
1. Introduction
In recent years, AI image generation has become increasingly common in everyday life. With just a short text description, users can create paintings, illustrations, advertising posters, or design concepts in a very short time. This technology is no longer just experimental—it has become a familiar tool for creatives, marketing teams, and digital content creators.
The popularity of AI image generation comes from three main factors. First, increasing computational power enables AI models to process massive amounts of image data. Second, the volume of images on the internet is large enough for AI to learn diverse structures and styles. Third, the way humans create is changing: instead of drawing every detail, people describe an idea, and AI handles the visualization.
The goal of this article is to help readers understand what AI image generation is, what it is used for, and how it works. The article also describes the Stable Diffusion model and explores why it has become popular and widely used in user-driven image generation applications.
2. What Is AI Image Generation?
AI image generation is a branch of artificial intelligence that enables computers to generate entirely new images, based on what they have learned from very large training datasets (from millions to billions of images). The key point to emphasize is: AI does not “copy” existing images. Instead, it learns statistical patterns, visual structures, and relationships between concepts to create new images from scratch.
Unlike traditional drawing or design, where humans directly control each stroke, layer, or tool in software, AI approaches the problem in a completely different way. AI does not understand “drawing” in the human sense, but represents images as numerical matrices that correspond to pixels, colors, lighting, textures, and shapes.

Source: Images generated using ChatGPT and Gemini from the author’s prompts.
When users enter a descriptive request (prompt) (for example: “a futuristic city at sunset, samurai style with mecha robots”), the AI model will:
1. Convert the text into a numerical representation (a vector/embedding) that captures semantic meaning.
2. Based on what it has learned, estimate probabilities of which pixels should appear where, what colors they should have, and how they should look so the image is coherent and matches the description.
3. Repeat this prediction process hundreds or thousands of steps until the complete image gradually emerges.
In other words, AI image generation is a controlled prediction process, where each pixel is not “hand-drawn” but generated based on probability and mathematical constraints.
This image-generation technology belongs to Generative AI, models capable of producing entirely new data rather than only classifying, recognizing, or predicting labels. This differs from traditional AI tasks like face recognition or cat/dog classification, which answer “what is this?” Generative AI answers a much harder question: “Create something new that looks like that.”
At its core, AI image generation still relies on deep neural networks (DNNs). However, unlike CNNs (Convolutional Neural Networks) used for image recognition, modern image generation systems are largely built on Diffusion Models, combined from Transformers, Variational Autoencoder and U-Net.
For example, in models like Stable Diffusion:
-
Text prompts are processed by a Transformer (CLIP text encoder) to create semantic embeddings.
-
Images are represented in latent space through a Variational Autoencoder (VAE).
-
The main generation process is performed by a U-Net—a network that learns to predict and remove Gaussian noise step by step in latent space, conditioned on the prompt embedding.
Here, the model does not learn the classic CNN pipeline of “edges → shapes → objects.” Instead, it learns the probability distribution of image data and how to reverse a noising process:
from random noise → coarse structure → details → final image
The entire process is fundamentally probabilistic sampling, rather than feature extraction for classification like traditional CNNs.
In other words, GenAI does not “look at images to understand them,” but learns how to:
generate images by simulating how an image emerges from noise.
We will explore diffusion and Stable Diffusion’s training and generation process in more depth later in this article.
3. What Is AI Image Generation Used for in Practice?
Over the past few years, AI image generation has rapidly moved beyond research and become a widely used tool across many different fields. What these applications share is the ability to speed up the creative process, reduce experimentation costs, and enable workflows that were previously difficult or almost impossible.
3.1. Art and Content Creation

Source: Images generated using ChatGPT and Gemini from the author’s prompts.
In art, AI is used as an ideation and sketching partner rather than a tool that replaces artists. Artists and content creators can use AI to:
- Quickly generate illustrations for books, comics, games, or videos.
- Sketch early-stage concepts to visualize settings, characters, and color palettes before investing in detailed drawing.
- Experiment with new art styles by blending multiple aesthetics (e.g., combining oil painting, sci-fi, and 3D anime).
In these examples, AI helps artists and creators focus more on the ideas and stories they want to convey, while skipping repetitive steps that often take a lot of time. As a result, content creation can be accelerated many times compared to traditional workflows, and outputs can become far more diverse in style than before.
3.2. Design and Marketing

Source: Images generated using ChatGPT and Gemini from the author’s prompts.
In design and marketing, AI image generation is considered a high-impact productivity tool. Marketing teams can use AI to:
- Quickly create posters and advertising banners with many variations for A/B testing.
- Generate product images in different contexts (studio, outdoor, lifestyle) without real photoshoots.
- Personalize ad visuals for different customer segments, markets, or seasonal campaigns.
Instead of spending days on a single visual concept, AI can generate dozens of options in just minutes—helping businesses make faster and more flexible decisions.
3.3. Digital Content and Social Media

Source: Images generated using ChatGPT and Gemini from the author’s prompts.
For digital content and social media, visuals play a key role in capturing attention. AI supports creators by:
- Generating illustrations for news articles, blogs, or academic writing without spending time searching for images or hiring illustrators.
- Creating preview images (thumbnails) for YouTube, TikTok, or Reels videos with eye-catching styles.
- Personalizing visuals by topic, color tone, or audience.
Example:
All images in this article were generated using AI.
With AI, individual creators or small teams can still produce professional visuals with consistent style—something that previously only large studios could achieve.
3.4. Science and Research

Source: Images generated using ChatGPT and Gemini from the author’s prompts.
In science and research, AI image generation is not aimed at aesthetics, but focuses on data value. Notable applications include:
- Generating synthetic data to augment training datasets for diagnostic models—especially when real data is scarce or sensitive.
- Reducing privacy risks, since generated data is not directly tied to real patients.
In this context, AI helps improve machine learning model quality and indirectly supports diagnosis, rather than replacing doctors.
3.5. The New Role of Humans in the Era of AI Image Generation
The applications above show that AI does not eliminate the role of humans, but changes it. Humans are gradually shifting from directly “drawing every detail” to:
- Setting direction, goals, and intent.
- Writing prompts, choosing styles, and applying constraints.
- Evaluating, editing, and controlling the final output.
AI becomes a tool that amplifies creative capability, while humans remain responsible for the meaning, context, and value of the images being generated.
4. From Prompt to Image: How Does AI Image Generation Happen?
When users enter a prompt (a text description), AI does not generate an image immediately. Instead, the text is first converted into a numerical representation called a vector (or embedding). This vector encodes information about content (what the objects are), style (painting, photo, animation…), emotion, context, and even abstract relationships between concepts.
The important point is: the vector is not an image. It contains no pixels and no specific colors. The vector acts like a “set of directions” or a “compass,” helping AI determine what kind of image to generate, rather than generating the image directly.
This vector is then used to guide the subsequent image generation process: when to emphasize certain details, and when to remove irrelevant elements. To understand that process, we need to look at common image-generation models in Generative AI, especially GANs (Generative Adversarial Networks) and Diffusion Models.
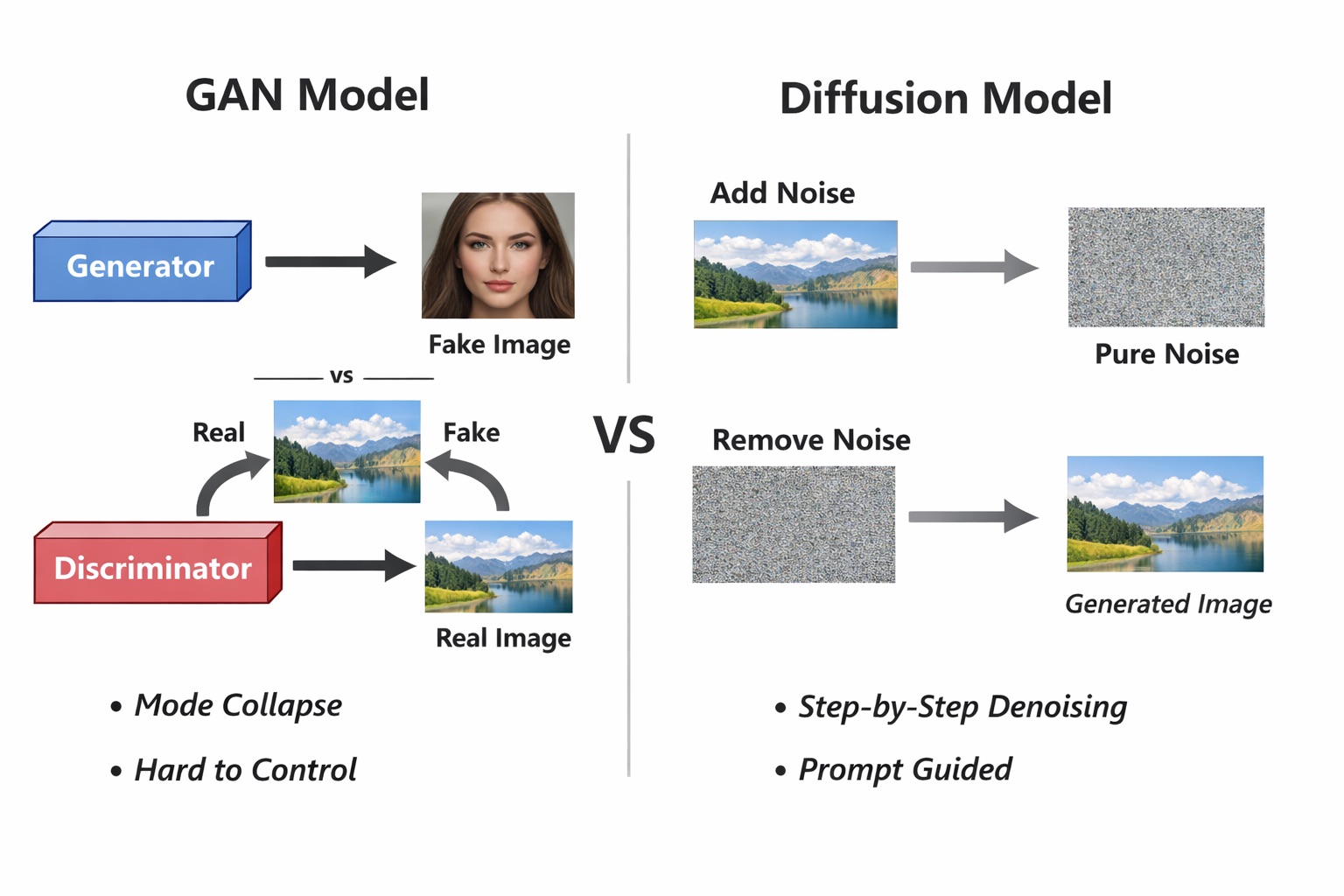
4.1. GANs: The First Generation of AI Image Models
Before diffusion became popular, GANs (Generative Adversarial Networks) dominated AI image generation.
A GAN consists of two neural networks:
- Generator: tries to create fake images that look like real ones.
- Discriminator: tries to distinguish real images from fake images.
These two networks “compete” during training. The generator becomes increasingly good at fooling the discriminator, while the discriminator becomes more demanding. Over time, the generator learns to produce images that closely resemble real data.
Advantages of GANs:
- Fast image generation.
- High quality for certain kinds of data (such as faces).
However, GANs have many limitations:
- Hard to train, prone to instability.
- Often suffer from mode collapse (generating only a few repeated image types).
- Hard to control with long and complex prompts, especially natural language descriptions.
- Difficult to tightly align text and images.
These limitations make GANs less ideal for modern text-to-image systems.
4.2. Diffusion Models: A Counterintuitive but Effective Approach
Diffusion models approach the problem in a very different way—almost “counterintuitively”:
-
Step 1: Add noise (forward process)
- Start from a real image.
- Gradually add Gaussian noise over many steps.
- After enough steps, the image becomes pure random noise.
-
Step 2: Learn to remove noise (reverse process)
- The model is trained to reverse the above process.
- At each step, the AI learns:
If the current image has this much noise, what noise should be removed?
When generating an image, the AI:
- Starts from image of pure noise.
- Step by step removes noise, gradually revealing structure, shapes, and details.
- The prompt (as a vector) continuously steers the denoising direction, so the final image matches the user’s description.
In other words, AI does not draw from a blank canvas, but “sculpts” an image from noise.
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
4.3. Why Do Modern Systems Choose Diffusion Over GANs?
There are several key reasons why diffusion models have become the default choice for modern image generation systems:
1. More stable and easier to train
Diffusion is framed as a noise-prediction task with a clear and stable objective. This makes training less risky than GANs.
2. Better prompt controllability
Prompts (semantic vectors) can be injected into every denoising step, helping AI follow long, detailed, and abstract descriptions. This is something GANs do very poorly.
3. Higher quality and greater diversity
Diffusion is less prone to mode collapse (the generated images are repeatitive and near-identical), enabling more diverse images even for rare or novel prompts.
4. Flexible extensibility
Diffusion combines easily with:
- Text (text-to-image)
- Images (image-to-image)
- Masks (inpainting, outpainting)
- Structural control (pose, depth, sketch)
This makes diffusion a general platform for visual creativity, not just a standalone image generator.
In short, in AI image generation, the prompt plays the role of an architect who drafts the blueprint, and diffusion acts as the builder who constructs the image based on that blueprint.
In modern AI image generation systems:
- Prompt → embedding: transforms human ideas into a numerical language.
- Embedding → guidance: determines what content and style should be preserved.
- Diffusion → image creation: starts from noise and denoises step by step until an image appears.
AI does not “understand” images the way humans do, but through mathematics, probability, and large-scale data, it can produce outputs that feel intuitive, coherent, and even artistic.
5. Latent Diffusion (Stable Diffusion)
Although the Diffusion Model architecture is more stable and produces higher-quality images than GANs, “vanilla” Diffusion has a major drawback: the entire training and inference process must run directly in pixel space.
Specifically, for an image of size N × M, the model must process all N × M pixels at every noising and denoising step. This leads to:
- Very high computational cost
- Long training time
- Slow inference due to the need for many denoising steps
Imagine adding and removing noise for billions of images, with each image going through hundreds of diffusion steps—this is almost infeasible if done directly on pixels.
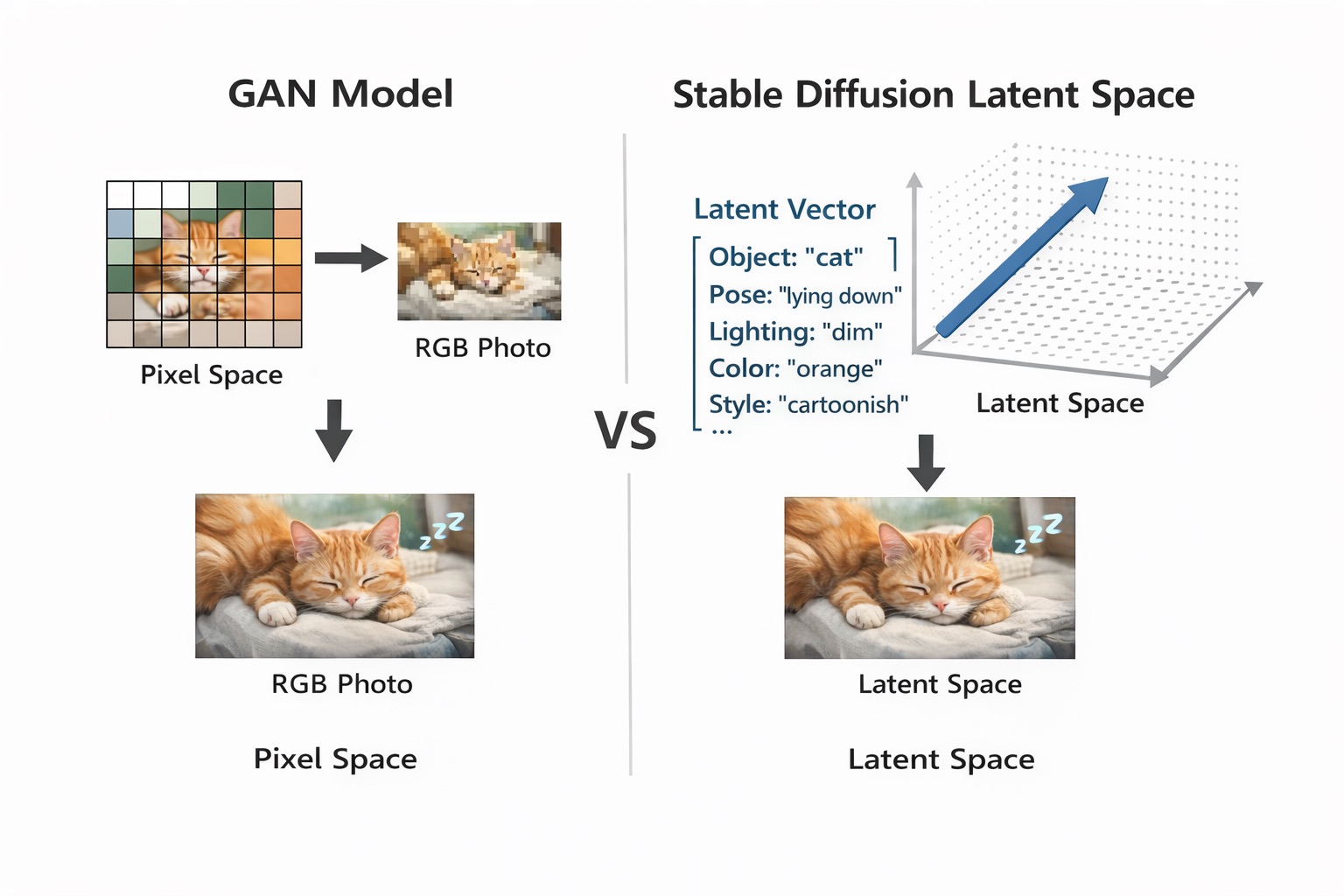
5.1. Latent Space and the Core Idea of Stable Diffusion
Stable Diffusion introduced a breakthrough solution: move the entire diffusion process into a smaller space called latent space.
The word latent comes from the Latin latere, meaning hidden—a representation that is not as visually explicit as pixels but still contains the essential information of an image.
Instead of representing an image as a pixel matrix N × M × 3 (RGB), Stable Diffusion represents it as a vector or tensor in an N-dimensional space, where each dimension encodes more abstract information about the image content.
Example: a sleeping cat image.
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
-
In pixel space
An image is represented by RGB values (red, green, blue):
[ [ [R,G,B], [R,G,B], ... ], [ [R,G,B], [R,G,B], ... ], ... ]Even small changes in lighting, color, or texture can alter thousands of pixels.
-
In latent space
Conceptually, the same image might be represented as:
[ object = "cat", pose = "lying down", lighting = "dim", dominant_color = "orange", style = "cartoon", ... ]
Each factor corresponds to one or more dimensions in latent space. This space is more semantic than pixel space.
Moving to latent space brings important advantages:
- Dramatically reduces data size compared to pixel space
- Preserves the structure and meaning of the image content
- Easier to compare and interpolate between images with similar content
- Allows diffusion to operate far more efficiently
As a result, training on billions of images becomes feasible in both time and resources.
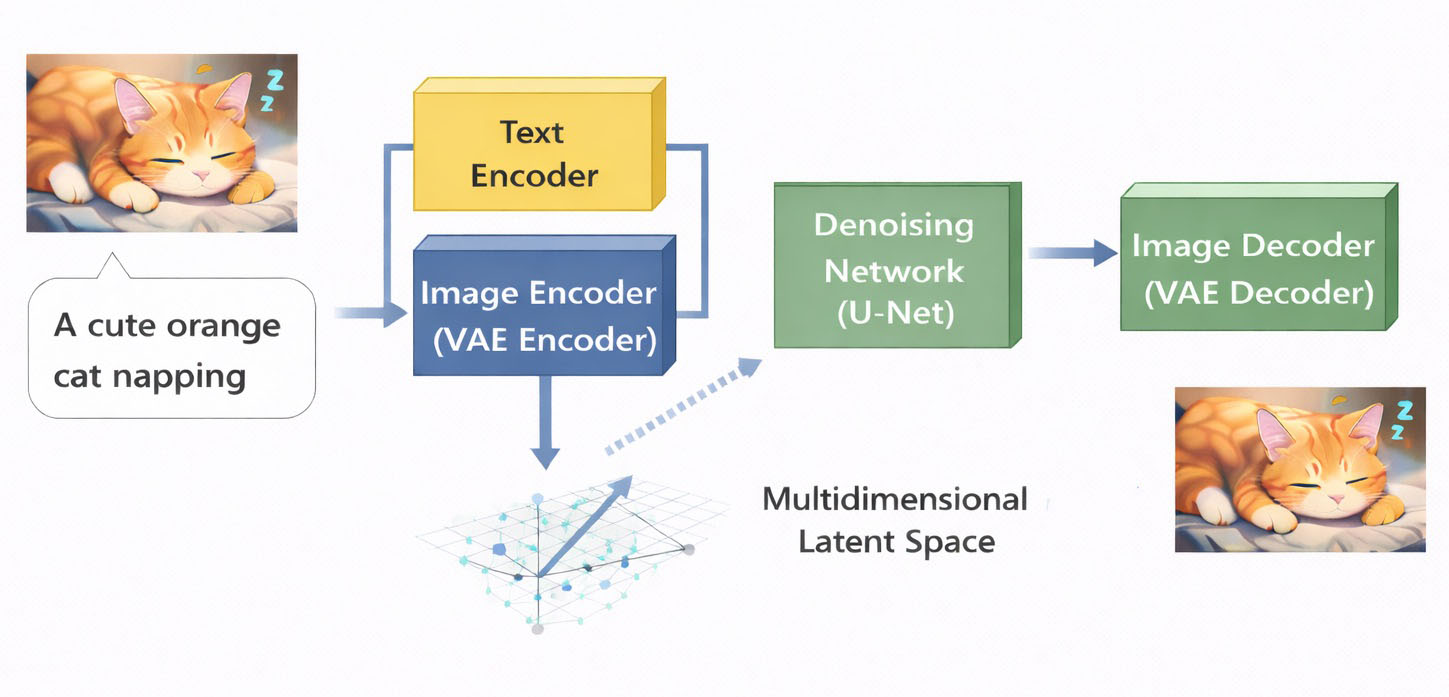
5.2. Variational Autoencoder (VAE)
To work in latent space, Stable Diffusion needs an additional component: the Variational Autoencoder (VAE).
The VAE acts as a bridge between pixel space and latent space:
- Image Encoder (VAE Encoder): converts pixel images to latent
- Image Decoder (VAE Decoder): converts latent to pixel images
Therefore, a full Stable Diffusion system includes:
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
- Text Encoder: converts text prompts into semantic embeddings
- Image Encoder (VAE Encoder): compresses images into latent space
- Denoising Network (U-Net): learns to denoise in latent space
- Image Decoder (VAE Decoder): decodes latent back into the final image
5.3. Stable Diffusion Training Process
Training proceeds as follows:
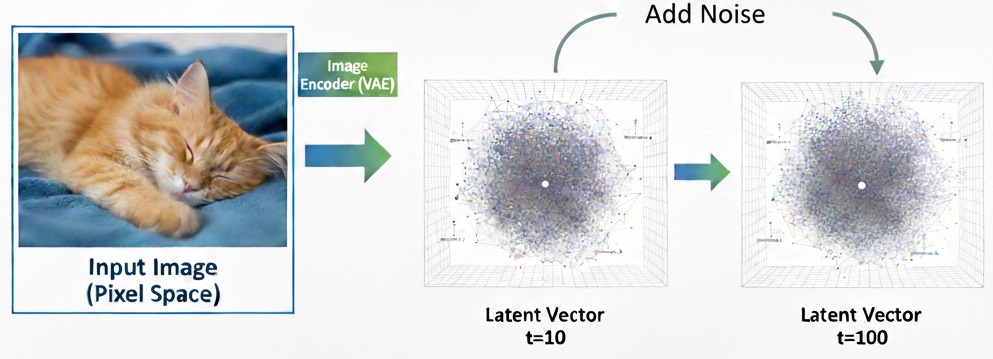
-
Encode images into latent space
For each training image $x_0$:
$$ z_0 = \text{VAE}_{\text{Encoder}}(x_0) $$
Where:- $\text{VAE}_{\text{Encoder}}$: the encoder part of the Variational Autoencoder
- $z_0$: the image latent representation
-
Add noise in latent space
Gaussian noise is gradually added to the latent over time $t$:
$$ z_t = \sqrt{\alpha_t}\, z_0 + \sqrt{1 - \alpha_t}\, \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, I) $$
Where:- $z_t$: latent at time ( t )
- $\alpha_t \in (0,1)$: coefficient controlling how much information is preserved
- $\varepsilon$: random Gaussian noise
- $\mathcal{N}(0, I)$: standard normal distribution with mean 0 and identity covariance matrix $I$
As $t$ increases, $z_t$ contains more and more noise.
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
The goal is that at the final step, the latent is almost pure noise. No learning is needed in this phase because we only add controlled noise.
-
Encode the text description $p$ using the text encoder:
$$ c = \text{Encoder}(p) $$
Where:- $p$: input prompt (text)
- $c$: semantic embedding of the prompt
- $\text{Encoder}$: the text encoder (often CLIP)
-
Train the U-Net to predict the noise $\varepsilon$ that was added:
$$ \hat{\varepsilon} = \varepsilon_\theta(z_t, t, c) \\\\[2ex] \mathcal{L}(\theta) = \mathbb{E}_{z_0, \varepsilon, t} \left[ \| \varepsilon - \varepsilon_\theta(z_t, t, c) \|^2 \right] $$
Where:- $\varepsilon_\theta$: the U-Net model with parameters $\theta$
- $\hat{\varepsilon}$: noise predicted by the model
- Inputs include latent $z_t$, timestep $t$, and text condition $c$
- $\mathcal{L}(\theta)$: the loss function
- $\| \cdot \|^2$: squared L2 norm
- $\mathbb{E}_{z_0, \varepsilon, t}$: Avarage of loss over randomly sampled latent $z_t$, noise $\varepsilon$ và timestep $t$
Goal: make the U-Net’s predicted noise as close as possible to the true $\varepsilon$.
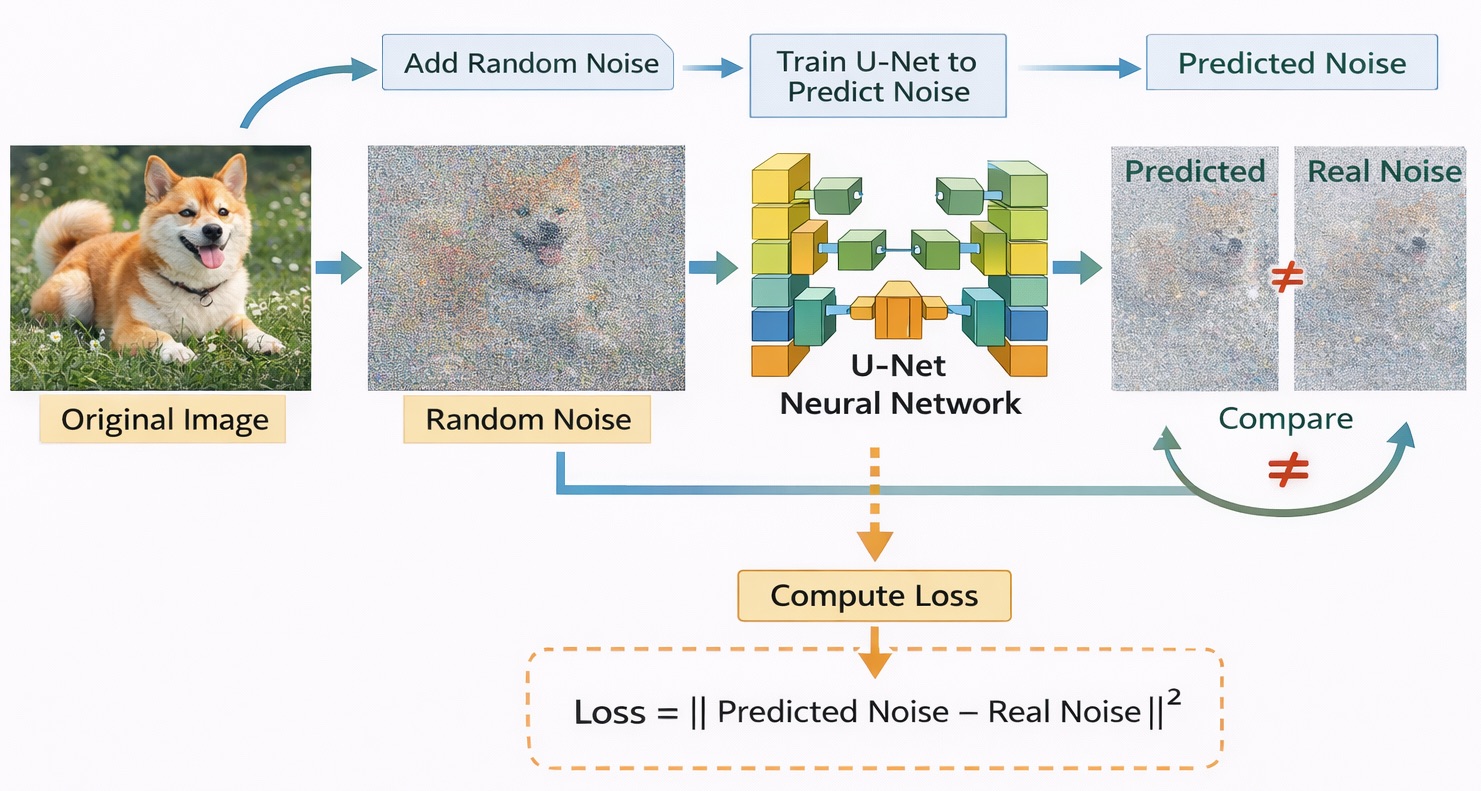
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
- Repeat over a large dataset
This process is repeated across billions of images, allowing the model to learn how to:- Capture image structure in latent space
- Link text embeddings with visual features
5.4. Inference Process
When generating images, Stable Diffusion does not require an input image.
-
Initialize noise
Start from random latent noise:
$$ z_t \sim \mathcal{N}(0, I) $$ -
Denoise step by step
At each step $t → t−1$:
$$ z_{t-1} \;=\; z_t \;-\; \gamma_t\,\varepsilon_\theta(z_t, t, c) $$
Where:- $z_t$: latent at time step $t$ (still noisy)
- $z_{t-1}$: latent after one denoising step
- $\varepsilon_\theta(\cdot)$: the U-Net (parameters $\theta$) used to predict the noise present in $z_t$
- $t$: the current diffusion timestep
- $c$: conditioning embedding from the text prompt (produced by the text encoder)
- $\gamma_t$: step size at time $t$ (derived from the noise schedule), controlling how much noise is removed and how fast the process converges to the final image
This step gradually removes noise and restores image structure guided by the user’s prompt. The process is repeated multiple times (20–50 steps) until a clean latent $z_0$ is obtained.
- Decode latent into an image
The final latent is decoded into an image:
$$ \hat{x}_0 = \text{VAE}_{\text{Decoder}}(z_0) $$
Where:- $\text{VAE}_{\text{Decoder}}$: the VAE decoder
- $\hat{x}_0$: the output image
This is the final image that the user sees.
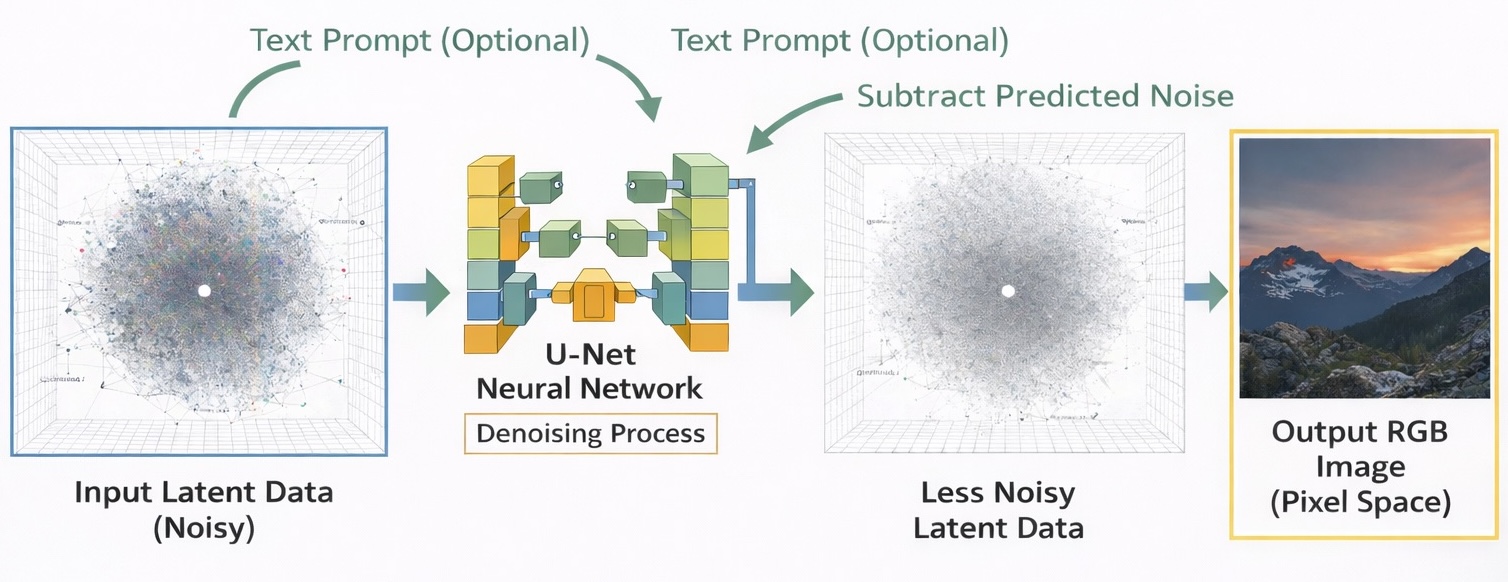
Source: Images generated using ChatGPT and Gemini from the author’s prompts.
The process can be summarized as:
- Training:
$$ x_0 \xrightarrow{E_{\text{VAE}}} z_0 \xrightarrow{+\varepsilon} z_t \xrightarrow{\varepsilon_\theta} \hat{\varepsilon} $$ - Inference:
$$ z_T \xrightarrow{\text{denoise}} z_0 \xrightarrow{D_{\text{VAE}}} \hat{x}_0 $$
In short, Stable Diffusion works by:
- Compressing images into latent space using a VAE
- Running diffusion in latent space instead of pixel space
- Using a U-Net to learn conditional denoising guided by text
- Decoding the latent into the final image
This approach makes diffusion practical, fast, and scalable, forming the foundation of most modern image generation systems today.
5.5. The Role of Attention in Stable Diffusion
Today, with the Attention mechanism, Stable Diffusion not only “denoises” but can also:
- Understand relationships between words in the prompt
- Link each region of the image to specific text concepts
- Control composition, style, and details with fine granularity
The key to this is Cross-Attention.
In each U-Net block, the latent feature map interacts with text embeddings through attention:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V $$
Where:
- $Q$ (Query): features from the latent (image)
- $K, V$ (Key, Value): embeddings from the text prompt
- $d$: embedding dimension
Meaning:
Each region of the image “asks” the prompt: what should be drawn here?
As a result:
- The word “cat” affects the cat’s shape
- The word “orange” affects color
- The word “cartoon” affects the overall style
This is why changing the prompt can completely change the image content.
5.6. Why Is Stable Diffusion Widely Used?
Three main factors explain why Stable Diffusion is so widely adopted:
-
Smaller latent space
Diffusion runs in latent64×64×4instead of pixel512×512×3, which:- Reduces compute cost
- Speeds up training and inference
- Enables running on consumer-grade GPUs
-
Attention enables semantic control
Attention turns the model from a random image generator into a system that can:- Generate images from text (text-to-image)
- Edit images with text instructions
-
Modular architecture
Stable Diffusion consists of separable modules:- Text encoder (CLIP)
- VAE
- U-Net
This makes it possible to:
- Swap the U-Net → improve quality
- Swap the VAE → improve sharpness
- Fine-tune parts of the system (LoRA, DreamBooth, ControlNet)
Most importantly, users can do these without retraining the entire system.
6. Conclusion: Potential and Limitations of AI Image Generation
AI image generation shows that artificial intelligence is not limited to analyzing data—it has taken a major step forward: creating new content. Models like GANs and diffusion (especially Stable Diffusion) demonstrate that machine learning can capture complex visual structures and recreate them in entirely new ways.
However, it is important to emphasize:
- AI does not have aesthetic consciousness.
- AI does not have emotions or personal experiences.
- AI does not “understand” art the way humans do.
What AI can do is learn statistical patterns from large-scale data and generate images based on probability. Therefore, output quality depends heavily on:
- The scale and diversity of training data
- Model architecture (GAN, diffusion, Transformer, etc.)
- How latent space is represented
- Prompt quality and the user’s control skills
In other words, AI is a tool that amplifies human creativity, not an independent source of creativity.
In practice, the greatest value of AI image generation is not in “replacing artists,” but in enabling the ability to:
- Speed up the creative process
- Reduce image production costs
- Support rapid idea experimentation
- Expand expressive capability for non-designers
Designers can create concepts in minutes instead of hours. Marketers can generate dozens of creative variants for A/B testing. Everyday users can turn ideas into visuals without drawing skills.
The future of AI image generation will likely move toward:
- Stronger personalization for each user
- Better fine-grained control (pose, layout, lighting, style)
- Deeper multimodal integration (text + image + video + 3D)
- Direct integration into traditional creative tools
From a legal perspective, there are ongoing controversies surrounding the copyright status of AI-generated images, as well as potential copyright infringement arising from the use of online images to train AI models. To address these issues, copyright laws and related legal frameworks need to be updated in order to protect original creators and clearly define the boundary between AI-generated art and human creativity.
Finally, just as cameras and Photoshop once transformed visual arts, AI image generation should be seen as a new technological leap. It does not replace human creativity, but opens a wider creative space—where humans and AI collaborate to produce entirely new forms of expression.
7. References
- Ho et al., Denoising Diffusion Probabilistic Models, NeurIPS 2020
- Song et al., Denoising Diffusion Implicit Models, ICLR 2021
- Rombach et al., High-Resolution Image Synthesis with Latent Diffusion Models, CVPR 2022
Chưa có bình luận nào. Hãy là người đầu tiên!