành động và báo cáo tự động.
10.1. Đánh giá hiệu suất mô hình (Pipeline Summary)
Mô hình XGBoost (đã qua tối ưu Optuna và Calibrated) kết hợp 22 đặc trưng (bao gồm RFM) ghi nhận các chỉ số xuất sắc:
ROC AUC = 98.88% và F1-Score = 92.23%: Minh chứng cho khả năng dự báo cực kỳ chính xác, cân bằng tốt giữa việc không bỏ lọt khách hàng rủi ro (Recall) và không nhận diện nhầm (Precision).
10.2. Chiến lược giữ chân (Retention Strategy)
Từ phân tích SHAP, các yếu tố quyết định như Thâm niên, Khiếu nại và Hoàn tiền được ánh xạ thành Ma trận hành động (Action Matrix):
-
High Risk (>70%): Gọi điện trực tiếp + Voucher giảm 20%. $\rightarrow$ Logic: Chi phí tung khuyến mãi rẻ hơn nhiều so với chi phí thu hút khách hàng mới (CAC).
-
Medium Risk (40-70%): Gửi Email ưu đãi cá nhân hóa. $\rightarrow$ Logic: Đánh vào tâm lý thích hoàn tiền để giữ chân với chi phí vận hành gần bằng 0.
-
Low Risk (<40%): Đưa vào chương trình Loyalty. $\rightarrow$ Logic: Không can thiệp thô bạo, tập trung nuôi dưỡng để tăng giá trị vòng đời khách hàng (LTV).
10.3. Hạn chế và Hướng phát triển
-
Hạn chế: Dataset hiện tại là dữ liệu tĩnh và gán nhãn nhị phân, chưa đo lường được hiện tượng "rời bỏ từ từ" (gradual disengagement).
-
Giải pháp: Cần tích hợp thêm dữ liệu chuỗi thời gian (time-series) như: Lịch sử click chuột (clickstream), Tỷ lệ bỏ giỏ hàng, hoặc Thời gian xử lý khiếu nại để mô hình nhạy bén hơn.
Tổng kết:
Dự án đã khép kín toàn bộ quy trình: Xử lý dữ liệu thô $\rightarrow$ Machine Learning $\rightarrow$ Survival Analysis $\rightarrow$ Tạo demo thành phẩm. Hệ sinh thái ChurnAlert chính là minh chứng rõ nét cho việc ứng dụng Khoa học dữ liệu để trực tiếp tối ưu hóa lợi nhuận và vận hành doanh nghiệp.
Chưa có bình luận nào. Hãy là người đầu tiên!