
1. Giới thiệu
Trong kỉ nguyên số hóa, sự bùng nổ của mobile banking, thương mại điện tử và các hình thức thanh toán trực tuyến đã mang lại sự tiện lợi chưa từng có cho người dùng. Tuy nhiên, mặt trái của sự phát triển này là sự gia tăng chóng mặt của các hình thức gian lận tài chính với thủ đoạn ngày càng tinh vi và phức tạp. Từ những vụ đánh cắp thông tin thẻ tín dụng, tấn công giả mạo (phishing), cho đến chiếm đoạt quyền kiểm soát tài khoản (account takeover), tội phạm mạng đang đặt ra thách thức nghiêm trọng cho toàn bộ hệ thống tài chính toàn cầu.
Theo dữ liệu mới nhất được Federal Trade Commission (FTC) công bố vào tháng 3/2025, người tiêu dùng đã chịu mức thiệt hại kỉ lục lên tới 12,5 tỷ USD trong năm 2024, tăng trưởng nóng 25% chỉ sau một năm. Đáng báo động hơn, tỉ lệ các vụ lừa đảo dẫn đến mất mát tài sản thực tế đã tăng từ 27% lên 38%, cho thấy tội phạm mạng không chỉ gia tăng về quy mô mà còn tối ưu hóa hiệu quả tấn công thông qua các kĩ thuật như phishing hay chiếm quyền tài khoản. Đáng ngại hơn, các cuộc tấn công này thường diễn ra trong tích tắc – tính bằng mili giây – khiến các phương thức kiểm tra thủ công truyền thống hoàn toàn bất lực trong việc ngăn chặn.
Trước bối cảnh đó, việc ứng dụng Học máy (Machine Learning) đã trở thành "vũ khí" then chốt, giúp các ngân hàng nhận diện và ngăn chặn hành vi xâm nhập trái phép ngay từ khi giao dịch chưa kịp hoàn tất, bảo vệ an toàn tối đa cho tài sản của khách hàng.

2. Fraud Detection trong ngân hàng là gì?
Trong lĩnh vực ngân hàng, Fraud Detection (phát hiện gian lận) được hiểu là một hệ thống các quy trình và công nghệ nhằm nhận diện, phân tích và ngăn chặn các giao dịch bất thường hoặc có dấu hiệu nghi vấn. Mục tiêu cốt lõi của quá trình này là bảo vệ tài sản của khách hàng và hạn chế tối đa tổn thất tài chính cũng như uy tín cho ngân hàng.
Hiện nay, các hình thức gian lận ngày càng tinh vi, bao gồm các loại hình phổ biến như:
- Credit card fraud: Sử dụng trái phép thông tin thẻ để thanh toán hoặc rút tiền.
- Identity theft: Đánh cắp thông tin cá nhân (CCCD, số điện thoại) để mở tài khoản hoặc vay vốn bất chính.
- Account takeover (ATO): Kẻ gian chiếm quyền điều khiển tài khoản ngân hàng trực tuyến của khách hàng thông qua mã độc hoặc lừa đảo.
- Money laundering: Các giao dịch phức tạp nhằm hợp thức hóa nguồn tiền bất hợp pháp.
- Phishing & Social Engineering: Lừa đảo qua tin nhắn, cuộc gọi giả danh nhân viên ngân hàng để dụ người dùng cung cấp mã OTP hoặc mật khẩu.
- APP Fraud (Authorised Push Payment): Kẻ gian lừa nạn nhân tự nguyện chuyển tiền vào một tài khoản giả mạo (thường thấy trong các kịch bản lừa đảo trúng thưởng hoặc đầu tư tài chính).
3. Vì sao các phương pháp Fraud Detection truyền thống không còn đủ hiệu quả?
Trước khi machine learning được áp dụng rộng rãi, phần lớn ngân hàng sử dụng các hệ thống dựa trên luật (rule-based systems) để phát hiện giao dịch đáng ngờ. Các hệ thống này hoạt động bằng cách áp dụng những quy tắc được thiết lập sẵn bởi các chuyên gia phân tích.
Nếu một giao dịch vi phạm một trong các quy tắc đó, hệ thống sẽ gắn cờ giao dịch để kiểm tra thêm.
Một số quy tắc phổ biến trong các hệ thống truyền thống gồm:
- Giao dịch vượt quá một ngưỡng nhất định (ví dụ: trên 5.000 USD)
- Thanh toán được thực hiện từ quốc gia khác với vị trí thông thường của chủ thẻ
- Nhiều giao dịch liên tiếp xảy ra trong khoảng thời gian rất ngắn
Thoạt nhìn, cách tiếp cận này khá hợp lý. Tuy nhiên, trong thực tế nó gặp khó khăn khi phải đối phó với những chiến thuật gian lận ngày càng thay đổi nhanh chóng.
Hạn chế lớn nhất là mô hình gian lận luôn biến đổi. Những kẻ gian lận thường nhanh chóng điều chỉnh chiến thuật để vượt qua các quy tắc hiện có. Ví dụ, nếu hệ thống đánh dấu các giao dịch trên 5.000 USD là đáng ngờ, kẻ gian có thể chia nhỏ giao dịch thành nhiều khoản nhỏ hơn để tránh bị phát hiện. Vì các quy tắc này phải được thiết kế và cập nhật thủ công bởi chuyên gia, hệ thống thường chỉ phản ứng sau khi các hình thức gian lận mới đã xuất hiện.
Một vấn đề quan trọng khác là tỷ lệ false positives cao, tức là những giao dịch hợp lệ nhưng bị hệ thống nhầm là gian lận. Điều này gây bất tiện cho cả ngân hàng lẫn khách hàng. Chẳng hạn, khi một khách hàng đi du lịch nước ngoài và thực hiện thanh toán tại một quốc gia mới, hệ thống có thể hiểu nhầm đó là hoạt động bất thường và tạm khóa thẻ. Dù mục tiêu là bảo vệ tài khoản, những tình huống như vậy có thể ảnh hưởng đáng kể đến trải nghiệm người dùng.
Các nghiên cứu trong lĩnh vực phát hiện gian lận tài chính cũng chỉ ra rằng các hệ thống dựa trên luật cố định thường gặp khó khăn khi xử lý khối lượng dữ liệu giao dịch lớn và các mô hình gian lận phức tạp, nơi hành vi gian lận có thể rất tinh vi và khó mô tả bằng các ngưỡng cố định.
Chính vì những hạn chế này, nhiều tổ chức tài chính đang chuyển sang sử dụng Học máy, cho phép hệ thống học trực tiếp từ dữ liệu giao dịch, phát hiện các mẫu hành vi phức tạp và thích nghi tốt hơn với những chiến thuật gian lận mới.
Để chỉ ra sự khác biệt giữa rule-based systems và machine-learning thì bạn hãy nhìn vào bảng sau:
| Khía cạnh | Hệ thống phát hiện gian lận dựa trên luật (Rule-based) | Hệ thống phát hiện gian lận sử dụng Machine Learning |
|---|---|---|
| Ra quyết định | Dựa trên logic cố định “Nếu X thì Y”, quyết định rõ ràng nhưng thường cứng nhắc | Phân tích nhiều yếu tố để đưa ra quyết định linh hoạt dựa trên dữ liệu theo thời gian thực |
| Khả năng thích ứng | Các quy tắc phải được cập nhật thủ công khi xuất hiện chiến thuật gian lận mới | Liên tục học từ dữ liệu và tự điều chỉnh khi mô hình gian lận thay đổi |
| Khả năng giải thích | Dễ giải thích cho các bên liên quan vì quyết định thường gắn với một quy tắc cụ thể | Không phải lúc nào cũng trực quan, nhưng nhiều hệ thống có công cụ giúp giải thích quyết định của mô hình |
| Độ chính xác và hiệu năng | Hiệu quả với các mẫu gian lận đã biết nhưng dễ tạo ra nhiều cảnh báo nhầm (false positives) | Độ chính xác cao hơn, giảm số giao dịch hợp lệ bị từ chối và giảm bỏ sót gian lận |
| Khả năng mở rộng | Trở nên khó quản lý khi số lượng giao dịch và quy tắc tăng lên | Có thể mở rộng tốt và xử lý khối lượng dữ liệu lớn mà không cần tăng độ phức tạp của quy tắc |
| Ảnh hưởng đến trải nghiệm khách hàng | Các quy tắc quá chặt có thể khiến khách hàng hợp lệ bị chặn giao dịch, gây khó chịu | Cân bằng giữa bảo mật và trải nghiệm giao dịch mượt mà hơn cho khách hàng đáng tin cậy |
| Mức độ sẵn sàng trước gian lận | Mang tính phản ứng: thường chỉ xử lý sau khi mối đe dọa đã xuất hiện | Mang tính chủ động: có khả năng thích nghi với các chiến thuật gian lận mới |
Bảng 3.1. So sánh giữa hệ thống phát hiện gian lận truyền thống dựa trên Rule-based và hệ thống sử dụng Machine Learning
;
nguồn: Channing Lovett
4. Các thuật toán học máy và pipeline trong Fraud Detection
4.1. Các thuật toán học máy trong Fraud Detection
4.1.1. Supervised Learning
Supervised Learning (Học có giám sát) là một phương pháp trong Machine Learning, trong đó mô hình được huấn luyện bằng cách sử dụng các tập dữ liệu đã được gán nhãn. Thuật toán sẽ học cách nhận diện các mẫu và mối quan hệ giữa dữ liệu đầu vào và đầu ra, từ đó có thể dự đoán chính xác kết quả khi gặp dữ liệu mới trong thực tế.
Trong lĩnh vực ngân hàng, ta có thể xem dữ liệu input là dữ liệu về giao dịch của khách hàng (ngày, giờ, địa điểm giao dịch), dữ liệu output được gãn nhãn và chia thành hai tập chính: giao dịch bình thường và giao dịch bất thường. Sau khi huấn luyện, mô hình có thể đưa ra dự đoán đâu là giao dịch có hành vi gian lận và giao dịch bình thường.
Một số thuật toán phổ biến của supervised learning:
Random Forest. Là một thuật toán học máy thuộc nhóm học có giám sát (supervised learning) và được sử dụng phổ biến trong các bài toán phân loại (classification) và hồi quy (regression). Random Forest bao gồm nhiều cây quyết định (Decision Trees). Mỗi cây là một mô hình dự đoán độc lập và đưa ra một dự đoán. Đối với bài toán phân loại, Random Forest sẽ lấy kết quả dự đoán của từng cây và chọn kết quả nào xuất hiện nhiều nhất (majority vote). Đối với bài toán hồi quy, kết quả cuối cùng là giá trị trung bình của các dự đoán từ tất cả các cây.
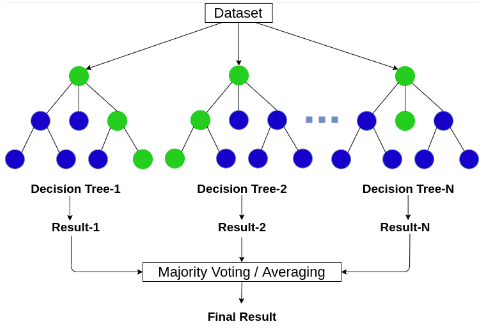
Hình 4.1. Thuật toán Random Forest; nguồn: AICandy
Gradient Boosting. Là một kỹ thuật học máy kết hợp nhiều mô hình dự đoán yếu (weak prediction models) thành một hệ thống tổng hợp. Các mô hình này thường là cây quyết định (decision trees), được huấn luyện tuần tự nhằm giảm lỗi xuống mức tối thiểu và cải thiện độ chính xác. Nhờ việc kết hợp nhiều cây hồi quy (decision tree regressors) hoặc cây phân loại (decision tree classifiers), Gradient Boosting có thể nắm bắt hiệu quả các mối quan hệ phức tạp giữa các đặc trưng (features).
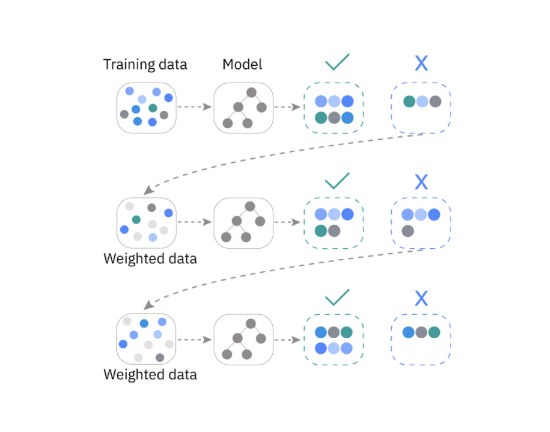
Hình 4.2. Thuật toán Gradient Boosting; nguồn: VinBigData
Ứng dụng: Phát hiện hành vi giao dịch bất thường
Lĩnh vực ngân hàng lưu trữ một bộ dữ liệu lớn về thông số giao dịch, thông qua tài nguyên dồi dào đó, ta có thể dễ dàng xây dựng mô hình dự đoán giao dịch bất thường. Nhãn dán ở lĩnh vực này đồng thời mang tính chất nhị phân (bình thường và bất thường), phù hợp với các mô hình phân loại. Ngoài ra, với bản chất là bộ dữ liệu nhiều thuộc tính, các thuật toán như Random Forests hay Gradient Boost đều có khả năng hoạt động hiệu quả.
4.1.2. Unsupervised Learning
Khác với Supervised Learning, Unsupervised Learning (Học không giám sát) hoạt động trên dữ liệu không có nhãn, mô hình tự tìm kiếm các mẫu và cấu trúc trong dữ liệu. Thay vì dựa vào dữ liệu được gán nhãn trước, thuật toán này phân tích và nhóm các điểm dữ liệu dựa trên sự tương đồng và khác biệt dựa trên tệp dữ liệu đầu vào. Một số những thuật toán trong Unsupervised Learning có thể kể đến như:
Clustering. Thuật toán phân cụm có tác dụng nhóm các dữ liệu chưa được gán nhãn thành các cụm có cùng đặc điểm, đặc trưng. Các dữ liệu ở các cụm khác nhau sẽ có sự khác nhau rõ rệt. Thuật toán này có vai trò phát hiện các cấu trúc tiềm ẩn trong dữ liệu.
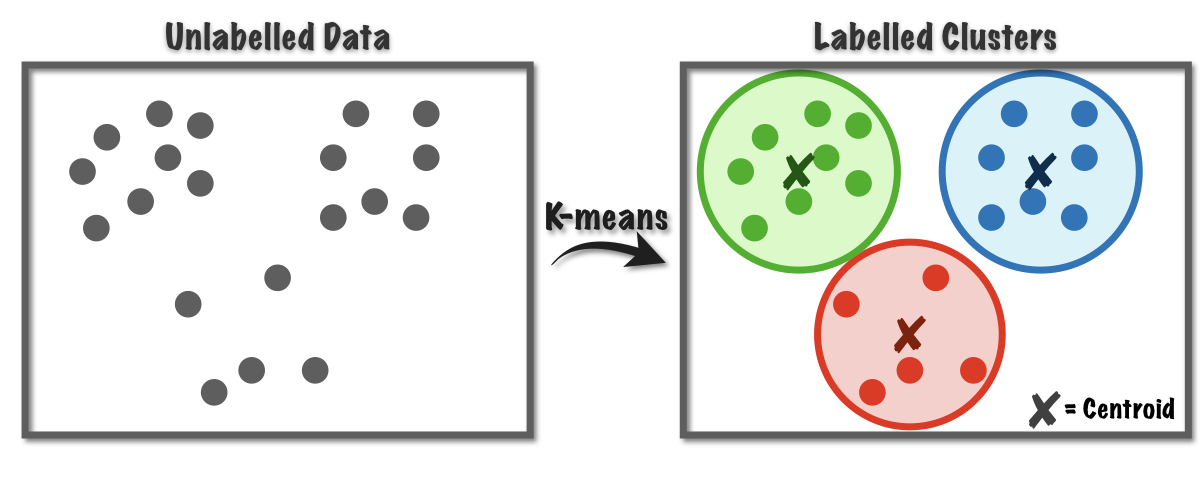
Hình 4.3. Thuật toán Clustering; nguồn: Medium
Isolation forest. Thuật toán hoạt động dựa trên Decision Trees. Với isolation forest, các dữ liệu bất thường (anomalies) hay các điểm ngoại vi (outliers) sẽ bị cô lập dần qua các nhánh cây. Những điểm dữ liệu mà cần nhiều điều kiện hơn để phân định (rẽ nhánh nhiều hơn) chứng tỏ có xác suất rất nhỏ những điểm dữ liệu đó là nhiễu. Ngược lại, những điểm dữ liệu cần ít điều kiện để xác định (rẽ nhánh ít) thì có khả năng đó là những dữ liệu bất thường, bởi vì ta có thể nhận biết chúng 1 cách dễ dàng giữa rất nhiều điểm dữ liệu khác.
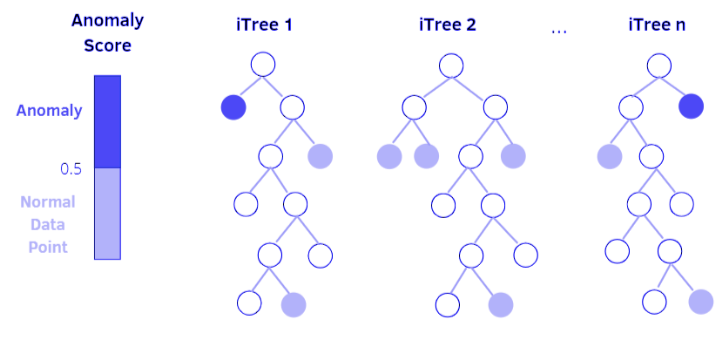
Hình 4.4. Thuật toán Isolation Forest; nguồn: PyImageSearch
Ứng dụng: Phát hiện hành vi giao dịch bất thường
Thực tế cho thấy các dữ liệu về điểm bất thường trong giao dịch rất khó để gán nhãn bởi tính ngẫu nhiên và thay đổi liên tục. Cùng với lượng dữ liệu lớn trong cơ sở giao dịch, việc gán nhãn đòi hỏi nhiều thời gian và có thể tiềm ẩn việc gán sai nhãn cho dữ liệu. Do đó, thuật toán phân cụm có thể đạt hiệu quả tốt hơn trong việc phân nhóm và phát hiện các dữ liệu bất thường trong bộ dữ liệu giao dịch.
4.2. Fraud Detection Pipeline
Quy trình cơ bản để build một mô hình nhận diện giao dịch bất thường bao gồm:
Bước 1: Thu thập dữ liệu. Bước này thu thập dữ liệu banking từ nhiều nguồn khác nhau, nguồn dữ liêu có thể lấy từ:
- Lịch sử giao dịch: thời gian, địa điểm, số tiền giao dịch
- Thông tin người dùng: độ tuổi
- Dữ liệu thiết bị: địa chỉ IP khi thực hiện giao dịch
Bước 2: Xử lí dữ liệu. Bộ dữ liệu giao dịch thường rất lớn và nhiều thông tin, do đó ta cần xử lí dữ liệu trước khi tiến hành bước xây dựng mô hình:
- Sàng lọc dữ liệu đầu vào
- Xử lí các thông tin bị thiếu
- Chuẩn hóa dữ liệu
Bước 3: Feature engineering. Bên cạnh bước xử lí dữ liệu, feature engineering (kỹ thuật tạo đặc trưng) cũng đóng vai trò quan trọng trong việc đào tạo một mô hình hiệu quả. Tại bước này ta sẽ thiết lập các đặc trưng từ dữ liệu, quyết định những đặc trưng nào nổi bật để đưa vào mô hình huấn luyện. Việc chuẩn bị các đặc trưng này sẽ ảnh hưởng trực tiếp tới hiệu suất của mô hình. Những đặc trưng có thể chuẩn bị:
- Số lần giao dịch trong 1 giờ
- Khoảng cách giữa hai địa điểm giao dịch
- Giá trị trung bình giao dịch
Bước 4: Huấn luyện mô hình. Tại bước này, ta lựa chọn mô hình phù hợp với nhu cầu để huấn luyện dữ liệu. Trong bài toán nhận diện giao dịch bất thường, nếu các dữ liệu giao dịch được gán nhãn và phân biệt đâu là bình thường, đâu là đáng ngờ, ta có thể sử dụng các thuật toán Supervised Learning. Tuy nhiên, nếu việc gán nhãn không khả thi hoặc khó phân định, các thuật toán Unsupervised Learning có thể phù hợp hơn. Một số thuật toán phổ biển phù hợp với bài toán này bao gồm:
- Logistic Regression
- Random Forest
- Gradient Boosting
- Neural Networks
Bước 5: Đưa vào thực tế. Sau quá trình huấn luyện, mô hình sẽ được triển khai để chạy trên thời gian thực, khi có dữ liệu mới:
- Dữ liệu được đưa vào mô hình
- Mô hình tính toán fraud probability – xác suất dữ liệu đầu vào là bình thường hay đáng ngờ
- Nếu giá trị output vượt ngưỡng giá trị đã thiết lập, hệ thống có thể đưa ra cảnh báo giao dịch đó là bất thường hoặc giao dịch sẽ bị chặn
5. Thực tiễn triển khai trong ngành Ngân hàng và Tài chính
Việc áp dụng Học máy vào quy trình giám sát giao dịch đã chuyển dịch từ các thử nghiệm đơn lẻ thành một thành phần cốt lõi trong cơ sở hạ tầng an toàn tài chính.
- Hệ thống xác thực nâng cao của Visa: Đây là một trong những mạng lưới ứng dụng AI lớn nhất thế giới. Mỗi giao dịch qua Visa được đánh giá dựa trên hơn 500 thuộc tính khác nhau chỉ trong vòng 1 mili giây. Hệ thống phân tích hồ sơ rủi ro của đơn vị chấp nhận thẻ, lịch sử hành vi của chủ thẻ và các dấu hiệu bất thường về mặt địa lý. Theo báo cáo từ Visa (2023), công cụ này giúp ngăn chặn thất thoát tài chính ước tính khoảng 27 tỷ USD mỗi năm.
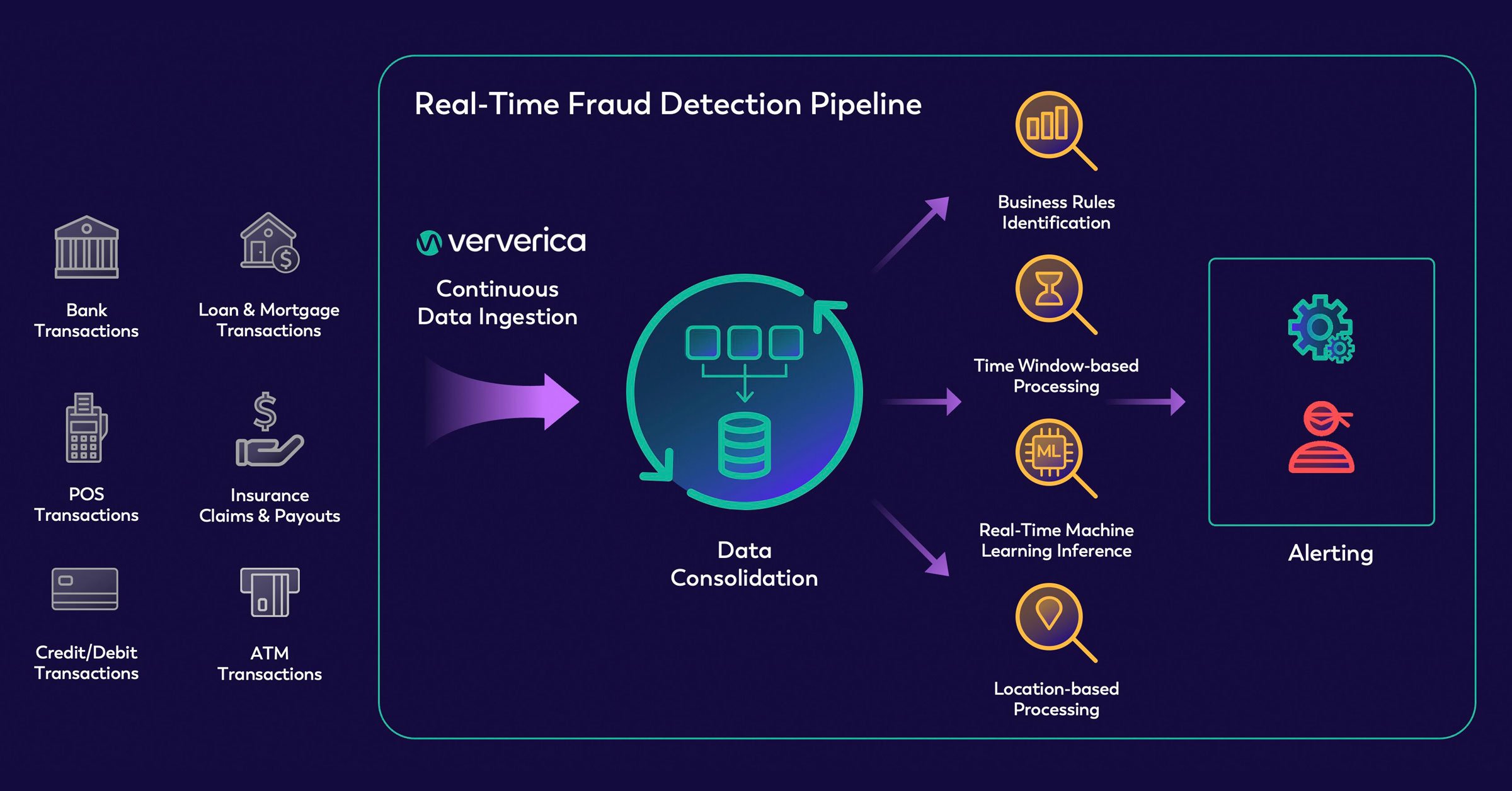
Hình 5.1. Quy trình xử lý giao dịch và phát hiện gian lận trong thời gian thực; nguồn: ververica
-
Mô hình phân tích đa lớp của PayPal: PayPal sử dụng phương pháp tiếp cận kết hợp giữa các thuật toán Học sâu và quy trình kiểm soát của con người. Bằng cách nhận diện các mẫu hành vi vi mô trong khối lượng giao dịch khổng lồ, PayPal duy trì tỷ lệ gian lận ở mức 0,3% tổng giá trị giao dịch, thấp hơn đáng kể so với mức trung bình của ngành (PayPal, 2021).
-
Ứng dụng tại thị trường Việt Nam: Trong bối cảnh thanh toán không dùng tiền mặt bùng nổ, các tổ chức tài chính đang tích hợp Sinh trắc học hành vi. Hệ thống ML không chỉ xác thực qua mã OTP mà còn phân tích cách người dùng tương tác với thiết bị (tốc độ gõ phím, thói quen cầm điện thoại, vị trí truy cập thường xuyên) để phát hiện sớm các hành vi chiếm đoạt tài khoản.
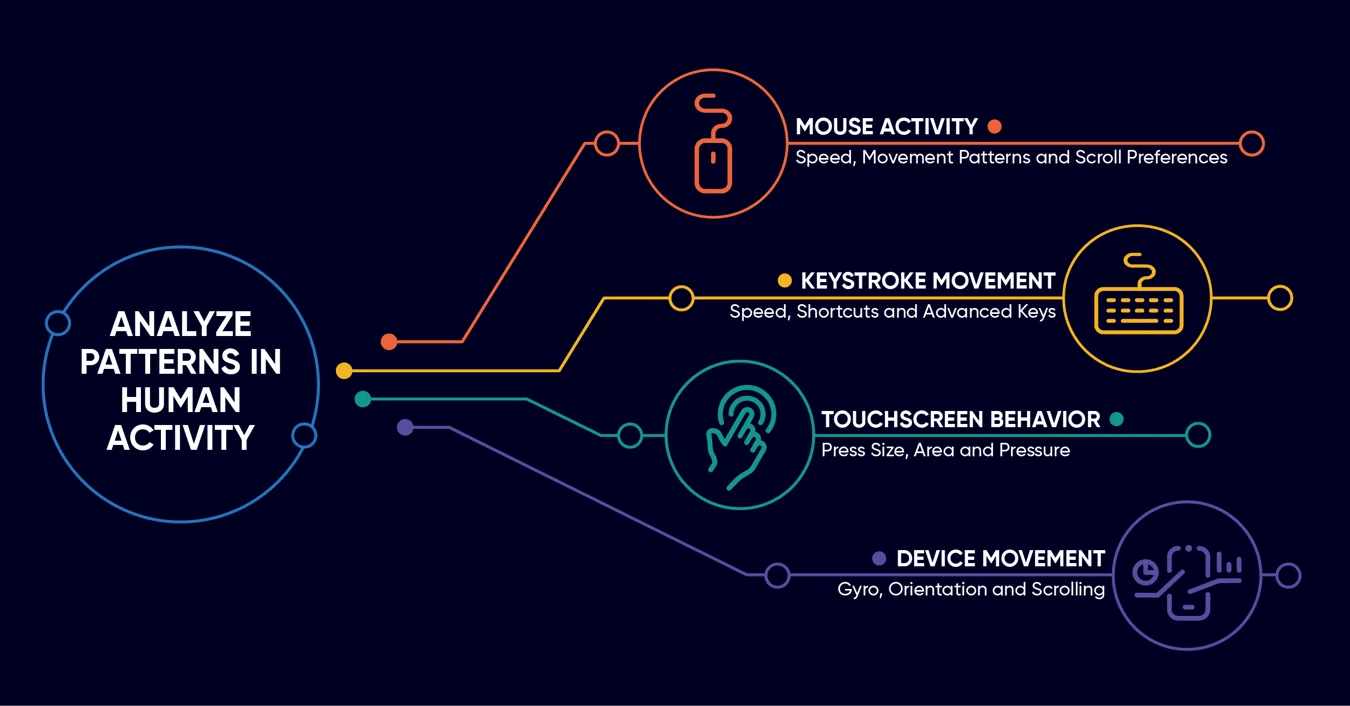
Hình 5.2. Các chỉ số sinh trắc học hành vi được sử dụng trong xác thực định danh; nguồn: BioCatch
6. Những thách thức trong triển khai và vận hành thực tế
Dù mang lại hiệu quả vượt trội, việc vận hành các mô hình ML trong môi trường ngân hàng vẫn đối mặt với những rào cản kỹ thuật và pháp lý nghiêm ngặt.
6.1. Sự mất cân bằng dữ liệu nghiêm trọng
Trong thực tế, số lượng giao dịch gian lận thường chiếm tỷ lệ rất nhỏ, dưới 0,1% tổng tập dữ liệu. Theo nghiên cứu của Dal Pozzolo và cộng sự (2015), sự mất cân bằng này khiến thuật toán dễ ưu tiên lớp đa số (giao dịch hợp lệ), dẫn đến độ chính xác tổng thể (Accuracy) rất cao nhưng khả năng phát hiện gian lận thực tế (Recall) lại rất thấp. Các kỹ sư dữ liệu phải áp dụng kỹ thuật như SMOTE hoặc điều chỉnh hàm mất mát để tối ưu hóa khả năng nhận diện các mẫu thiểu số.
6.2. Kiểm soát tỷ lệ báo động giả
Một thách thức lớn trong nghiệp vụ là việc cân bằng giữa an ninh và trải nghiệm khách hàng. Nếu mô hình quá nhạy, tỷ lệ báo động giả tăng cao sẽ dẫn đến việc chặn giao dịch hợp lệ của người dùng. Điều này không chỉ gây phiền hà mà còn ảnh hưởng trực tiếp đến uy tín của ngân hàng và lòng tin của khách hàng.
6.3. Sự thay đổi đặc tính dữ liệu theo thời gian
Các phương thức tấn công luôn biến đổi để tìm ra kẽ hở mới. Hiện tượng này được gọi là Concept Drift (Gama et al., 2014), khi các đặc tính thống kê của hành vi gian lận thay đổi, khiến mô hình đã huấn luyện bị giảm hiệu suất. Do đó, hệ thống yêu cầu quy trình giám sát (Monitoring) và tái huấn luyện (Retraining) liên tục để thích nghi với các xu hướng gian lận mới.
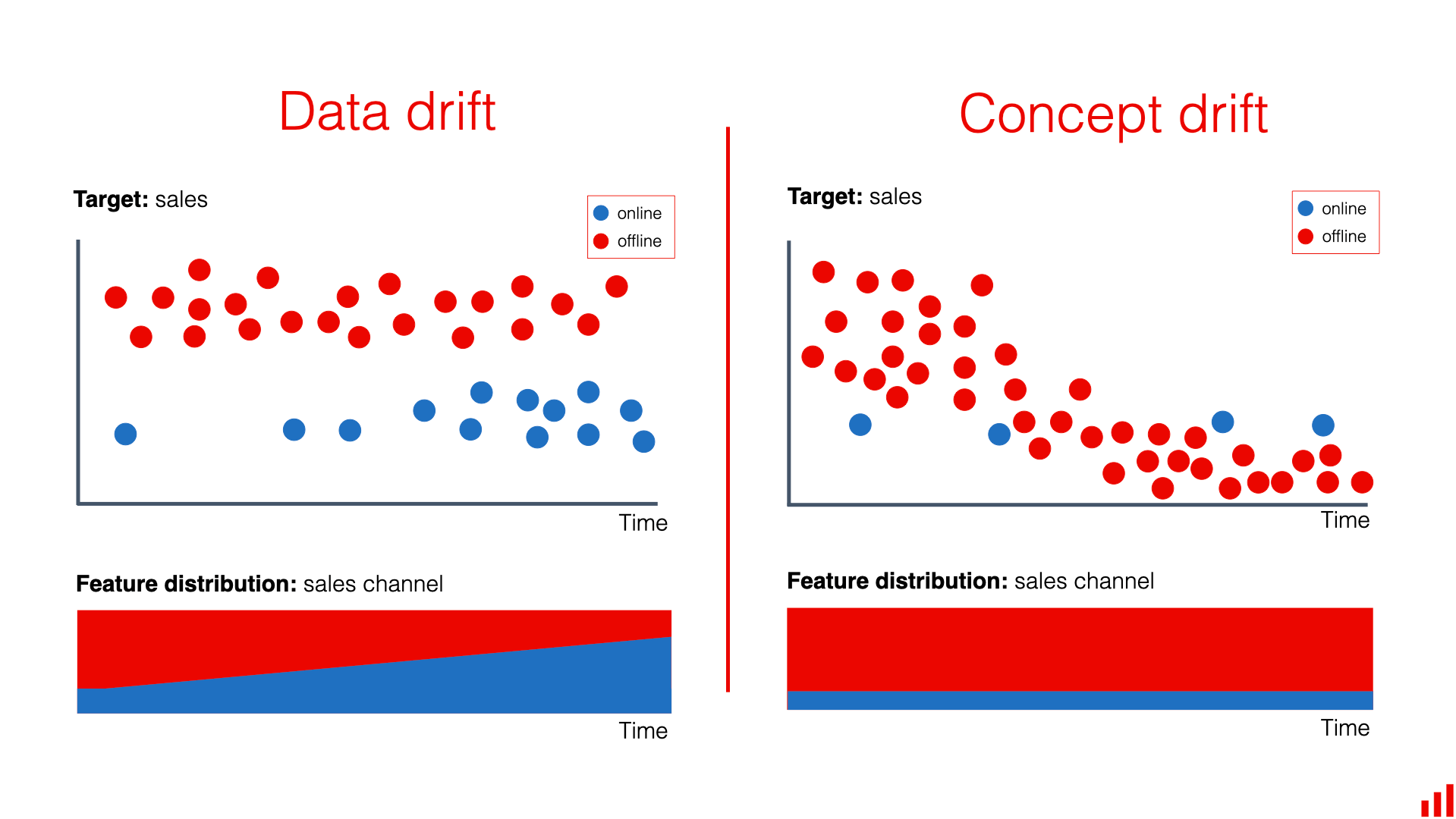
Hình 6.1. Minh họa hiện tượng Concept Drift trong các dòng dữ liệu (data streams); nguồn: Evidently AI
Hình 6.1 minh họa cách các mẫu dữ liệu thay đổi theo thời gian, khiến mô hình cũ không còn duy trì được hiệu suất ban đầu.
6.4. Tuân thủ pháp lý và yêu cầu về tính minh bạch
Tại Việt Nam, việc xử lý dữ liệu cá nhân phải tuân thủ nghiêm ngặt Nghị định 13/2023/NĐ-CP. Mặc dù Nghị định không dùng thuật ngữ "giải trình thuật toán", nhưng việc quy định Quyền phản đối xử lý dữ liệu cho các quyết định tự động (Điều 9, Khoản 8) gián tiếp buộc các ngân hàng phải có khả năng diễn giải logic xử lý.
Bên cạnh đó, các định hướng về quản trị rủi ro trong ngân hàng số của Ngân hàng Nhà nước ngày càng nhấn mạnh việc kiểm soát các quyết định dựa trên thuật toán để đảm bảo quyền lợi khách hàng. Điều này thúc đẩy việc áp dụng AI có thể giải thích (Explainable AI – XAI) nhằm xóa bỏ các "hộp đen" thuật toán, biến các quyết định máy học thành những thông tin có thể kiểm chứng, minh bạch và công bằng.
7. Tương lai của Fraud Detection trong ngân hàng
Công nghệ không bao giờ đứng yên, và những kẻ lừa đảo không còn dùng mánh khóe thủ công nữa. Để ngăn chặn việc này, các ngân hàng đang đặt cược vào những lá chắn mới thông minh hơn. Tương lai không nằm ở việc chạy theo đuôi tội phạm, mà là những hệ thống AI có khả năng tự học, đoán trước rủi ro và hiểu dữ liệu ở một mức độ hoàn toàn mới.
7.1. Generative AI và Dữ liệu mô phỏng
Một trong những bài toán khó nhất khi xây dựng mô hình Machine Learning phát hiện gian lận là: dữ liệu gian lận thật sự thường rất hiếm. Trong thực tế, phần lớn giao dịch đều hợp lệ, còn những trường hợp gian lận chỉ chiếm một tỷ lệ rất nhỏ. Điều này khiến mô hình khó học được đầy đủ các dấu hiệu của hành vi lừa đảo.
Khi không có đủ ví dụ để học, hệ thống AI rất dễ bỏ sót những kiểu gian lận mới hoặc tinh vi hơn. Và đây chính là lúc Generative AI phát huy giá trị. Một trong những hướng tiếp cận nổi bật là sử dụng GANs (Generative Adversarial Networks) để tạo ra các tập dữ liệu mô phỏng có đặc điểm gần giống với dữ liệu gian lận thật. Thay vì phải chờ thêm các vụ gian lận xảy ra trong thực tế, chúng ta có thể chủ động tạo ra nhiều kịch bản gian lận khác nhau để huấn luyện mô hình.
Nhờ vậy, hệ thống phát hiện gian lận của ngân hàng có thể được tập luyện với hàng loạt tình huống giả lập, từ những chiêu trò phổ biến cho đến các gian lận phức tạp. Việc tiếp xúc với nhiều kịch bản như vậy giúp mô hình học được các tín hiệu bất thường tốt hơn, từ đó nâng cao khả năng phát hiện và thích ứng khi triển khai trong môi trường thực tế.
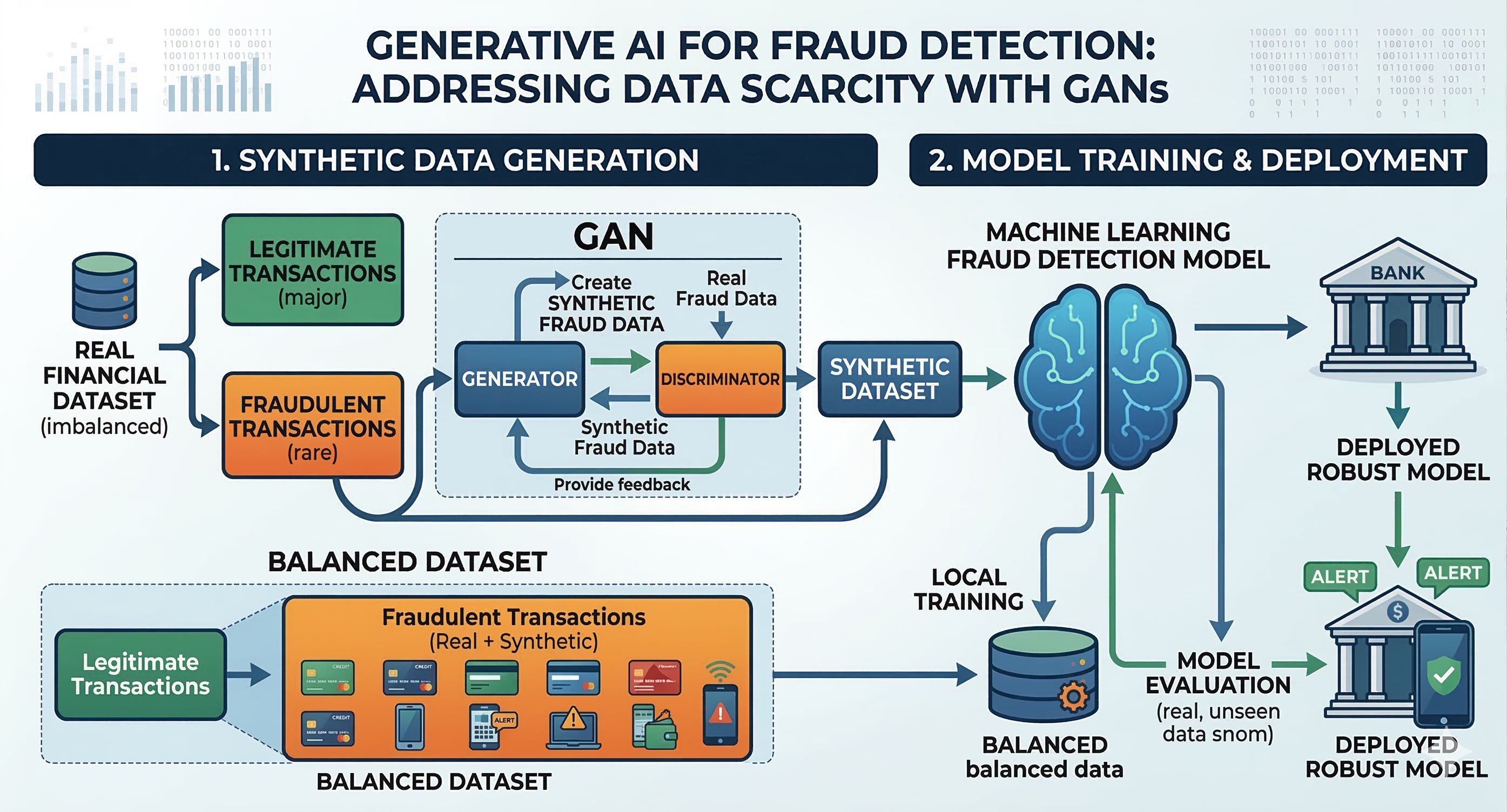
Hình 7.1. Generative AI và Dữ liệu mô phỏng
7.2. Federated Learning
Khi một chiêu trò lừa đảo trót lọt ở ngân hàng này, nó sẽ sớm xuất hiện ở ngân hàng khác. Tuy nhiên, việc các tổ chức tài chính chia sẻ dữ liệu thô của khách hàng cho nhau là vi phạm nghiêm trọng các quy định về quyền riêng tư.
Federated Learning (học tập liên kết) là lời giải hoàn hảo. Các ngân hàng giữ nguyên dữ liệu nhạy cảm ở hệ thống nội bộ, và chỉ chia sẻ các mẫu hành vi gian lận lên một mạng lưới chung. Từ đó cả mạng lưới cùng thông minh lên mà dữ liệu cá nhân của người dùng vẫn được bảo mật.
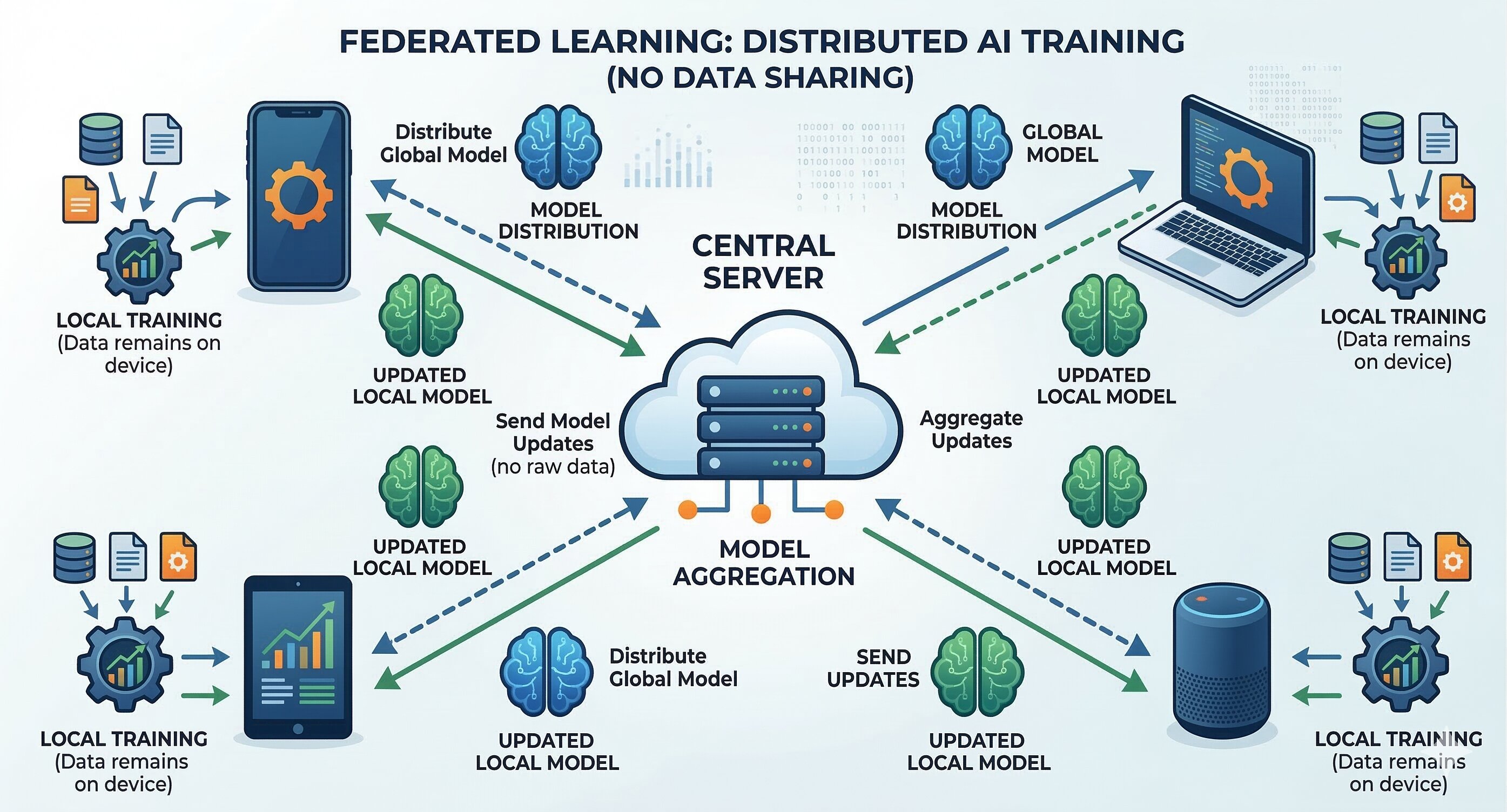
Hình 7.2. Federated Learning
7.3. Sự kết hợp giữa con người và AI
Một trong những hiểu lầm lớn nhất về AI là nó xuất hiện để thay thế con người. Nhưng trong lĩnh vực phát hiện gian lận, sự thật lại hoàn toàn ngược lại. Xu hướng tương lai sẽ là những đội ngũ mà con người và AI cùng làm việc song song với nhau.
Việc phát hiện gian lận hiếm khi là chuyện trắng đen rõ ràng. AI có thể nhanh chóng phát hiện các hành vi đáng ngờ chỉ trong tích tắc, nhưng để kết luận đó có thực sự là gian lận hay không thì vẫn cần đến sự đánh giá của con người. Có những yếu tố như khác biệt văn hóa, bối cảnh lịch sử của khách hàng, hay những trường hợp đặc biệt mà không một thuật toán nào có thể hiểu hết nếu chỉ đứng một mình.
Đây là cách mà hai vai trò này bổ trợ cho nhau:
- AI xử lý ở quy mô lớn: lọc qua hàng triệu sự kiện và nhanh chóng làm nổi bật những trường hợp đáng để điều tra.
- Con người mang lại bối cảnh: không chỉ nhìn vào dữ liệu, mà còn hiểu được ý định, mối quan hệ và những tình huống ngoại lệ mà máy móc chưa hiểu hết.
- Khi kết hợp lại giúp cho hành động nhanh hơn: AI giúp giảm bớt các cảnh báo sai, để các chuyên viên phân tích có thêm thời gian tập trung vào những vụ việc phức tạp thay vì mất thời gian trong các cảnh báo lặp đi lặp lại.
Hãy hình dung AI như một trợ lý giúp phân loại nhanh nhất có thể dành cho các đội chống gian lận, nó ngay lập tức chỉ ra những trường hợp rủi ro, để các chuyên viên dồn sức vào đúng nơi cần thiết nhất.
Cách tiếp cận kết hợp này còn tạo ra một vòng lặp phản hồi liên tục: mỗi vụ gian lận được xác nhận giúp mô hình AI học tốt hơn, và mỗi lần báo động nhầm cũng dạy nó biết nên tránh điều gì trong tương lai. Theo thời gian, cả máy và con người đều trở nên chính xác và hiệu quả hơn.
8. Kết luận
Cuộc chiến chống gian lận tài chính vốn dĩ là một cuộc rượt đuổi không hồi kết. Khi những kẻ lừa đảo ngày càng tinh vi, các ngân hàng không thể mãi phòng thủ bằng những bộ quy tắc cứng nhắc và cũ kỹ. Sự dịch chuyển sang Machine Learning không chỉ là một bước tiến công nghệ, mà đã trở thành vũ khí sống còn giúp các tổ chức tài chính chuyển từ thế bị động sang chủ động dự báo rủi ro. Tất nhiên, việc vận hành AI trong thực tế vẫn còn đó những bài toán khó về cân bằng dữ liệu hay kiểm soát tỷ lệ báo động giả. Thế nhưng, với sự xuất hiện của Generative AI mô phỏng dữ liệu, mạng lưới chia sẻ an toàn Federated Learning, bức tranh bảo mật đang sáng sủa hơn bao giờ hết. Quan trọng nhất, công nghệ tiến lên không phải để loại bỏ chúng ta. Trong tương lai, AI sẽ đóng vai trò là trợ thủ đắc lực, còn con người mới là người quyết định cuối cùng, cùng nhau xây dựng một hệ sinh thái thanh toán an toàn, mượt mà và đáng tin cậy.
Tài liệu tham khảo
- Dal Pozzolo, A., Caelen, O., Waterschoot, R. A., & Bontempi, G. (2015). Learned lessons in credit card fraud detection from a practitioner perspective. Expert Systems with Applications, 42(10), 4928-4941.
- Federal Trade Commission (2025). New FTC data show a big jump in reported losses to fraud to $12.5 billion in 2024. www.ftc.gov
- Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys (CSUR), 46(4), 1-37.
- PayPal. (2021). PayPal Holdings, Inc. 2021 Annual Report. Retrieved from PayPal Investor Relations.
- Visa. (2023). Visa Advanced Authorization: Real-time fraud risk scoring. Retrieved from Visa Newsroom.
- Bolton, R. J., & Hand, D. J. (2002). Statistical fraud detection: A review. Statistical Science, 17(3), 235–255.
- Ngai, E. W. T., Hu, Y., Wong, Y. H., Chen, Y., & Sun, X. (2011). The application of data mining techniques in financial fraud detection. Decision Support Systems, 50(3), 559–569.
- Phua, C., Lee, V., Smith, K., & Gayler, R. (2010). A comprehensive survey of data mining-based fraud detection research. arXiv preprint arXiv:1009.6119.
- Okafor, G., Akhuemonkhan, E., Njoku, C., Gachui, E., Naibe, I., & Diala, A. K. (2025). The future of generative artificial intelligence (AI) in fraud detection analysis. International Journal of Management & Entrepreneurship Research, 7(4), 294–298. https://doi.org/10.51594/ijmer.v7i4.1875
- Fraud Detection Software. (2026, January 6). The future of AI in fraud detection: Trends & risks. https://frauddetectionsoftware.co/blog/future-ai-fraud-detection
Chưa có bình luận nào. Hãy là người đầu tiên!